iPAS AI 應用規劃師中級科目二:大數據處理分析與應用 6 大核心命題
科目二:大數據處理分析與應用
這是考點命題拆解版,幫你抓中級科目二(大數據處理分析與應用)的出題重點。如果你想先用白話故事讀懂,請看 [新手入門] 中級科目二:費曼學習法,7 個故事讓你讀完就懂。
跟科目一不同的是這份考卷大量考實作,50 題裡面光是 pandas、seaborn、numpy、sklearn 的程式碼或偽碼判讀約佔 12 題左右,但出題者藏在背後的判斷邏輯,其實只有 6 個底層命題。
我把每組相似題目壓到底層,告訴你大數據處理分析與應用這份考卷的出題者藏在背後的判斷邏輯是什麼,然後挑一題完整示範這個邏輯怎麼推到答案。
官方題目來源:https://ipd.nat.gov.tw/ipas/certification/AIAP/learning-resources
AI 應用規劃師中級科目二的考試邏輯跟六大命題地圖
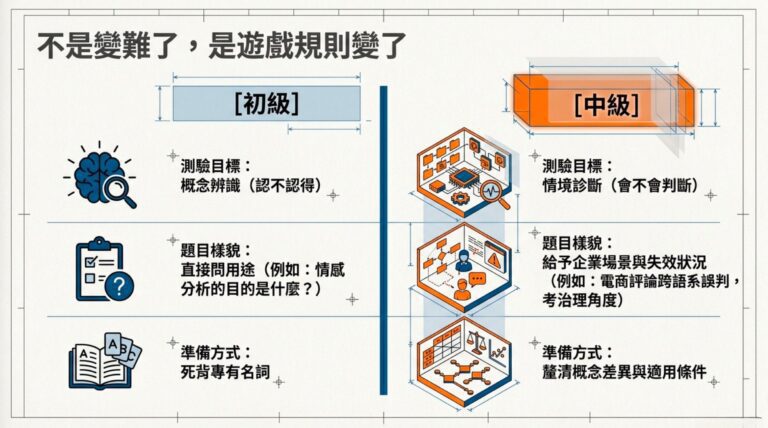
科目二跟科目一最大的差別,是它把會不會做放進評量裡。
科目一全部都是情境判斷題,科目二約有四分之一是程式碼或偽碼判讀題,你要能直接看出 df['Year'].astype('Int64') 跟 df['Year'].astype(int) 為什麼不一樣。
但即使是程式碼題,底層命題還是只有少數幾個,只是換成 pandas 或 seaborn 的語法包裝。
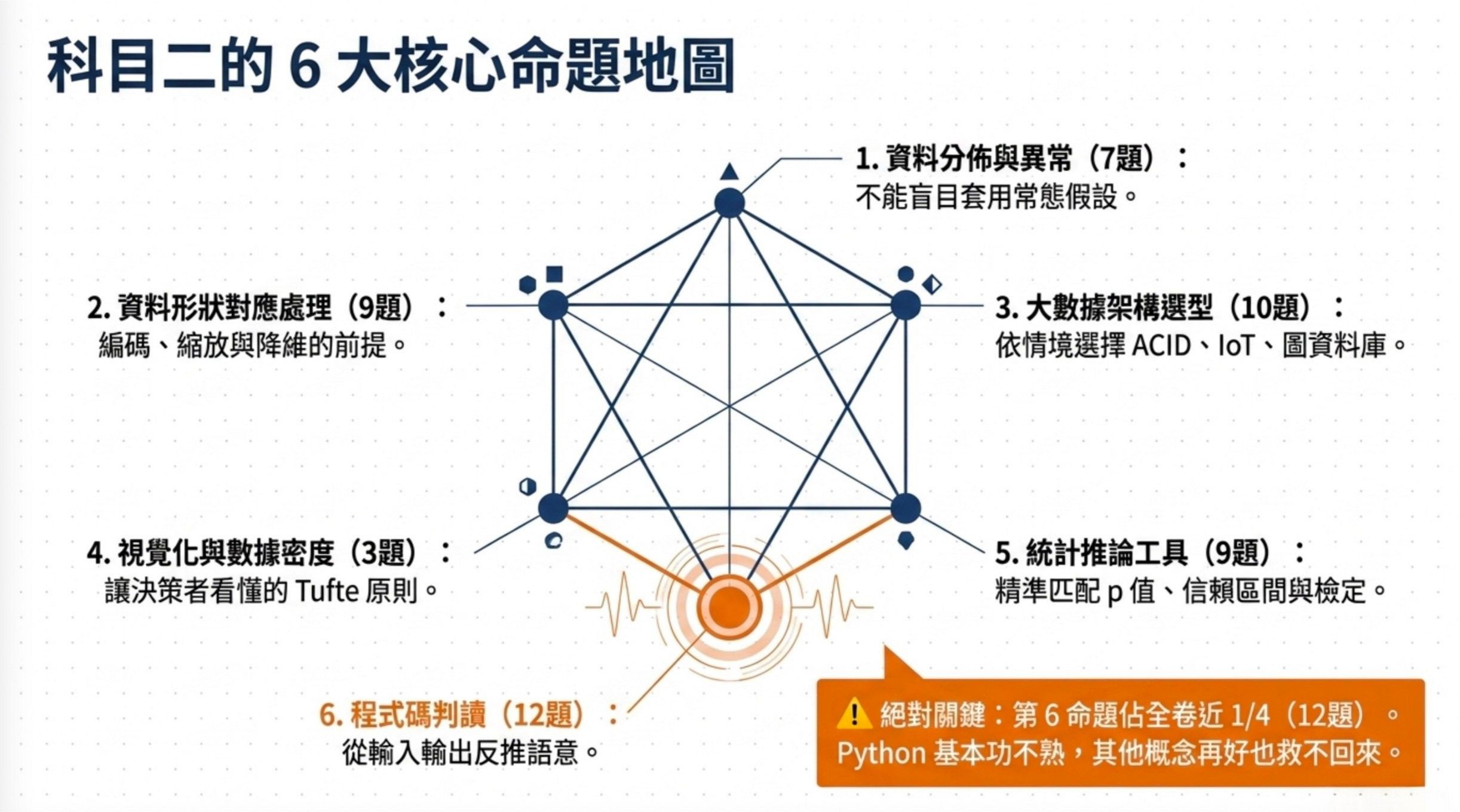
AI 應用規劃師中級科目二的六大核心命題地圖
我把 114 年第二次公告試題的 50 題逐一拆過之後,歸納出下面這張命題地圖。後面六個 H2 會依序講每一個命題。
| 命題 | 出題者想測的判斷力 | 對應題號 |
|---|---|---|
| 看懂資料的分佈跟異常 | Z-score、偏態、CDF、卜瓦松、常態近似、分位數迴歸的判斷直覺 | 1, 3, 4, 15, 16, 31, 33 |
| 資料形狀對應處理方法 | 編碼、縮放、降維、不平衡、Box-Cox 各自的使用情境 | 5, 6, 8, 9, 12, 17, 29, 36, 37 |
| 依需求選對的大數據架構 | ACID、IoT 即時流、同態加密、圖資料庫、RDF、資料湖的選型邏輯 | 7, 11, 13, 18, 19, 20, 24, 32, 34, 35 |
| 讓決策者看懂的視覺化 | Tufte 數據密度、相關性矩陣、對數刻度的設計原則 | 21, 22, 25 |
| 統計推論工具的選擇 | 信賴區間、雙比例 Z 檢定、皮爾森相關、關聯規則、分層 K-fold 的使用時機 | 10, 14, 23, 26, 27, 30, 38, 39, 40 |
| pandas 與 seaborn 程式碼判讀 | 從程式碼直接看出輸入輸出跟函式語意 | 2, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 28 |
這份地圖最值得看的是程式碼判讀這組佔了 12 題,將近全卷四分之一。
如果你的 Python 基本功不熟,光看其他五組概念懂得再好也救不回來。
考前最後一週的時間分配上,我會建議至少留兩天專門練 pandas 跟 seaborn 程式碼題。
1.看懂資料的分佈跟異常
這 7 題的底層命題只有一句:資料的分佈型態決定你能用什麼方法,不能盲目套常態分佈的假設。
大數據處理分析與應用這個科目最常考的就是這個基本判斷,AI 應用規劃師遇到的真實資料,絕大多數不是完美的常態分佈,而是右偏的銷售金額、左偏的成功率、長尾的金融損失。會分辨分佈型態,才知道下一步該選什麼。
要學會這個命題,先建立四個基本概念。
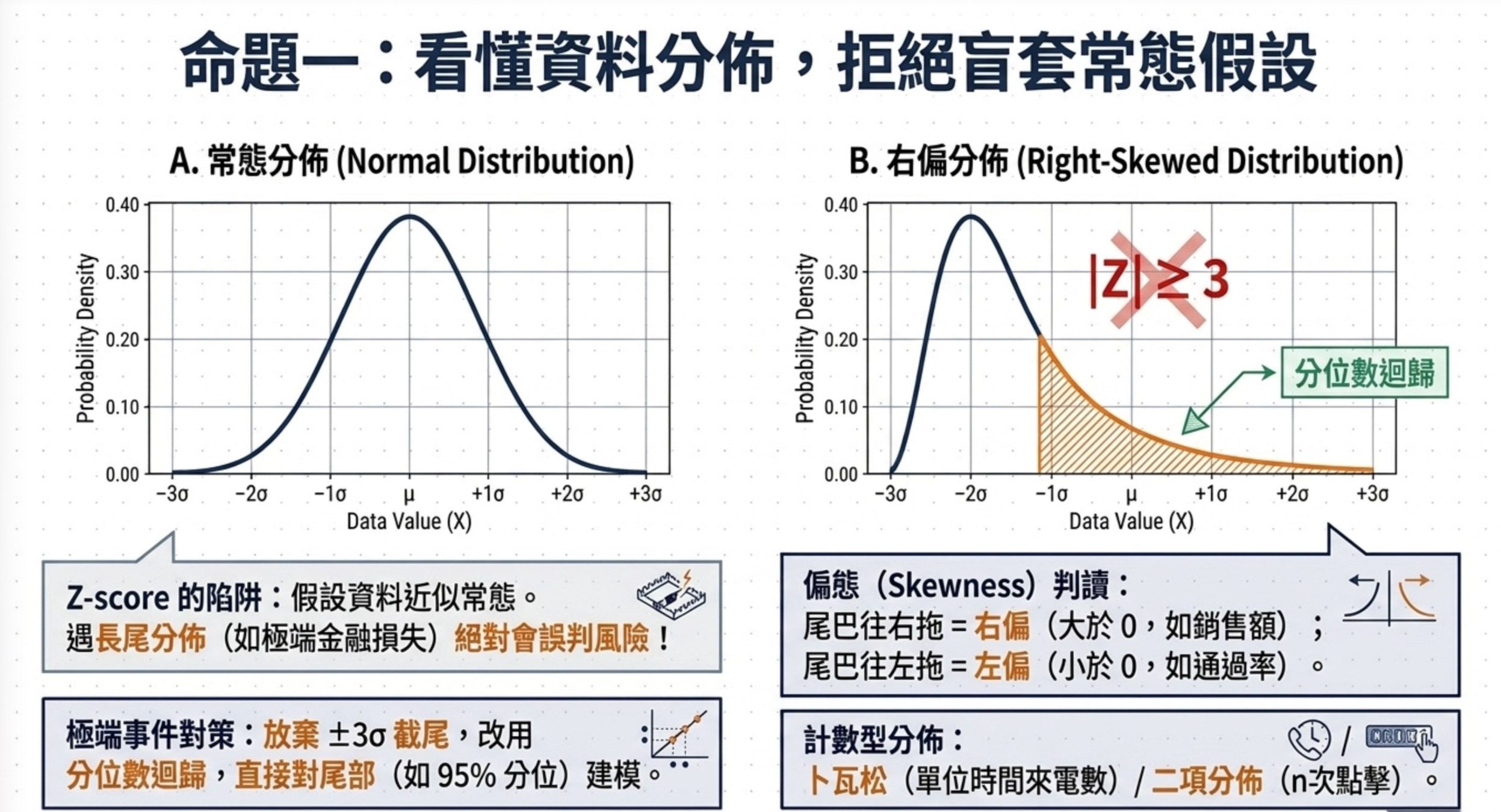
第一個是 Z-score。Z-score 是把任何分數轉成離平均幾個標準差的距離。Z=2 代表這個數值比平均高出 2 個標準差,在常態分佈下大約落在前 2.5% 的位置。實務上會用 |Z| ≥ 3 作為異常值的判定門檻,因為這個位置在常態下機率小於 0.3%。但要小心:Z-score 本身只是標準化距離,不一定要求常態;但若要用 Z-score 推估機率位置或用 |Z| >= 3 當異常門檻,資料最好接近常態或至少不要嚴重偏態。
第二個是偏態(Skewness)。偏態值大於 0 代表右尾長(右偏,例如薪資、銷售金額),小於 0 代表左尾長(左偏,例如考試通過率)。看直方圖時要看尾巴往哪邊拖,不是峰值在哪邊。一個峰值在右邊但尾巴往左拖的圖,偏態是負的。
第三個是分佈的選擇。卜瓦松分佈描述單位時間內事件發生的次數,前提是事件彼此獨立、平均發生率固定,例如客服中心每分鐘來電數。二項分佈描述n 次獨立試驗的成功總數,例如 5000 位顧客的點擊數。當 np 跟 n(1-p) 都大於 5 時,二項可以用常態近似。常態分佈適合近似對稱、尾端不太厚的資料。金融損失常有偏態與厚尾,若硬套常態,可能低估極端損失風險。
第四個是面對極端事件的工具。當資料明顯右偏、且有多次極端損失,平均數加減標準差或 ±3σ 截尾都會誤判風險。這時要改用分位數迴歸(Quantile Regression),它能直接針對尾部分位(例如 95% 分位)建模,捕捉極端風險。CDF(累積分佈函數)則是這類分析的數學基礎,它是「小於等於某個值的累積機率」。連續分佈可看成 PDF 的積分;離散分佈(如 Poisson)則是 PMF 的累加。
示範解題:以金融資料的非常態分佈為例
挑題 33 示範,因為它最能展現資料分佈不對稱時不要硬套常態工具這個判斷力。
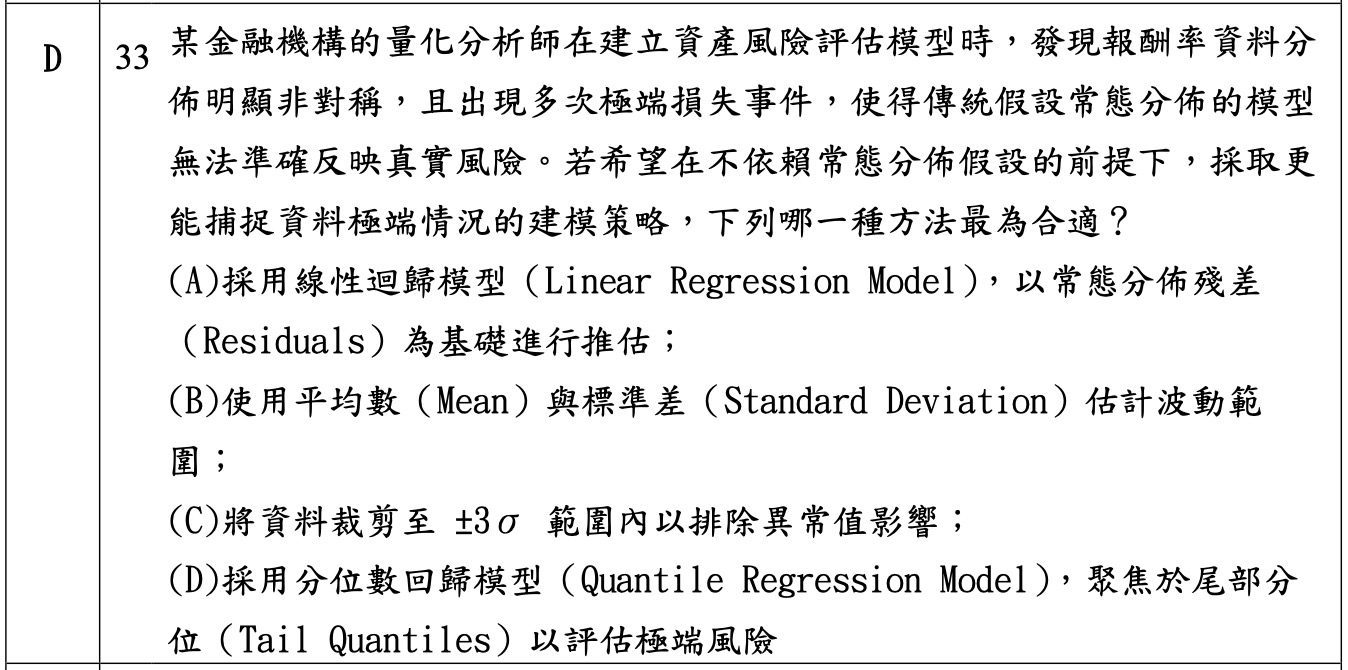
題目情境:某金融機構的量化分析師發現報酬率資料分佈明顯非對稱,且出現多次極端損失事件,使得傳統假設常態分佈的模型無法準確反映真實風險。若希望在不依賴常態分佈假設的前提下,採取更能捕捉資料極端情況的建模策略,問該用哪一種方法。
推理過程:
第一步,辨識題目給的兩個關鍵訊號,資料分佈非對稱、出現極端損失事件。這直接告訴你資料不是常態。
第二步,排除所有假設常態的選項,例如線性迴歸殘差常態假設、用平均數標準差估計波動範圍、用 ±3σ 截尾,這三個都是常態世界的工具。
第三步,在剩下的選項裡找能捕捉尾部極端的方法。分位數迴歸正是針對尾部分位建模,例如可以直接對 5% 或 95% 分位做迴歸,完全跳過常態假設,所以答案是 D。
這個命題的變形題:題 1 用 Z-score 包裝離平均幾個標準差、題 3 用直方圖包裝偏態方向判讀、題 4 用 CDF 定義包裝積分概念、題 15 用客服中心包裝卜瓦松、題 16 用金融交易包裝 Z-score 異常判定、題 31 用顧客點擊包裝二項常態近似(注意要看 np 跟 n(1-p) 都大於 5 的條件)。
把這四個基本概念建立好,這 7 題你能自己過。
2.資料形狀對應處理方法
這 9 題的底層命題跟科目一非常像,但更深入:資料的形狀決定你該用什麼處理方法,而每種方法都有它假設的前提。
在大數據處理分析與應用這份考卷裡,盲目套用會出現量級偏誤、虛假順序、過擬合。
這個命題的核心觀念有四層。
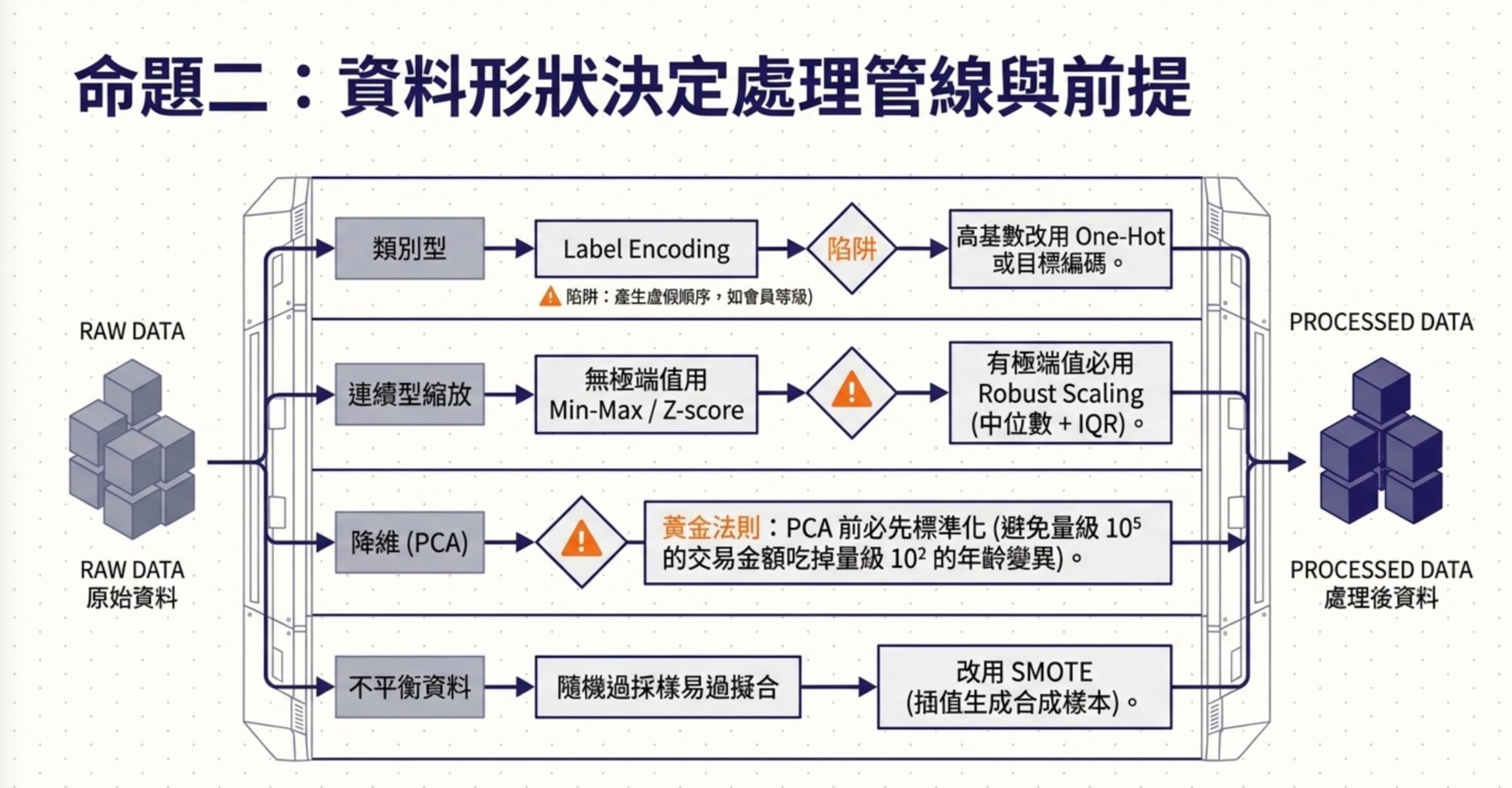
第一層是類別型資料的編碼:Label Encoding 把類別轉成整數,例如把白金、黑卡、一般編成 0、1、2。問題是這引入了不存在的順序關係,線性模型跟距離式模型會把 1 跟 2 的距離跟 2 跟 0 的距離當成有意義的數值差距。樹模型(包含梯度提升樹)對 Label Encoding 比較寬容,但比較寬容不等於沒事,尤其當題目沒指明用樹模型時,用 One-Hot 或目標編碼比較穩。One-Hot 在類別數很多(高基數)時會造成維度爆炸,這時候要考慮目標編碼或嵌入。但目標編碼會用到目標值,實務上要搭配 cross-fitting 或交叉驗證,否則容易資料洩漏與過擬合。
第二層是連續型資料的縮放:Min-Max Scaling 把資料壓到 0 到 1 之間,但對極端值敏感。Z-score 標準化把資料轉成平均 0、標準差 1,但對極端值也敏感(因為平均跟標準差都被極端值拉動)。Robust Scaling 用中位數跟四分位距,對極端值最穩。記住:有極端值就用 Robust Scaling,沒有極端值就用 Z-score 或 Min-Max。注意 Z-score 標準化不會把資料壓到 0 到 1 之間,它的範圍是看資料分佈,常態下大部分落在 ±3 之間。
第三層是降維跟特徵選擇:PCA 對量級敏感,當特徵尺度差異大時(例如交易金額 10⁵、年齡 10²),不先標準化會讓量級大的特徵主導所有主成分。所以當特徵單位不同、量級差很多時,PCA 之前應先標準化。若特徵已在同一量尺,則不一定要標準化。Box-Cox 轉換常用來處理正值資料的右偏與變異數不齊次(heteroskedasticity),把資料盡量轉成接近常態;但 Box-Cox 要求資料大於 0,若有 0 或負值,要先平移或改用 Yeo-Johnson。
第四層是不平衡資料:隨機過採樣會把少數類樣本重複貼上,容易過擬合。SMOTE 透過插值生成合成樣本,比直接複製更不容易過擬合,適合資料量少又無法新增的場景。隨機欠採樣會丟資料,但在多數類資料超多時可以接受。調整類別權重是另一條路,讓模型在訓練時對少數類錯誤更敏感。
示範解題:以 PCA 前該不該標準化為例
挑題 29 示範,因為它最能展現方法有前提,不能盲套這個判斷力。

題目情境:某團隊在風險評估模型中使用 PCA 降維,輸入有三個欄位:交易金額(單位新台幣,量級 10⁵)、交易次數(次每月,量級 10¹)、年齡(歲,量級 10²)。直接帶 PCA 後,第一主成分(PC1)幾乎完全由交易金額主導。問哪一項判斷最合理。
推理過程:
第一步,辨識訊號,三個變數的量級差了 3 到 4 個數量級,而 PC1 被量級最大的變數主導。
第二步,想 PCA 的數學本質,PCA 是找變異最大的方向,變異是用平方和算的。當交易金額本身數字大時,它的平方和自然遠大於其他變數,PCA 會誤把數值大當成變異大,結果第一主成分變成只反映交易金額。
第三步,看選項,A 說這正常,但這正是 PCA 量級偏誤的典型錯誤。B 說特徵選擇法能解決,但題目要的是降維不是篩選。C 說刪掉交易金額,但這是丟資訊不是解問題。D 說標準化,這正是解這個量級偏誤的標準做法,標準化後三個變數都變成平均 0 標準差 1,PCA 才能公平看到每個變數的相對變異,所以答案是 D。
這個命題的變形題:題 5 用 Label Encoding 包裝虛假順序、題 6 用 One-Hot/Label/標準化/分箱包裝各種編碼差異、題 8 用銷售金額/瀏覽次數包裝特徵衍生、題 9 用極端值包裝 Robust Scaling、題 12 用隨機過採樣包裝過擬合風險、題 17 用梯度提升樹會員等級包裝 Label Encoding 的順序誤判、題 36 用右偏資料包裝 Box-Cox、題 37 用罕見疾病不到 1% 包裝 SMOTE。
把四層觀念建立好,這 9 題你能自己過。
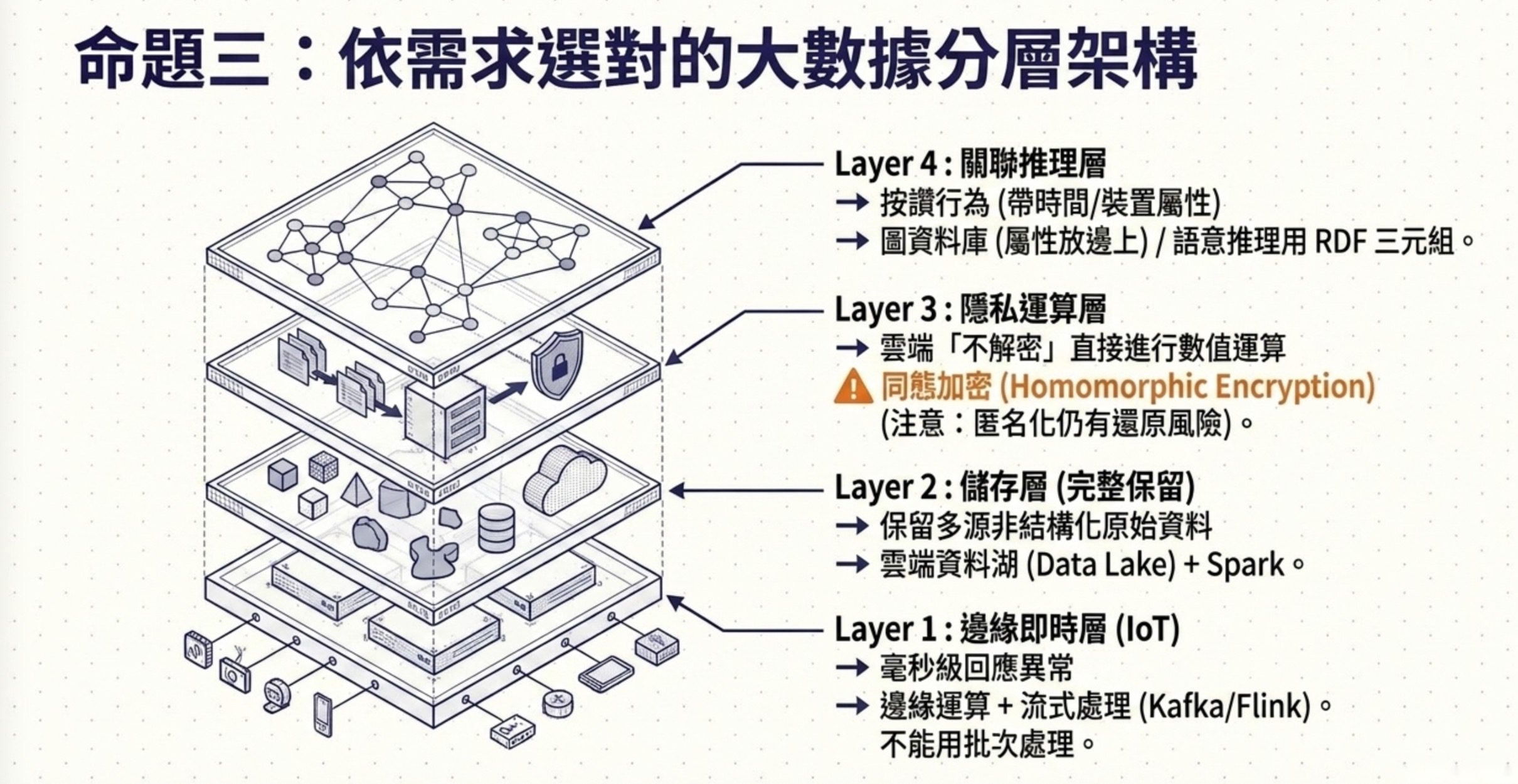
3.依需求選對的大數據架構
這 10 題的底層命題是:大數據架構不是越潮越好,要看你解的需求是什麼。這也是大數據處理分析與應用的核心精神。即時性、完整性、隱私、語意關聯,各自對應不同的選型。AI 應用規劃師最該有的能力,是聽完客戶需求就能畫出對的資料流。
這個命題的選型邏輯可以拆成四個面向。
第一個面向是交易型資料庫的 ACID 特性:原子性(Atomicity)是交易不可分割,要嘛全成功要嘛全回復;一致性(Consistency)是交易結束後資料符合完整性規則;隔離性(Isolation)是多筆交易互不干擾;持久性(Durability)是交易一旦提交就永久保留。當題目提到節點錯誤但整體不出現部分更新,直接想原子性;持久性是「交易提交後,即使系統故障,結果也不會消失」。不可竄改、可稽核是另外的治理或資安要求,不要直接等同於 ACID 的 Durability。
第二個面向是即時資料流的架構:當 IoT 感測器每秒產生大量資料、需要毫秒級回應、又要保留完整資料供日後 AI 訓練,單一架構搞不定,要分層處理。標準做法是:邊緣運算節點處理即時判斷、流式資料處理框架(例如 Kafka + Flink)做即時聚合、雲端資料湖儲存原始資料、模型推論在合適的層次執行。分散式資料庫加批次特徵工程不適合即時需求、MQTT 加資料倉儲少了即時處理層、本地快取加 RESTful 加報表是傳統資訊系統思維。
第三個面向是隱私技術的選擇:匿名化是去除可識別欄位,但仍可能被反推出個人;雜湊轉換是不可逆但不能還原;同態加密是最特別的一種,允許在不解密的情況下對密文執行特定運算,解密後可得到對應的明文運算結果。它適合隱私敏感的外包運算或雲端分析,但成本、效能與可支援運算型態都有限制。當題目要求雲端不解密就能運算時,答案就是同態加密。但要注意,實務上同態加密還是有計算成本,所以多銀行協作的場景會搭配安全多方計算(MPC)、雜湊跟對稱加密一起用。
第四個面向是非結構化資料的儲存:圖資料庫的核心是節點跟邊,屬性可以放在節點或邊上。當題目提到按讚行為包含時間戳記跟裝置類型這種帶屬性的關係,正確設計是把資訊放在邊的屬性上,連結使用者跟貼文兩個節點。知識圖譜要做語意推理跟擴展,標準做法是 RDF 三元組(主語、謂語、賓語),不是把全部資訊塞進節點屬性、也不是用文件型加標籤、更不是用關聯式資料庫加索引。資料湖(Data Lake)結合 Spark 或 Ray 是處理多源異質資料的主流做法。
示範解題:以 IoT 即時加完整資料保留為例
挑題 19 示範,因為它最能展現分層架構對應分層需求這個判斷力。

題目情境:某製造企業導入上萬台 IoT 感測器做設備健康監測,系統需在毫秒級回應異常事件,並同時將完整資料保留於雲端供後續 AI 模型訓練與分析。問哪一種資料流程設計最符合即時性、資料完整性與可擴展性。
推理過程:
第一步,把需求拆成三層。毫秒級回應需要邊緣或流式處理、完整資料保留需要雲端資料湖、可擴展需要分散式架構。
第二步,看選項。
A 用分散式資料庫加批次特徵工程,批次不符合毫秒級需求。
B 用 MQTT 加資料倉儲加即時儀表板,少了流式處理這層,而且資料倉儲缺少邊緣運算與流式處理層,難以滿足毫秒級異常回應,也不適合作為完整原始資料保留與後續 AI 訓練的主架構。
C 用邊緣運算節點(處理即時)、流式資料處理框架(即時聚合)、雲端資料湖(完整保留)、模型推論。這個分層正好對應三個需求。
D 用本地快取加 RESTful 加報表,是傳統 IT 思維,不是大數據架構。
所以答案是 C。
這個命題的變形題:題 7 用 ACID 包裝原子性的定義、題 11 用 IoT 即時監控包裝大數據平台加即時分析、題 13 跟題 20 用同態加密包裝雲端不解密運算、題 18 用分散式資料庫節點錯誤包裝原子性的實例、題 24 用生成式 AI 多源資料包裝資料湖加 Spark、題 32 用客服系統真實資訊洩漏包裝匿名化跟稽核機制、題 34 用按讚行為包裝圖資料庫邊屬性、題 35 用知識圖譜包裝 RDF 三元組。
把四個面向記熟,這 10 題你能自己過。
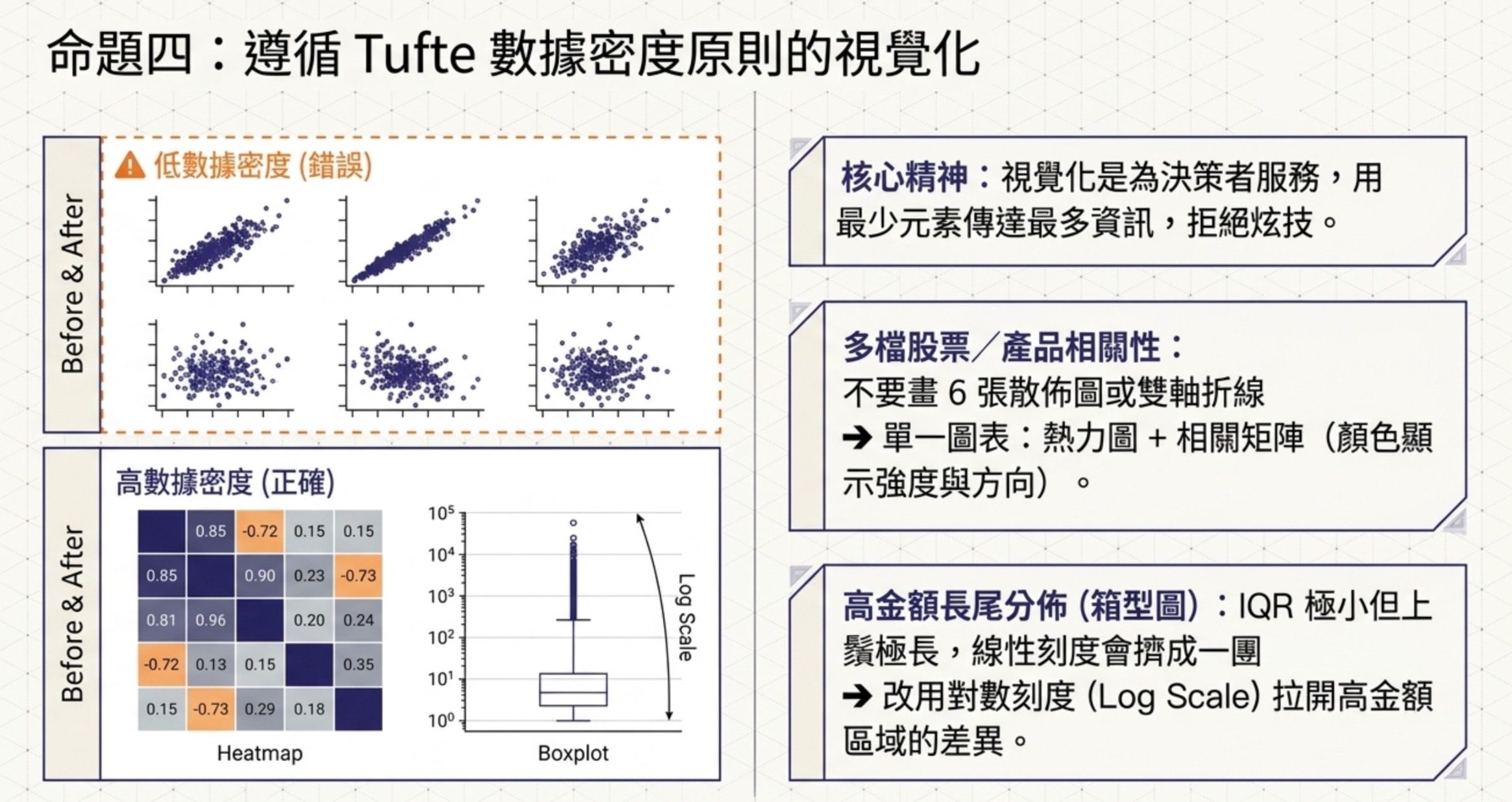
4.讓決策者看懂的視覺化
這 3 題雖然數量少,但每一題都在問同一件事:視覺化的目的是讓決策者看懂,不是讓資料分析師炫技。
大數據處理分析與應用的視覺化題目,Tufte 提出的數據密度(Data Density)原則,是這組題目的底層精神。
數據密度的核心,是用最少的視覺元素傳達最多的資訊。把每個區域畫成獨立的圖、移除所有輔助線只留主線、轉成表格放數字,這些都是減損數據密度的做法。真正符合密度原則的做法,是用顏色、對比、形狀,在同一張圖上整合多維度資訊,讓決策者一眼掌握。
幾個常見的視覺化選擇判斷:
多檔資料的相關性比較用熱力圖加相關係數矩陣。為四檔股票畫直方圖只能看分佈、兩兩散佈圖要畫六張、雙軸折線只能放兩條,都比不上一張熱力圖直接顯示所有兩兩相關係數。
箱型圖的高金額長尾要用對數刻度。當 IQR 很小但上鬚拉得很長,代表資料高度右偏,用線性刻度會擠在底部看不清楚。對數刻度能拉開高金額區域的差異,讓行銷部門看到不同消費層級的真實樣貌。移除離群值是丟資訊、等距分箱也不適合右偏資料、改折線圖是換問題不是換視覺化。
示範解題:以多檔股票相關性分析為例
挑題 22 示範,因為它最能展現依資料特性選對視覺化這個判斷力。

題目情境:某投資研究員想分析四檔科技類股每日報酬率的變化趨勢,判斷股票之間是否存在高度相關性與共變動性,並評估投資組合分散風險的程度。希望以單一圖表快速呈現各股票間的關聯強度與方向。問用哪一種視覺化方式最適合。
推理過程:
第一步,辨識需求。要看兩兩相關性、要單一圖表、要快速呈現強度與方向。
第二步,看選項。
A 四個直方圖只能看分佈,看不到相關。
B 兩兩散佈圖要畫 C(4,2)=6 張圖,不符合單一圖表。
C 雙軸折線最多兩條線,不適合四檔。
D 熱力圖加相關係數矩陣,顏色強度直接顯示相關性、加上正負號顯示方向,一張圖呈現所有兩兩關係。
所以答案是 D。
這個命題的變形題:題 21 用 Tufte 數據密度包裝多區域多產品線銷售報告、題 25 用箱型圖長尾包裝對數刻度的使用時機。
把數據密度原則跟對數刻度建立好,這 3 題你能自己過。
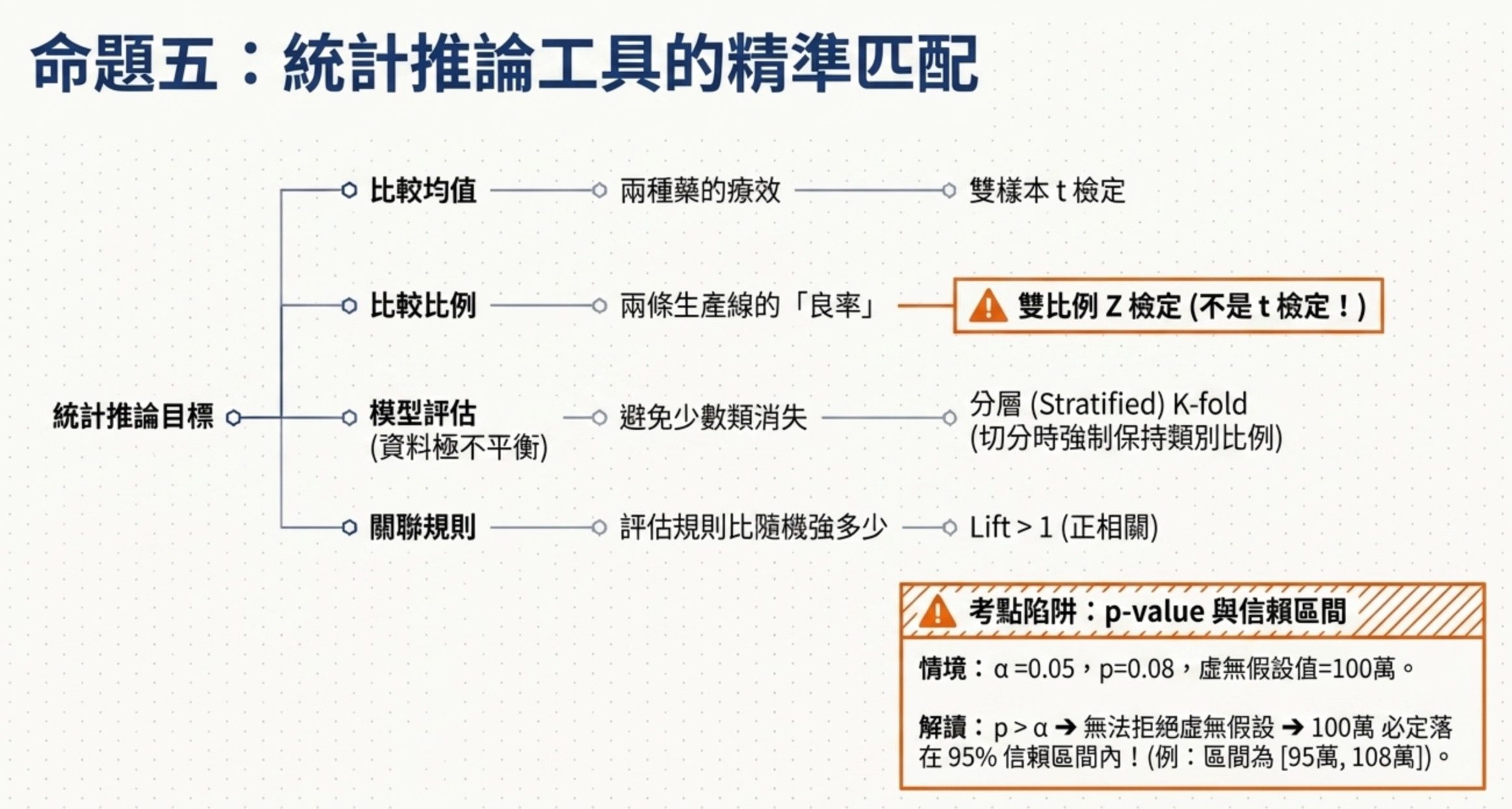
5.統計推論工具的選擇
這 9 題的底層命題是:統計推論工具不是替換的,每一個都對應一種特定的問題形狀。
這也是大數據處理分析與應用最常見的題型之一,AI 應用規劃師要能在 3 秒內把題目分到對應的工具。
四種最常考的問題形狀:
第一種是比例比較。比較兩個生產線的良率,因為良率是比例不是平均數,所以要用雙比例 Z 檢定,不是雙樣本 t 檢定。t 檢定是比平均數(例如兩種藥的療效),Z 檢定大樣本下也能比平均,卡方是比類別分佈,ANOVA 是比多組均值。看到「兩組獨立樣本的比例差異」且樣本數夠大,優先想到雙比例 Z 檢定。
第二種是 p 值跟信賴區間的關係。在雙尾檢定且信賴區間水準與 α 對應時,p 值 >= α 通常代表虛無假設值落在信賴區間內,無法拒絕虛無假設。當題目給 p=0.08、95% 信賴區間是 [95 萬, 108 萬]、虛無假設值 100 萬時,100 萬剛好在區間內,所以無法拒絕。p 值改 0.10 是不是會改變結論,要看當下的 p 值跟新 α 的比較,題目沒給就不能說一定不顯著。
第三種是評估方法的選擇。資料極度不平衡時,5-fold CV 可能某些折裡完全沒有少數類,評估會失真。分層 K-fold(Stratified K-Fold)確保每折的類別比例一致,是不平衡資料下的標準做法。K-fold 跟分層 K-fold 在偽碼上的差別是,K-fold 純隨機切,分層 K-fold 切的時候會保持類別比例。
第四種是關聯規則的解讀。支持度(Support)是某規則發生的整體比例;信賴度(Confidence)是條件機率,例如看 A 的人中有多少比例也看 B;提升度(Lift)是這條規則比隨機強多少,Lift = 1 代表獨立,Lift > 1 代表正相關。題目給 Lift = 1.8、信賴度 50%、支持度 12% 時,Lift > 1 已經排除無關的選項,信賴度 50% 表示看科幻影集的人有一半也看超英電影這是明顯傾向。
示範解題:以 p 值跟信賴區間的關係為例
挑題 23 示範,因為它最能展現不要只看 p 值就下結論這個判斷力。

題目情境:某研究團隊以單樣本 t 檢定檢驗新行銷策略後的平均月銷售額是否與原本的 100 萬元不同,顯著水準 α=0.05。結果 p=0.08、95% 信賴區間 [95 萬, 108 萬]。問下列敘述何者正確。
推理過程:
第一步,看 p 值跟 α 的關係。p=0.08 > α=0.05,所以不能拒絕虛無假設。選項 A 說可以拒絕,直接錯。
第二步,看信賴區間。虛無假設值 100 萬是不是在 95% 信賴區間 [95 萬, 108 萬] 內?是的。這跟 p 值 ≥ α 的結論一致,無法拒絕虛無假設。選項 C 正確。
第三步,排除其他。B 說 α 改 0.10 仍不顯著,但 p=0.08 < 0.10,改 α 後就會拒絕,B 錯。D 說信賴區間寬度只跟 α 有關,但實際上還跟樣本變異跟樣本數有關,D 錯,所以答案是 C。
這個命題的變形題:題 10 用即時金融交易包裝異常偵測情境、題 14 用 A、B 各半包裝吉尼不純度最大值、題 26 用串流影音包裝關聯規則的支持度信賴度提升度、題 27 用近似分位數包裝大數據摘要、題 30 用廣告銷售包裝皮爾森相關係數、題 38 用兩條生產線良率包裝雙比例 Z 檢定、題 39 用 80% 良性樣本包裝分層 K-fold、題 40 用偽碼包裝 LOOCV(留一交叉驗證:每次只留 1 筆測試,其餘全部訓練,重複 N 次)。
把四種問題形狀記熟,這 9 題你能自己過。
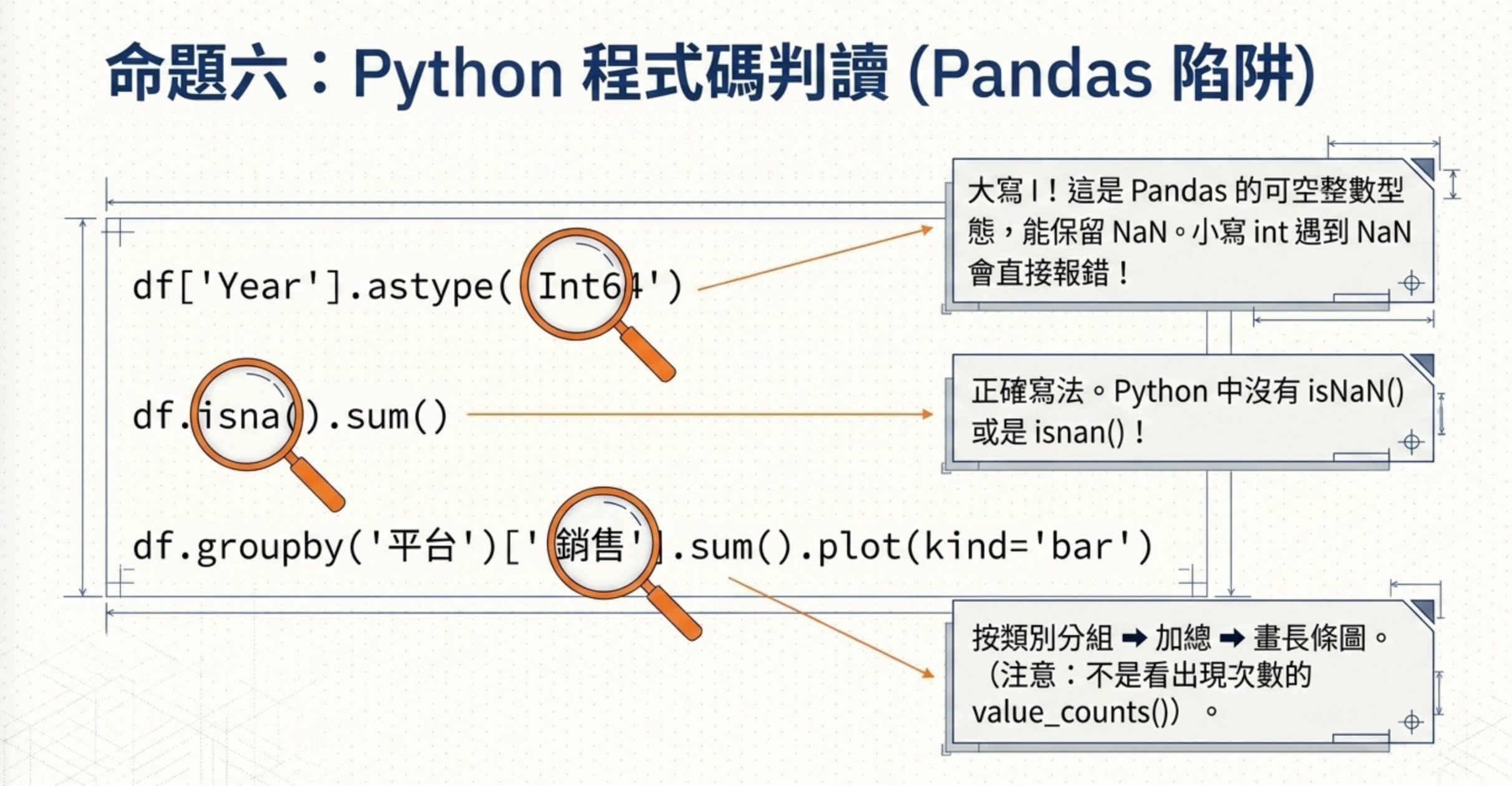
6. Pandas 與 Seaborn 程式碼判讀
這 12 題佔了全卷將近四分之一,是科目二跟科目一最大的差別。
底層命題只有一句:程式碼題不要硬背,要能直接從輸入輸出推回函式語意。
大數據處理分析與應用的程式碼題,絕大多數都是這個邏輯。
程式碼判讀的核心能力可以拆成三個面向。
第一個面向是 pandas 基本函式。df['欄位'].describe() 給敘述性統計(count、mean、std、min、25%、50%、75%、max)。df['欄位'].astype(int) 直接轉整數,遇到 NaN 會出錯。df['欄位'].astype('Int64') 大寫 I 的版本是 pandas 的可空整數型態,能處理 NaN(注意是大小寫差別,小寫 int 不行)。df.isnull().sum() 跟 df.isna().sum() 是同義詞,都算每欄的 NaN 個數,沒有 isNaN() 也沒有 isnan() 這兩個函式。fillna(0) 把 NaN 填 0,但要小心如果原資料是年份,填 0 會變成西元 0 年。
第二個面向是 pandas 跟 seaborn 繪圖。df.groupby('欄位')['數值'].sum().plot(kind='bar') 是按類別加總再畫長條,這是看各平台總銷售的標準寫法。value_counts() 是看每個類別出現幾次,跟 sum 不一樣。df.nlargest(5, '欄位') 是依某欄位取前五大,搭配 sns.barplot(x='Name', y='NA_Sales', data=df.nlargest(5, 'NA_Sales')) 就能畫北美前五暢銷遊戲。要比較多個欄位的總和(例如 NA、EU、JP、Other 各區總銷售比例),在這題的選項中,用 pd.melt() 把寬表轉成長表再丟給 seaborn 的 barplot 是正確做法。實務上也可以先算出各欄總和再轉表繪圖。
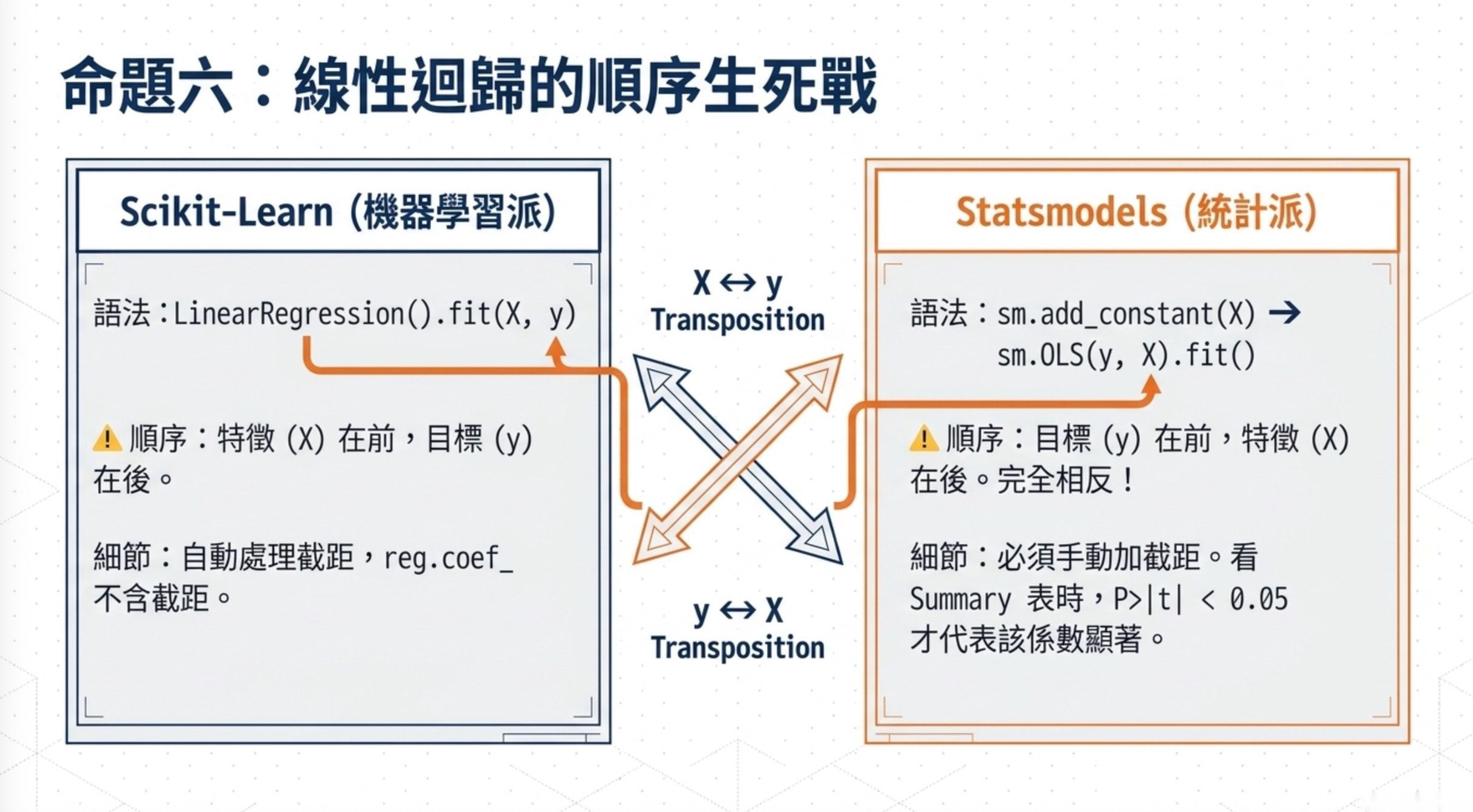
第三個面向是 sklearn 跟 statsmodels 的線性迴歸。LinearRegression().fit(X, y) 順序固定是 X 在前 y 在後,不能反過來。reg.coef_ 只給斜率不含截距(截距在 reg.intercept_)。statsmodels 的 OLS 需要先 sm.add_constant(X) 加上截距欄位,然後 sm.OLS(y, X2).fit() 的順序是 y 在前 X 在後,跟 sklearn 相反。看 OLS summary 表時,P>|t| < 0.05 才表示該係數顯著,若某個係數的 P>|t| = 0.914,就不能說所有係數都顯著。
示範解題:以 pandas 處理 NaN 的型態轉換為例
挑題 44 示範,因為它最能展現pandas 大小寫的關鍵差異這個判斷力,而且我在工作上也最容易遇到這種陷阱。

題目情境:研究團隊想把 Year 欄位轉成整數型態,以便後續年份趨勢分析。考慮到資料中可能包含缺失值(NaN),問最合適的轉換方式。
推理過程:
第一步,辨識限制條件。包含 NaN是關鍵字。pandas 的 numpy 整數型態不支援 NaN,只有浮點數能存 NaN。所以直接 .astype(int) 會出錯。
第二步,看選項。A 是 .astype(int),有 NaN 時會出錯。B 是 .fillna(0).astype(int),雖然能跑但 0 不是合理的年份,會污染資料。C 是 .fillna(1).astype(int),同樣的污染問題。D 是 .astype('Int64'),大寫 I 的 Int64 是 pandas 的可空整數型態,能保留 NaN 也能存整數。所以答案是 D。
這個命題的變形題:題 2 用 df['欄位'].describe() 包裝敘述性統計、題 28 用 DBSCAN 在高維下失效包裝距離趨同(這題其實是概念題但配合下面實作題一起學)、題 41 用 K-means 偽碼包裝隨機初始中心加迭代、題 42 用卜瓦松 pmf 包裝程式碼判讀、題 43 用 Year float64 包裝 NaN 自動轉浮點數、題 45 用 groupby sum bar 包裝平台銷售長條圖、題 46 用 pd.melt 加 seaborn barplot 包裝多欄位比較、題 47 用 nlargest 加 sns.barplot 包裝前五大、題 48 用 describe() 結果包裝 Q1 跟中位數的解讀、題 49 用 isnull/isna 包裝 NaN 計算的正確語法、題 50 用 sklearn 加 statsmodels 包裝兩種迴歸的順序差異。
把三個面向練熟,這 12 題你能自己過。
科目二最容易混淆的 12 組概念對照
學完六大命題,考前最後一週把下面這 12 組高混淆概念兩兩比較一次。能用自己的話講出差異就過關;講不出來就回去翻對應的命題。
| 兩個概念 | 差異關鍵 |
|---|---|
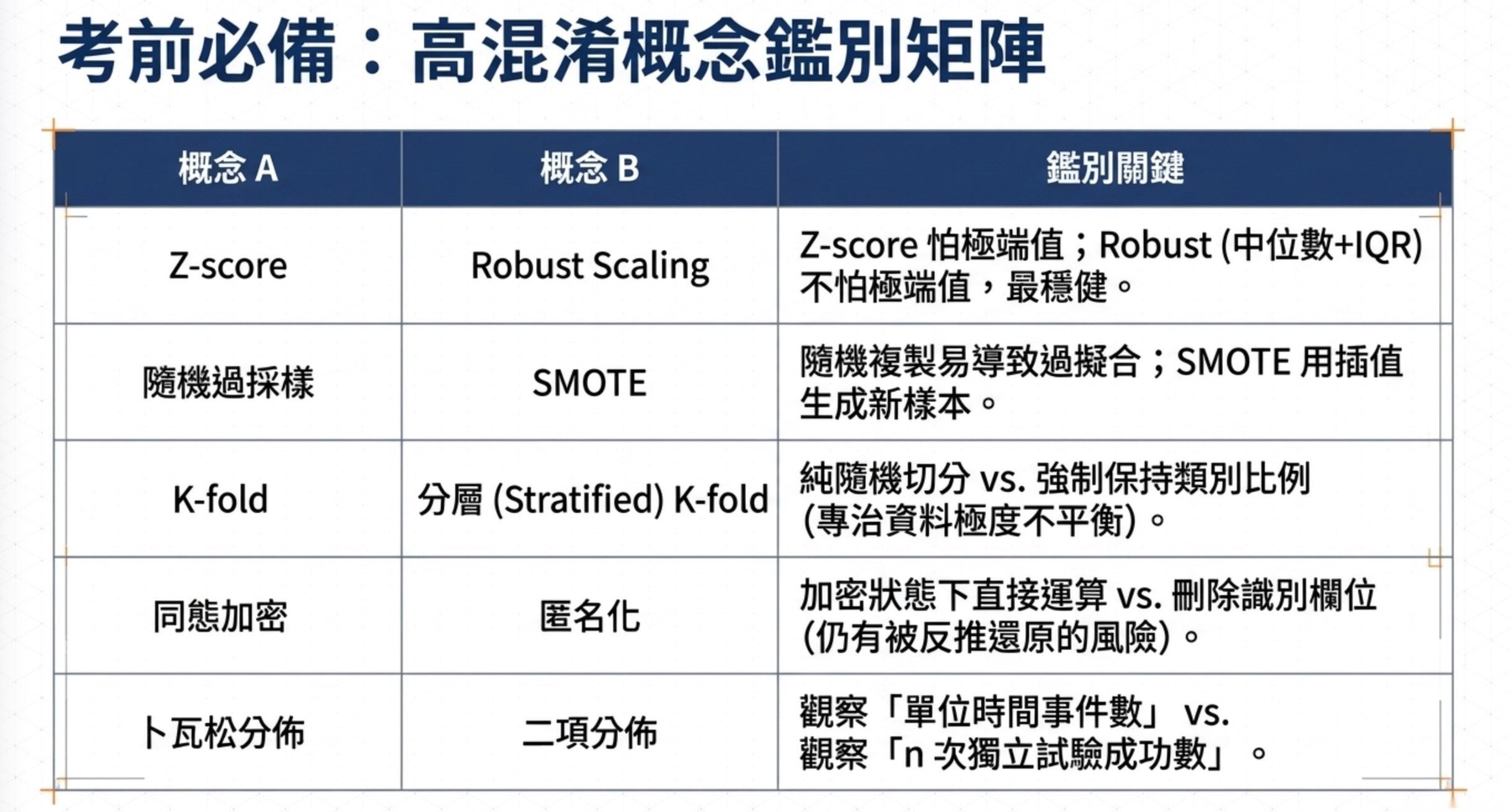
| Z-score vs IQR | Z-score 假設常態適合對稱資料,IQR 對極端值穩健 |
| 卜瓦松 vs 二項 vs 常態 | 卜瓦松看單位時間事件數,二項看 n 次試驗成功數,常態是極限情況 |
| One-Hot vs Label Encoding | One-Hot 不引入順序但高基數會爆炸,Label Encoding 簡單但有虛假順序 |
| Min-Max vs Z-score vs Robust | Min-Max 壓到 [0,1] 怕極端值,Z-score 平均 0 標準差 1 怕極端值,Robust 用中位數跟 IQR 最穩健 |
| PCA vs LASSO | PCA 是無監督降維且對量級敏感要先標準化,LASSO 是有監督特徵選擇 |
| 隨機過採樣 vs SMOTE | 隨機過採樣容易過擬合,SMOTE 用插值生成合成樣本 |
| 雙樣本 t 檢定 vs 雙比例 Z 檢定 | t 檢定比平均數,Z 檢定比比例 |
| ACID 四項特性 | 原子性看交易整體成敗,一致性看完整性規則,隔離性看併發,持久性看落地 |
| 圖資料庫節點 vs 邊屬性 | 帶時間裝置等屬性的關係放邊上,純粹的物件放節點 |
| RDF 三元組 vs 屬性圖 | RDF 適合語意推理跟擴展,屬性圖適合複雜關係的快速查詢 |
| 同態加密 vs 匿名化 vs 雜湊 | 同態加密能加密下運算,匿名化會丟欄位,雜湊不可逆但不能還原 |
| K-fold vs Stratified K-fold | K-fold 純隨機切,Stratified 保持類別比例,不平衡資料用後者 |
總結:用命題思維準備中級科目二
AI 應用規劃師中級科目二(大數據處理分析與應用)這份考卷,真正在測的不是 50 個獨立的名詞,而是 6 個底層命題:
看懂分佈跟異常、資料形狀對應處理方法、依需求選對大數據架構、視覺化的數據密度原則、統計推論工具的選擇、pandas 與 seaborn 程式碼判讀。
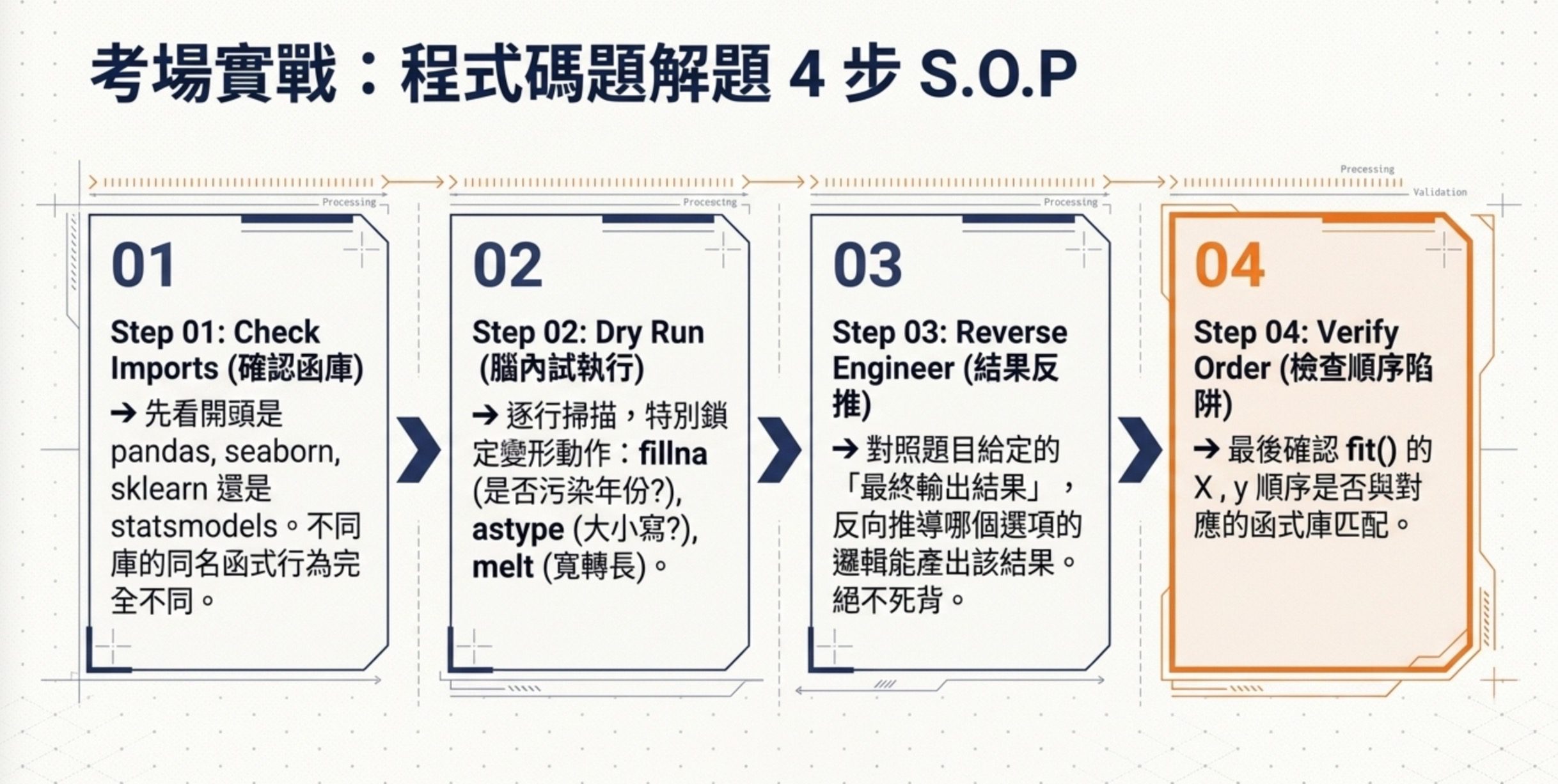
進考場的程式碼題解題流程,我建議固定這四步。
第一步,先看程式碼的 import 部分,確認用了哪個函式庫(pandas、seaborn、sklearn、statsmodels),不同函式庫的同名函式行為不同。
第二步,逐行讀程式碼,在腦中執行一次,特別注意 fillna、astype、groupby、melt 這幾個變形動作。
第三步,對照題目給的執行結果,看哪個選項才能產出那個結果。
第四步,記得 sklearn 跟 statsmodels 的 fit() 順序是相反的,sklearn 是 fit(X, y),statsmodels 是 sm.OLS(y, X).fit(),別搞錯。
iPAS AI 應用規劃師中級科目二的設計初衷,是檢核你能不能在大數據專案裡擔任分析規劃的角色。
能在六大命題之間做出正確判斷、能讀懂 pandas 跟 seaborn 的常見語法,就能通過科目二,祝各位考試順利!
考前白話詞表:科目二必考名詞(點擊展開)
| 名詞 | 白話翻譯 | 一句話理解 |
|---|---|---|
| Z-score | 離平均值幾個標準差 | Z=2 就是比平均高 2 個標準差 |
| 偏態 Skewness | 看尾巴往哪邊拖 | 右偏尾巴往右,左偏尾巴往左 |
| CDF | 累積機率 | 小於等於這個值的機率加總是多少 |
| PMF | 離散的單點機率 | 例如 Poisson 中「剛好 5 個瑕疵品」的機率 |
| Poisson 分佈 | 固定時間內事件發生幾次 | 例如每小時來電數、每小時瑕疵品數 |
| 二項分佈 | 重複做 n 次成功/失敗實驗 | 5000 人中有幾人點擊廣告 |
| 分位數迴歸 | 不只預測平均值,預測各百分位 | 適合看尾端風險 |
| Label Encoding | 類別硬編成數字 | 風險是模型可能誤以為 2 比 1「大」 |
| One-Hot Encoding | 每個類別各開一個 0/1 欄位 | 不造假順序,但類別多時欄位爆炸 |
| Min-Max Scaling | 壓到 0 到 1 | 好懂,但很怕極端值 |
| Robust Scaling | 用中位數與四分位距縮放 | 比較不怕極端值 |
| PCA | 把重疊特徵整理成幾條新軸 | 降維、減少重複資訊 |
| LASSO | 把不重要特徵的係數壓到 0 | 做特徵選擇 |
| Box-Cox | 把正值右偏資料轉接近常態 | 資料必須大於 0 |
| SMOTE | 在少數類附近插值造新樣本 | 不是複製,是合成 |
| ACID | 資料庫交易的四個保證 | 全成功或全失敗、規則一致、互不干擾、提交後不消失 |
| 同態加密 | 資料上鎖後還能計算 | 算完解鎖,結果跟原始資料算一致 |
| 資料湖 | 大型原始資料倉庫 | 文字、圖片、表格、感測器都先放進去 |
| 資料倉儲 | 整理好的分析資料庫 | 常用於報表、BI、管理決策 |
| Graph Database | 用「點」和「線」存資料 | 適合社群、推薦、詐欺偵測 |
| Heatmap | 用顏色深淺顯示數值大小 | 適合看相關係數矩陣 |
| p-value | 虛無假設為真時看到這麼極端結果的機率 | 越小越有理由拒絕虛無假設 |
| 信賴區間 | 用樣本估計真實值可能落在哪 | 95% 信賴區間不是「95% 機率包含真值」 |
| 雙比例 Z 檢定 | 比較兩組比例是否不同 | 例如兩條產線良率是否有差 |
| Pearson 相關係數 | 兩個連續變數的線性關係強度 | 接近 1 正相關,接近 -1 負相關 |
| Support 支持度 | A 和 B 同時發生佔多少比例 | 關聯規則的基礎 |
| Lift 提升度 | A 推 B 是否比隨機猜更強 | Lift 大於 1 表示正相關 |
| K-fold | 切 K 份輪流測試 | 減少單次切分的運氣成分 |
| Stratified K-fold | 切時保持類別比例 | 適合不平衡分類 |
| LOOCV | 每次只留 1 筆測試 | 總共跑 N 次,計算量大 |
| DBSCAN | 找密集群,孤單點當雜訊 | 不必先指定 K 群 |
| astype(‘Int64’) | pandas 可空整數型態 | 可以是整數,也可以保留缺值 |
| isna() | 檢查缺失值 | 跟 isnull() 在 pandas 裡是同義 |
| pd.melt() | 寬表轉長表 | 多欄變成「變數名稱+數值」兩欄 |
| fit(X, y) | sklearn 順序:先特徵再目標 | 不能反過來 |
| sm.OLS(y, X) | statsmodels 順序:先目標再特徵 | 截距通常要自己加 |
推薦閱讀
- [新手入門] 中級科目二:費曼學習法,7 個故事讓你讀完就懂
- iPAS AI 應用規劃師中級科目三:機器學習技術與應用 6 大核心命題
- iPAS AI 應用規劃師中級科目一:人工智慧技術應用與規劃 7 大核心命題
參考資料
iPAS 經濟部產業人才能力鑑定 (2025). AI 應用規劃師中級能力鑑定考試簡章
iPAS 經濟部產業人才能力鑑定 (2025). 114 年第二次 AI 應用規劃師中級能力鑑定公告試題第二科
pandas Documentation (2025). API reference
seaborn Documentation (2025). Statistical data visualization
Scikit-learn Documentation (2025). Preprocessing data
IBM (2025). What is Homomorphic Encryption
FAQ
AI 應用規劃師中級科目二跟科目一最大的差別是什麼?
科目一是純情境判斷題,科目二約有四分之一是程式碼或偽碼判讀題。你要會用 pandas 處理 NaN、用 seaborn 畫各種圖、用 sklearn 跟 statsmodels 跑迴歸。如果只懂概念但不會看 Python 程式碼,科目二會很吃力。
六大命題裡面該優先讀哪幾組?
優先讀程式碼判讀那組(12 題)跟大數據架構那組(10 題),加起來 22 題,佔分將近一半。即使對統計推論不熟,這兩組讀通也能有很穩定的及格基底。視覺化那組只有 3 題,投資報酬率沒那麼高。
程式碼判讀題該怎麼準備?
不要硬背 API,要從輸入輸出推回函式語意。建議實際打開 Jupyter Notebook 跑一遍範例,例如 `df[‘Year’].astype(int)` 跟 `df[‘Year’].astype(‘Int64’)` 在有 NaN 時行為的差別、`sklearn.LinearRegression().fit(X, y)` 跟 `sm.OLS(y, X).fit()` 的順序差別,跑過一次就不會忘。
PCA 前到底要不要標準化?
PCA 對量級敏感,當特徵的尺度差異很大(例如交易金額 10⁵、年齡 10²)時,不先標準化會讓量級大的特徵主導所有主成分。所以實務上 PCA 前幾乎一定要先標準化。LASSO 也類似,但更建議用樹模型避免完全依賴標準化的結果。
同態加密在 AI 應用規劃師中級科目二為什麼這麼常考?
因為它是資料在加密狀態下還能運算的唯一一種主流技術,在雲端外包運算、跨機構合作場景特別重要。題目通常用銀行、雲端服務商、跨銀行協作這些場景包裝,看到不解密就能運算的關鍵字直接選同態加密。但實務上同態加密計算成本高,所以常搭配 MPC、雜湊、對稱加密一起用。
考前最後一週怎麼複習最有效?
不要重看名詞解釋,改成做命題到題目的反向練習。隨機翻一題考古題,給自己 5 秒判斷它屬於六大命題的哪一組,再做答案。程式碼題每天練 3 到 5 題,實際在筆電上打一遍,比看十題還有效。