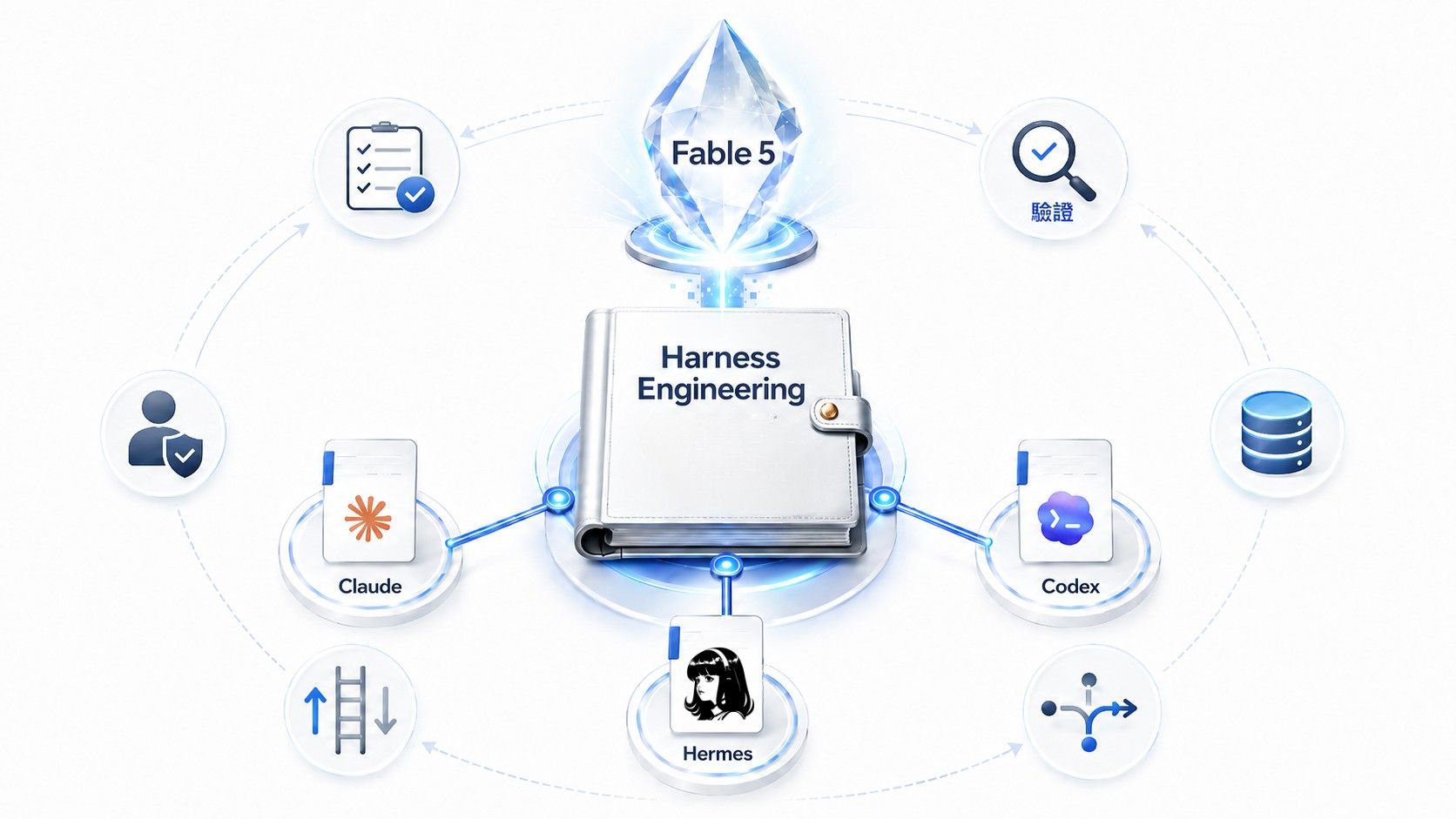
Fable 5 駕馭工程 Harness Engineering 實戰提示詞:強化 AI 大腦
2026 年 7 月 Claude Code 帳號多了一個選項 Fable 5,Anthropic 目前最強的模型,現在到 7/7,訂閱方案可以撥最多每週用量上限的一半去跑 Fable 5,不用另外付錢,用超過就得靠 usage credits 額外付錢。
7/7 後 Fable 5 就整個被移出訂閱額度,之後每次用它都得花 usage credits,也就是方案之外另外掏錢。
大部分人拿到 Fable 5 的第一反應,是丟一個最難的題目給它,解完,爽一次,結束。
但你真正應該做的事:不讓 Fable 5 寫任何一行產品程式碼,用一份設計過的提示詞,讓它把自己的判斷力寫成制度檔案,交接給之後每天陪我工作的弱模型,這件事叫駕馭工程(Harness Engineering),這篇文章會把那份 Fable 5 提示詞全文公開。
你會拿到三樣東西:這份提示詞的設計邏輯、可以直接複製的提示詞全文,以及 Fable 5 實際跑完一輪的結果與踩坑,就算你沒有 Fable 5,換成手上最強的模型一樣能跑。
Fable 5 只有一次機會,為什麼不拿去寫 code?
因為寫 code 是一次性產出,立制度是複利資產,Fable 5 的額度花在後者,報酬率高一個數量級。
一次性產出 vs 複利制度:Fable 5 的 token 花在哪才划算?
你可能會想:Fable 5 寫 code 品質最好,不拿來寫最難的 code 很浪費吧?
問題是那段 code 只服務一個功能,而且 Sonnet 這級的模型其實也寫得出來,只是你要多盯一點。
但「什麼時候該停下來問人」「怎麼判斷方向錯了該換路」「驗收條件怎麼設計」這種判斷,弱模型自己生不出來,這才是 Fable 5 獨有的價值,把它寫成檔案,之後幾百個弱模型 session 全部受益。
貴模型解 1 題,便宜模型抄 49 題是什麼意思?
這是駕馭工程裡省額度的核心手段,也寫進了 Fable 5 這次產出的模型調度守則。
遇到 50 個同類問題,不要讓貴模型從頭做到尾,讓它把第 1 題解透,把解法寫成明確步驟,剩下 49 題降級給便宜模型批次套用,最後用全域搜尋做二次驗證,不信任執行者自己回報。
Fable 5 的額度是預算,判斷力才是你真正在買的東西,把判斷力固化下來,額度就從消耗品變成投資。

駕馭工程 Harness Engineering 是什麼?跟提示工程差在哪?
駕馭工程(Harness Engineering)是把高階模型的判斷力,轉成制度檔案與交辦規則,讓之後每一個較弱模型的 session 都能沿用的工程方法,它優化的不是單次回答,是你跟 AI 協作的整個作業系統。
提示工程管一次對話,駕馭工程管之後每一次?
這就是兩者的分界線。
提示工程(Prompt Engineering)解決的是「這一次怎麼問得更好」,你花心思寫的提示詞,對話結束就蒸發了,下一個 session 從零開始。
駕馭工程解決的是「以後每一次都自動變好」,產出的不是一段話,是一組檔案:指令檔(CLAUDE.md、AGENTS.md 這類每次對話自動載入的規則)、判斷準則、交辦範本、踩坑帳本,AI 每開一個新 session 都會讀到。
我之前在〈Agent Harness Engineering 編排工程〉那篇談過這個概念的產業背景,這篇是我拿 Fable 5 完整跑一輪的實戰紀錄。
為什麼弱模型需要制度,而不是更長的提示詞?
因為弱模型缺的不是資訊,是判斷力,而判斷力沒辦法用一段提示詞補,只能用具體的判準與範例外化給它。
舉個例:你跟 AI 說「做完要驗證」,弱模型會點頭,然後照樣跟你說「已完成」但什麼都沒驗。
但如果制度檔寫的是:說完成之前,必須貼出一條證據,測試輸出、curl 回應、或檔案回讀比對,貼不出來就只能說「已修改但無法驗證」,弱模型就有了可以逐條對照的行為規格,這才叫可執行。
抽象要求等於沒寫,這是駕馭工程的第一原則,也是等一下你會在提示詞裡反覆看到的設計。
怎麼給 Fable 5 下指令?完整提示詞直接公開
下面就是我實際貼給 Fable 5 的完整提示詞,一字不改,你可以直接複製使用。
這份 Fable 5 提示詞的設計邏輯是什麼?
整份提示詞只圍繞一個目標:讓最貴的模型交出可以留下來的東西,所以每一段都在防一種浪費。
任務段先把定位釘死:立制度,不做日常任務,讀者是弱模型,抽象要求等於沒寫。
核心架構原則防規則漂移:一份正本,三個薄索引,任何規則只有一個出處。
作業規則防額度浪費:指揮官不下場、隨做隨寫、先查證再動筆。
交付清單把產出排成 A 到 G 的價值順序,隨時中斷都有完整交付。
收尾強制對抗審查與回讀驗證;誠實條款逼它承認查不到的事,不准編造。
Fable 5 提示詞全文(複製即用)
- 任務
這是我這輩子唯一一次使用 Fable 5 的機會。這個 session 結束後,我的日常會由較小的模型
(Sonnet、Haiku、以及 Codex / Hermes 上的對應弱模型)長期運作。
而且我不是只用一個工具:我同時使用 Claude、ChatGPT Codex、Hermes Agent 三個 agent。
它們共用同一個我、同一批專案、同一套判斷力,但各自有不同的指令檔、記憶機制與能力。
你的任務只有一個:
把你的判斷力轉成「一份共用正本 + 三個薄索引」的制度,讓三個 harness 上每一個較弱模型的
session 都因此變強,而且不會互相漂移。用這個 session 立制度,不要拿去執行日常任務。
你的讀者是三個平台上的弱模型:規則要具體、可執行、有判準與範例,抽象要求等於沒寫;
所有產出須在 Sonnet 等級(以及 Codex / Hermes 的對應弱模型)跑得動,不得依賴只有強模型才懂的默契。
注意:某些請求會被安全機制自動導向到 Opus 4.8,你未必總會察覺,所以別把價值綁在特定型號上,
要綁在「把高階判斷轉成便宜模型、且跨三個 harness 都能長期沿用的制度」上。
Fable 5 的額度是稀缺的,當預算來管理。
- 核心架構原則(凌駕全部)
單一正本,禁止在三個 harness 各寫一份。
制度內容一律寫進「共用正本目錄」(優先沿用我既有的 ~/.agents/ 那套 symlink 正本邏輯;
若不存在就建 ~/.agents/institution/,並在回報中說明你的選址理由)。
三個 harness 各自的指令檔(Claude=CLAUDE.md、Codex=AGENTS.md、Hermes=其對應檔,實際檔名先查證)
只放「路由到正本」的薄索引,NEVER 塞長內容、NEVER 各自複製一份規則。
任何規則只有一個 source of truth;三份索引指向同一份正本。
- 作業規則
0. 先撈舊記憶再立新制度。
在動任何產出前,盤點並匯出三個 harness 各自的既有記憶與指令:
- Claude:CLAUDE.md、記憶目錄 / MEMORY.md、已存的 lessons、可用 skill 與 subagent。
- Codex:AGENTS.md 及其記憶 / 設定機制(查證實際檔名與位置)。
- Hermes:其指令檔與記憶機制(查證;查不到就標「待使用者填寫」)。
把三邊記憶去重、標出互相矛盾處,整併成共用正本的初始素材。
矛盾處不要自己裁決,列成清單在開場問題裡問我(併入下方最多五題)。
1. 先盤點環境再產出。
對三個 harness 各查:指令檔路徑、可用 subagent / 平行機制、當前實際可用的模型與 effort 參數、
MCP、skill、記憶機制、能不能顯式指定 model。做成一張三欄對照表。
盤點完先回報「查到什麼/假設什麼/查不到什麼」,再開始產出。
開場問題最多五題(含第 0 步的記憶矛盾),之後自主作業不再停等。
2. 指揮官不下場,以省額度。
大量讀取、掃 repo、查網頁、批次改檔、驗證,一律派便宜 subagent(在支援的 harness 上)或
標記為「應由弱模型執行」;主對話只進結論。高階主線只花在「換便宜模型就掉品質」的判斷上。
Codex / Hermes 若無 subagent 機制,改用「單獨的低成本 session + 明確交辦包」達成同樣分工,並在守則裡寫明。
3. 價值排序、隨做隨寫。每完成一項立刻存進正本再做下一項;隨時可能中斷,存檔的就是全部。
4. 改既有檔前先備份。新內容寫新檔;三個 harness 的索引檔只放路由,不塞長內容。
5. 型號與參數先查證,絕不憑記憶填。查得到寫實際值,查不到寫「待使用者填寫」並在回報中標出。
三個 harness 的可用型號各查各的,不要拿 Claude 的型號套到 Codex / Hermes。
6. 核心常載檔有上限:每個 harness 的索引檔本體 ≤150 行且只當路由;
共用正本裡的常載檔合計 ≤500 行;其餘做成按需引用檔。超過就精簡或拆分。
7. 若時間窗口允許,可跨 2–3 個 session 完成,每段之間派 fresh-context subagent 驗證再續,
不賭不能中斷的長 session。
- 交付清單(全部寫進共用正本,按價值排序)
A. 快速診斷(先寫,供後面引用):
三個 harness「最漏 token、最易失焦、最易出錯」的前三名,各附一個弱模型能照做的具體修法。
若某問題三家共通就合併寫,若是某 harness 獨有就標明是哪一家。
B. 三個索引檔 + 共用正本骨架:
建立共用正本目錄結構;改寫 Claude 的 CLAUDE.md、Codex 的 AGENTS.md、Hermes 的指令檔,
三者都改成「薄索引 → 指向正本」,收斂重複、刪過時,套「弱模型明確、強模型留白」,守規則 6 上限。
明確標出:哪些規則是三家共用(放正本)、哪些是單一 harness 專屬(放該 harness 索引的專屬區塊)。
C. 模型調度守則(正本內獨立檔):
指揮官不下場;任務交辦三要素(目標與動機、驗收條件、回報格式);
顯式指定 model 與 effort(依規則 5 查證後的實際型號,三個 harness 各一欄);
回報合約(subagent / 低成本 session 只回結論與「檔案:行號」,長產物存檔後傳路徑);
升降級路徑(弱模型錯一次升級、中階同一子任務連錯兩次帶完整失敗軌跡升級、
解出模式降回便宜模型批次套用、同一件事最多重試兩輪);
驗證不自驗(派 fresh-context agent:檔案 read-back、程式碼測試或實跑、高風險判斷加第二意見或多答案評審擇優);
跨 harness 分工:什麼任務適合放哪個 harness(依其 sandbox / 檔案存取 / 型號能力),查證後填。
D. 判斷力外化(正本內獨立檔,harness 中立):
把高階判斷寫成弱模型可執行的 rubric 與 checklist,每條附一正例一反例。
至少涵蓋:何時升級模型、何時算真的完成、何時停下來問使用者、
什麼訊號代表方向錯該換路而非重試、品質底線怎麼驗。
這份必須三個 harness 都能照用,不得綁定任一平台的專屬語法。
E. 任務交辦 prompt 範本(正本內,harness 中立):
含驗收條件與回報格式的填空,任務型態各一份:搜尋、實作、重構、研究、審查。
每份標明「在有 subagent 的 harness 怎麼派、在沒有的 harness 怎麼開低成本 session 交辦」。
F. 維護協議(含跨 harness 同步):
哪些檔弱模型可自行改、哪些動前先問使用者;
踩雷教訓寫回哪個檔與格式;累積多長要精簡;
關鍵新增:三個 harness 的記憶如何回寫到同一份正本(避免再度漂移),
以及每個 harness 的索引檔如何驗證仍指向正本、沒有偷偷長出重複內容。
G. 給未來 session 的信:
三件我沒問但你認為最重要的事;這套三 harness 制度最可能的退化方式與預防法
(尤其「三份索引漂移」與「某 harness 記憶沒回寫正本」);
誠實列出你這次哪幾份產出信心最低、為什麼。
- 收尾(必做)
1. 派 fresh-context subagent 對抗審查全部產出:規則互相打架、三個索引檔是否真的都只路由不重複、
路徑或工具名錯誤、型號是否為查證後的實際值(且沒把某 harness 型號誤植到另一家)、
弱模型會誤讀的模糊句。修完為止。
2. read-back 驗證每個檔(正本 + 三個索引)確實建立、內容完整、索引確實指得到正本。
3. 給我一頁總結:改了什麼、為什麼、三個 harness 明天各自怎麼開始用。
4. context 或額度快用完:立即停止產出,先完成收尾 1–3,未完成項寫進 G 交接。
- 誠實條款
拆解、驗證、多樣本評審補得了執行品質;模糊題與品味判斷補不了,
遇到就寫明處理方式(升級模型、外部第二意見、或明說做不到)。
不確定就查,查不到標註不編造:特別是三個 harness 各自「當前可用的型號與參數」、
「是否支援 subagent / 顯式指定 model」、「記憶機制實際檔名與位置」、
以及「被導向到 Opus 4.8 的請求是否消耗此窗口額度」這類事,
查不到就寫「未確認,建議到對應平台的 usage / 設定實測」。沒有 Fable 5 怎麼辦?要改哪三個地方?
第一,把提示詞裡的 Fable 5 換成你手上最強的模型,Opus、GPT-5.x 最高推理強度都行,駕馭工程的價值來自制度,不是特定型號,提示詞裡那句「別把價值綁在特定型號上」就是為這個寫的。
第二,工具名單換成你自己的,你只用一個 AI 工具,就把「三個 harness」改成一個,核心架構原則簡化成「指令檔只放薄索引,長內容抽成引用檔」,一樣成立。
第三,正本目錄路徑按你的環境調整,提示詞裡的 ~/.agents/ 是我機器上既有的共用目錄,你沒有的話,AI 會照提示詞指示自己建一個並回報選址理由,不用你先準備。
Fable 5 實際跑出什麼?六步全紀錄
Fable 5 收到提示詞後跑了六步:盤點環境、掃描歷史、立正本、建薄索引、對抗審查、回讀驗證,全程只問了我一輪共四個問題,之後自主作業。
為什麼先掃描 236MB 對話紀錄,而不是直接寫規則?
因為制度要解的題目,全部藏在你過去糾正 AI 的紀錄裡,憑印象寫規則,寫出來的是你以為的問題,不是真實的問題。
Fable 5 派了三個平行的 subagent(子代理,主對話派出去做事的分身),分頭掃描三個工具的全部歷史:Claude 這邊 33 個 session 共 236MB 的對話紀錄,Codex 這邊 1763 筆指令歷史,Hermes 這邊的設定檔與錯誤日誌。
掃描指令很簡單:在對話紀錄裡搜尋「不對」「錯了」「你又」「講過」「不要再」這類糾正訊號,統計哪些錯誤重複出現。
Fable 5 本人全程不碰原始資料,只收三份結論報告,這就是提示詞裡「指揮官不下場」那條的實際效果,貴模型的 context 只花在判斷上。
一份正本加三個薄索引:三個 AI 怎麼共用一套制度?
核心架構一句話:制度只有一份正本,三個工具的指令檔只放路由。
如果你在 Claude 的 CLAUDE.md、Codex 的 AGENTS.md、Hermes 的設定檔各寫一份規則,三個月後它們一定互相矛盾,AI 讀到哪份就照哪份做,這叫規則漂移,是多工具使用者最大的隱形成本。
Fable 5 的做法是把制度正本放在一個三方共用的目錄(用 symlink 讓三個工具都掛載同一份),每個工具的指令檔瘦身成薄索引:只放五條鐵律摘要,加一張「遇到什麼情況去讀哪份檔」的路由表,正本更新一次,三個工具同步生效。

| 交付物 | 內容 | 解決什麼問題 |
|---|---|---|
| 快速診斷 | 每個工具最易出錯的前三名,各附修法 | 讓弱模型知道自己最容易在哪跌倒 |
| 薄索引指令檔 | 五條鐵律 + 路由表,上限 150 行 | 防止指令檔膨脹、防止規則漂移 |
| 模型調度守則 | 交辦三要素、升降級路徑、驗證不自驗 | 額度花在刀口上 |
| 判斷力外化 | 何時升級、何時算完成、何時該問人的判準,每條附正反例 | 把 Fable 5 的判斷變成弱模型可執行的 checklist |
| 交辦範本 5 份 | 搜尋、實作、重構、研究、審查 | 發包給 subagent 不再漏驗收條件 |
| 維護協議 | 哪些檔可自行改、踩坑寫回哪裡、多長要精簡 | 制度活得下去,不會三個月後爛掉 |
| 給未來的信 | 制度最可能的退化方式、信心最低的產出清單 | 誠實交接,下個 session 不用重新猜 |
對抗審查:為什麼要讓另一個 AI 來抓 Fable 5 的漏洞?
因為做的人不能驗自己的成果,就算是 Fable 5 也一樣,這條在提示詞裡叫「驗證不自驗」。
制度檔全部寫完後,Fable 5 派了一個全新上下文的 subagent 當審查員,它看不到寫作過程,只拿到檔案清單和審查標準:規則有沒有互相打架、路徑是不是真的存在、弱模型會不會誤讀。
結果審查員抓到 3 個阻擋級問題,包括兩份檔案對「收到任務要不要先問」給出矛盾指示,還有一條規則引用的檔案行數計算方式會讓體檢誤判,這些全是 Fable 5 自己回頭看八次也看不到的盲點。
掃描完三個 AI 的紀錄發現什麼?
最痛的不是 AI 犯錯,是同樣的錯在三個工具上用不同的形式重複發生,而我從來沒有把它們放在一起看過。
三個 AI 的共同病:沒驗證就說完成、疊 patch、糾正不留存?
對,掃描結果高度一致,三個工具的前三大問題幾乎是同一組。
第一名是沒驗證就宣稱完成,Claude 這邊有超過 8 次獨立事件,Codex 那邊留下過「這個沒改到」的紀錄,這是信任損耗的最大來源。
第二名是疊 patch 不找根因,同一個版面問題連續三次用表面修法蓋過去,全部無效,真正的根因是一個屬性衝突,讀一次原始碼就能找到。
第三名是糾正不留存,Codex 的歷史裡「講過」「說過」「記得」這類詞出現超過 20 次,代表同一件事我糾正了 20 次以上,它每次都答應,每次都忘。
設定寫 xhigh,實際大多在跑 medium?
這是整次掃描最意外的發現:你以為的設定,跟實際執行的設定,可能是兩回事。
我的 Codex 設定檔白紙黑字寫著推理強度 xhigh(最高檔),但 Fable 5 實際查了 95 筆執行紀錄,83 筆跑的是 medium,也就是說我以為自己一直用最高規格在跑重要任務,實際上大部分時候不是。
同一輪掃描還發現:Codex 的自動記憶管線從來沒有真正運作過(資料表 0 筆),等於它每個 session 都是失憶狀態,難怪糾正 20 次都沒用。
駕馭工程的第一步永遠是查證環境,不是寫規則,因為你連自己的 AI 現在怎麼跑都不一定知道,這也是提示詞裡誠實條款存在的原因。
| 工具 | 最痛的發現 | 制度解法 |
|---|---|---|
| Claude Code | 覆蓋使用者手動改過的檔案、大檔整讀燒 token | 寫回前先拉最新版只改指定欄位、只讀需要的段落 |
| ChatGPT Codex | 記憶管線 0 筆資料、設定與實際執行不符、跨檔修改漏改 | 糾正當場固化成靜態檔、收工前逐檔對帳 |
| Hermes Agent | 記憶檔有字數硬上限且常態撞頂、不讀其他工具的指令檔 | 通用教訓寫進共用正本、全域規則只放它真正會載入的檔案 |
企業主決策摘要
如果你是企業主,應該先盤點公司裡誰在用哪些 AI 工具、規則寫在哪裡,再決定要不要導入駕馭工程,判斷標準只有一條:同一個錯誤,AI 有沒有被糾正超過兩次?有,就代表你缺的是制度,不是更貴的模型。
導入順序建議:先讓一個人用上面的 Fable 5 提示詞跑一輪(沒有 Fable 5 就用手上最強的模型),產出制度檔,觀察兩週,如果 AI 重複犯錯的頻率明顯下降,再把「一份正本、多個薄索引」的架構推廣到團隊,讓所有人的 AI 工具讀同一套規則。
成本上這是一次性投資,我這輪從掃描到審查完成大約半天,之後的維護是每次踩坑花一分鐘把教訓寫回帳本,跟你導入任何 SOP 的邏輯一樣。
結論:Fable 5 會過期,駕馭工程的制度不會
這次駕馭工程給我最大的體會,不是省了多少額度,是換了一個問題來問。
大部分人在問:怎麼讓 AI 這次回答得更好?駕馭工程問的是:怎麼讓之後每一次都自動變好?前者的產出是一段對話,後者的產出是一套會複利的制度檔案。
模型會一直換代,今天的 Fable 5 明年就是平價品,但你沉澱下來的判準、交辦規則、踩坑帳本不會過期,它們會跟著每一代新模型繼續工作。
AI 把執行的成本降到趨近於零之後,你的優勢就只剩判斷力,而駕馭工程就是把判斷力寫成資產的方法。
提示詞就在上面,複製給你的 AI,讓它今天就開始幫未來的自己立制度。
推薦閱讀
過去是提示詞工程,未來是編排工程 Agent Harness Engineering
Hermes Agent 是什麼?2026 教學、費用、本地模型硬體需求
科技翰林院怎麼用 Claude Code 終端機?8 個實戰設定全公開
參考資料
Anthropic (2026). “Manage Claude’s memory – Claude Code Docs”
Anthropic (2025). “Claude Code Best Practices”
AGENTS.md (2025). “AGENTS.md: a simple, open format for guiding coding agents”
OpenAI (2026). “Codex Developer Documentation”
Nous Research (2026). “Hermes-Agent GitHub Repository”
HermesAgent.download (2026). “Hermes Agent 中文安裝與使用指南”
FAQ
駕馭工程 Harness Engineering 是什麼?
駕馭工程是把高階模型的判斷力轉成制度檔案與交辦規則,讓之後每一個較弱模型的 session 都能沿用的工程方法。它跟提示工程的差別是:提示工程優化單次對話,駕馭工程優化你跟 AI 協作的整個作業系統,產出是指令檔、判斷準則、交辦範本與踩坑帳本。
沒有 Fable 5 也能做駕馭工程嗎?
可以。駕馭工程的價值來自制度而不是特定型號,把提示詞裡的 Fable 5 換成你手上推理能力最強的模型即可,Opus、GPT-5.x 最高推理強度都行。差別在於頂級模型外化出來的判準品質更高,但就算用中階模型跑一輪,效果仍遠勝於什麼都不做。
CLAUDE.md 跟 AGENTS.md 差在哪?
兩者都是 AI 每次對話自動載入的指令檔,CLAUDE.md 是 Claude Code 的慣例,AGENTS.md 是 Codex 與多數開源 agent 採用的開放格式,Hermes Agent 也支援專案層的 AGENTS.md。駕馭工程的建議是:規則正本只放一份,這些指令檔全部瘦身成指向正本的薄索引。
為什麼不能讓 AI 自己驗證自己的產出?
因為做的人自驗必然放水,AI 會被自己的實作思路帶著走,看不到盲點。駕馭工程的做法是驗證不自驗:派一個全新上下文的 agent 當審查員,只給它檔案與驗收標準。這次實測,審查員抓到 3 個 Fable 5 自己完全看不到的阻擋級問題。
企業導入 AI Agent 前要先做駕馭工程嗎?
建議先做。判斷標準是:同一個錯誤你的 AI 有沒有被糾正超過兩次?有,代表缺的是制度不是更貴的模型。先讓一個人用本文的提示詞跑一輪產出制度檔,觀察兩週,重複犯錯頻率下降後,再把一份正本多個薄索引的架構推廣到全團隊。
駕馭工程的制度檔多久要維護一次?
日常維護是每次踩坑花一分鐘把教訓寫回帳本,結構性維護建議每月一次:檢查指令檔行數有沒有超標、薄索引是不是還指向正本、踩坑帳本超過 150 行就精簡。制度最大的敵人不是沒人用,是規則慢慢長回一大坨沒人讀的檔案。