iPAS AI 應用規劃師中級科目一:人工智慧技術應用與規劃 7 大核心命題
科目一:人工智慧技術應用與規劃
這是考點命題拆解版,幫你抓中級科目一(人工智慧技術應用與規劃)的出題重點。如果你想先用白話故事讀懂,請看 [新手入門] 中級科目一:費曼學習法,7 個故事讓你讀完就懂。
我們把 50 題的題目情境全部剝掉,只看出題者真正想測什麼,會發現它一共只在問 7 個底層命題。
我們希望你學會這 7 個命題方式,進考場可以解任何變形題。
官方題目來源:https://ipd.nat.gov.tw/ipas/certification/AIAP/learning-resources
中級科目一不能背答案?
中級題型最強的一個設計,是它把同一個命題拆成多種產業情境去包裝。
NLP 命題的同一條判斷邏輯,可能在這份考卷包裝成電商評論、跨國金融翻譯、客服自動回覆、RAG 檢索增強或 Seq2Seq 摘要。
學會命題的人看到任何一題,就會想這題在問哪一個命題。
命題鎖定之後,答案會自動浮出來。這才是 iPAS 認證一個 AI 應用規劃師應該具備的判斷力,也是中級跟初級最大的差別。
中級科目一的 7 大核心命題地圖
我把 114 年第二次中級能力鑑定試題公告拆解後,歸納出命題地圖。
| 命題 | 出題者想測的判斷力 | 對應題號 |
|---|---|---|
| 文字怎麼變成語意 | 從詞頻到向量到情境化的演化邏輯,以及任務形狀怎麼決定模型選型 | 1, 2, 3, 4, 5, 6, 16, 17, 18, 33 |
| 影像與多模態任務的選型 | 影像粒度從分類、偵測到分割逐步加深,多模態是另一條軸:同時處理不同資料型態。生成式影像則看取樣設定與跨模態對齊 | 7, 8, 21, 34, 35, 38, 50 |
| 資料的形狀決定方法 | 連續、類別、半結構化、時序、高維各有對應的處理策略,以及指標跟任務的綁定 | 9, 10, 11, 12, 26, 27, 28, 36, 37, 45 |
| AI 系統與 MLOps 流程 | 部署服務、模型版本、CI 自動化、上線監控、驗證與調參流程,各環節用什麼工具、會出什麼問題 | 13, 14, 15, 22, 29, 31, 32, 41, 42, 46 |
| 生成式 AI 找根本原因 | 三大家族的生成邏輯差異,以及商用風險的真正源頭 | 19, 20, 25, 40, 43, 44 |
| AI 風險發生在五個層 | 部署、輸入、稽核、任務動態、資料代表性,各層治理手段不同 | 23, 24, 30, 47, 49 |
| 時間序列跟傳統 ML 的基本功 | ARIMA 殘差白噪音、DBSCAN 大規模優化 | 39, 48 |
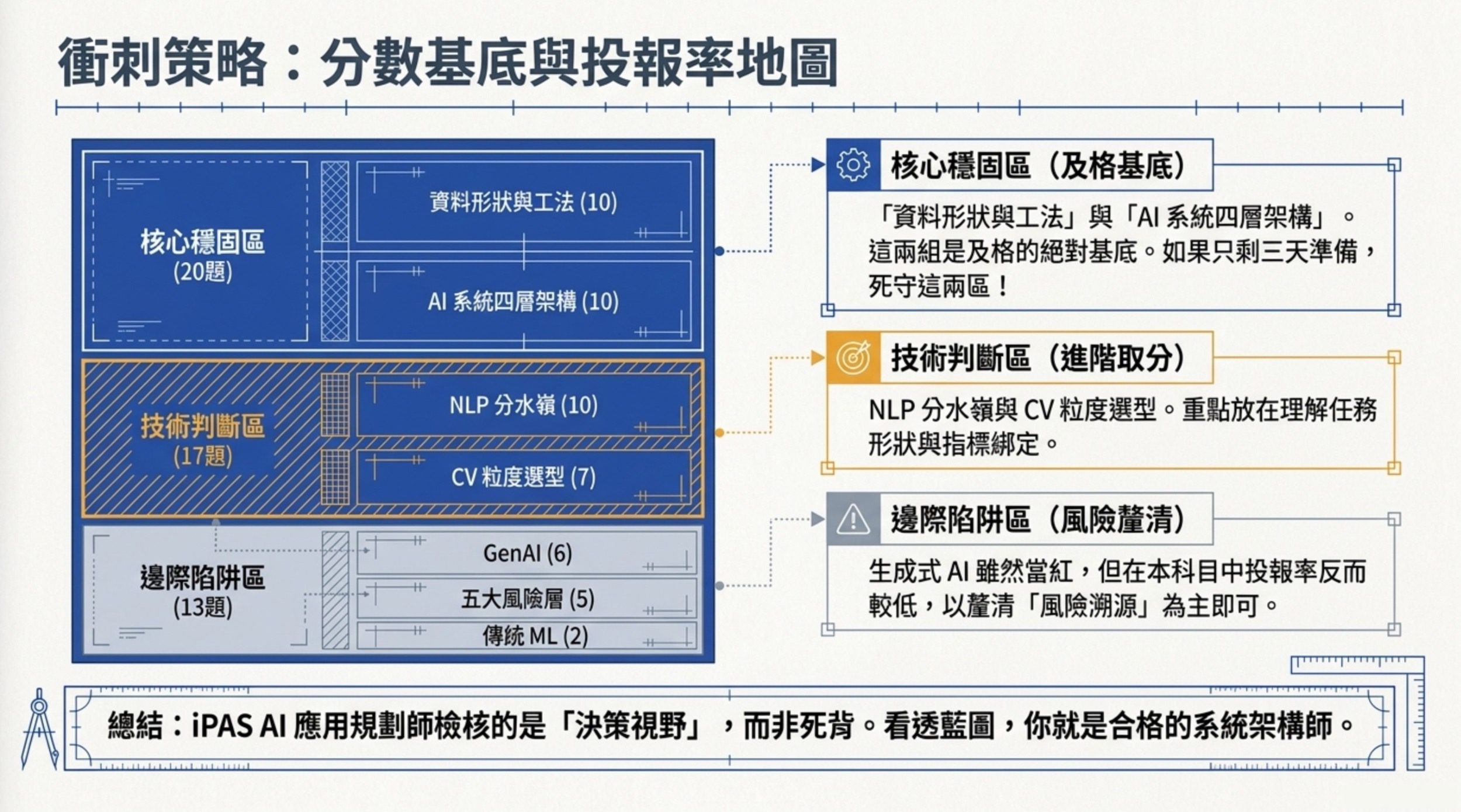
人工智慧技術應用與規劃這份考卷,在測你能不能把情境對應到正確方法。
資料處理跟系統架構這兩組命題加起來 20 題,如果你只剩三天讀,優先押這兩組。
1:文字理解的三道分水嶺與 RAG
這組 10 題的底層命題其實只有一句:電腦怎麼把人類的語言變成它能算的東西,而且還能保留意思。
NLP 的所有題目,都是在這個命題的不同階段問你問題。
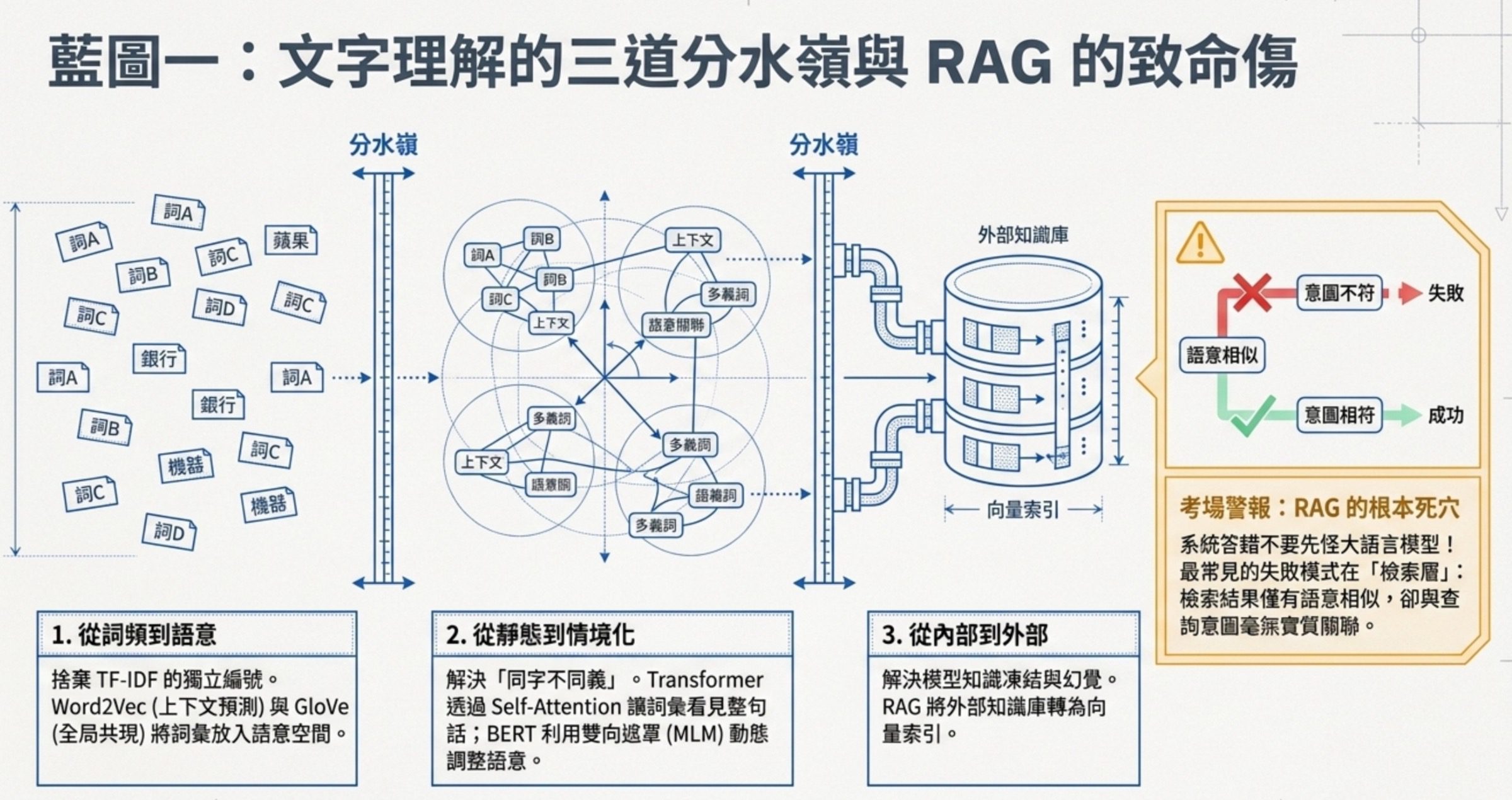
這個命題之所以重要,是因為它經過了三道分水嶺,每道分水嶺都解決了前一代的一個根本痛點,而出題者最愛考的就是這個技術解決了什麼前一代解不掉的問題。
第一道分水嶺是從詞頻到語意。最早的做法是 TF-IDF,把一個詞在這篇文章出現多少次跟在整個語料庫多稀有算個權重,聽起來合理,但有個破綻:它把每個詞當獨立編號,語意上接近的兩個詞(像是貓跟狗)跟語意完全無關的兩個詞(像是貓跟銀行),在它眼裡距離一樣遠。
Word2Vec 跟 GloVe 為了解這件事就出現了,把詞放進一個語意空間,讓貓跟狗自然會靠近。
兩者差別只是 Word2Vec 用上下文預測學、GloVe 用全局共現統計學,結果都是把詞變成有語意的向量。
第二道分水嶺是從靜態到情境化。Word2Vec 解決了貓跟狗該靠近,但又留了一個新問題:同一個字在不同句子裡意思不一樣。銀行這個字出現在金融句子跟河岸句子裡,Word2Vec 給的是同一個向量。
Transformer 的 self-attention 機制解決這件事,讓每個詞的表徵會看整句話的其他字、動態調整自己的意思。
BERT 進一步用遮罩語言模型來訓練這套機制,隨機遮住句子中的部分詞,讓模型同時看左邊與右邊的上下文來猜被遮住的詞,這就是雙向上下文。
第三道分水嶺是從模型內知識到外部知識。Transformer 雖然強,但它的知識是凍結在訓練資料裡的,會過時、會幻覺。
RAG 出現是為了解這件事,把外部知識庫做成向量索引,使用者問問題的時候先去檢索相關文件,再把檢索結果丟給語言模型生成答案。
掌握這三道分水嶺,你就能看出 NLP 任務的形狀對應什麼模型架構。
情感分析是文字進、類別出,屬於分類任務。
翻譯跟摘要是文字進、文字出,而且輸出是另一段連貫的序列,屬於序列轉序列(Seq2Seq)任務。
N-gram 是還沒過第一道分水嶺的舊技術,因為它只看固定窗口的前序詞,所以片段合理但整體不連貫。
示範解題:以 RAG 檢索失敗為例
這組我挑題 17 來示範完整推理過程,選這題的原因是它最能展現不要怪大模型,先看 AI 系統卡在哪一層這個 AI 應用規劃師最該有的判斷力。

題目情境是這樣:你要建一套高效能的 RAG 系統,問你在檢索階段最關鍵的挑戰是什麼。
四個選項包括:
(A)上下文視窗大小
(B)Faiss/ScaNN 函式庫選擇
(C)嵌入模型計算成本
(D)避免檢索結果只是語意相似但跟查詢意圖無實質關聯。
推理過程:
第一步,先把題目分到命題,RAG 是從模型內知識到外部知識這道分水嶺的產物,它解決的根本問題是模型本身知識有限。所以這題的命題是 RAG 為什麼需要存在、它的成敗關鍵在哪。
第二步,想 RAG 的兩階段架構:檢索 + 生成。題目限定了問檢索階段,所以生成階段的問題(上下文視窗、生成幻覺)不在這題的範圍裡,馬上排除上下文視窗這個選項。
第三步,想檢索階段會出什麼錯,檢索拿回來的文件如果跟查詢意圖無關,後面 LLM 再強也救不回來,因為它沒看到真正相關的資料。這就是 RAG 系統最常見的失敗模式,叫做語意相似但意圖無關。(舉個例子,使用者輸入的查詢是公司的退貨政策,檢索系統可能因為兩邊都有退貨這個字眼,就找到一堆退貨案例討論,但使用者真正想要的是公司政策文件這份特定的東西。)
第四步,看剩下的選項,Faiss/ScaNN 選擇是工程細節、嵌入計算成本是效能議題,這兩個雖然重要,但都不是檢索失敗的根本原因,所以答案是 D。
這個命題的變形題:
同一個底層命題在這份考卷還包裝成另外九個樣子。
題 1 用電商評論包裝情感分析、題 2 用跨國金融翻譯包裝 Transformer 的 self-attention、題 3 用客服回覆包裝 BERT 的 MLM、題 4 跟題 33 用詞向量訓練差異包裝 Word2Vec vs GloVe 跟 Skip-gram vs CBOW、題 5 用顧客意見包裝 TF-IDF 的長文本失準、題 6 用自動回覆包裝 N-gram 的長距離依賴、題 16 用任務情境包裝 Seq2Seq、題 18 用 Attention Collapse 包裝注意力機制的細節。學會三道分水嶺加上任務形狀對應,你能自己把這 10 題從頭推一遍。
2:影像與多模態任務的粒度決定技術選型
這組 7 題的底層命題其實有兩層:影像任務的粒度直接決定技術選型,而多模態跟生成式影像的問題,根本原因常常落在跨模態對齊跟取樣設定。把這兩層串起來,題 7、8、34 的粒度題,跟題 21、35、38、50 的多模態與生成題,就能一次處理。
這兩層命題藏在每一題影像或多模態題的背後,出題者不會直接問什麼是影像分割,他會給你一個產業情境,描述模型要做什麼事,然後問你選哪個技術或哪個指標,學生要做的是把情境裡的要求粒度抓出來,直接對應到正確答案。
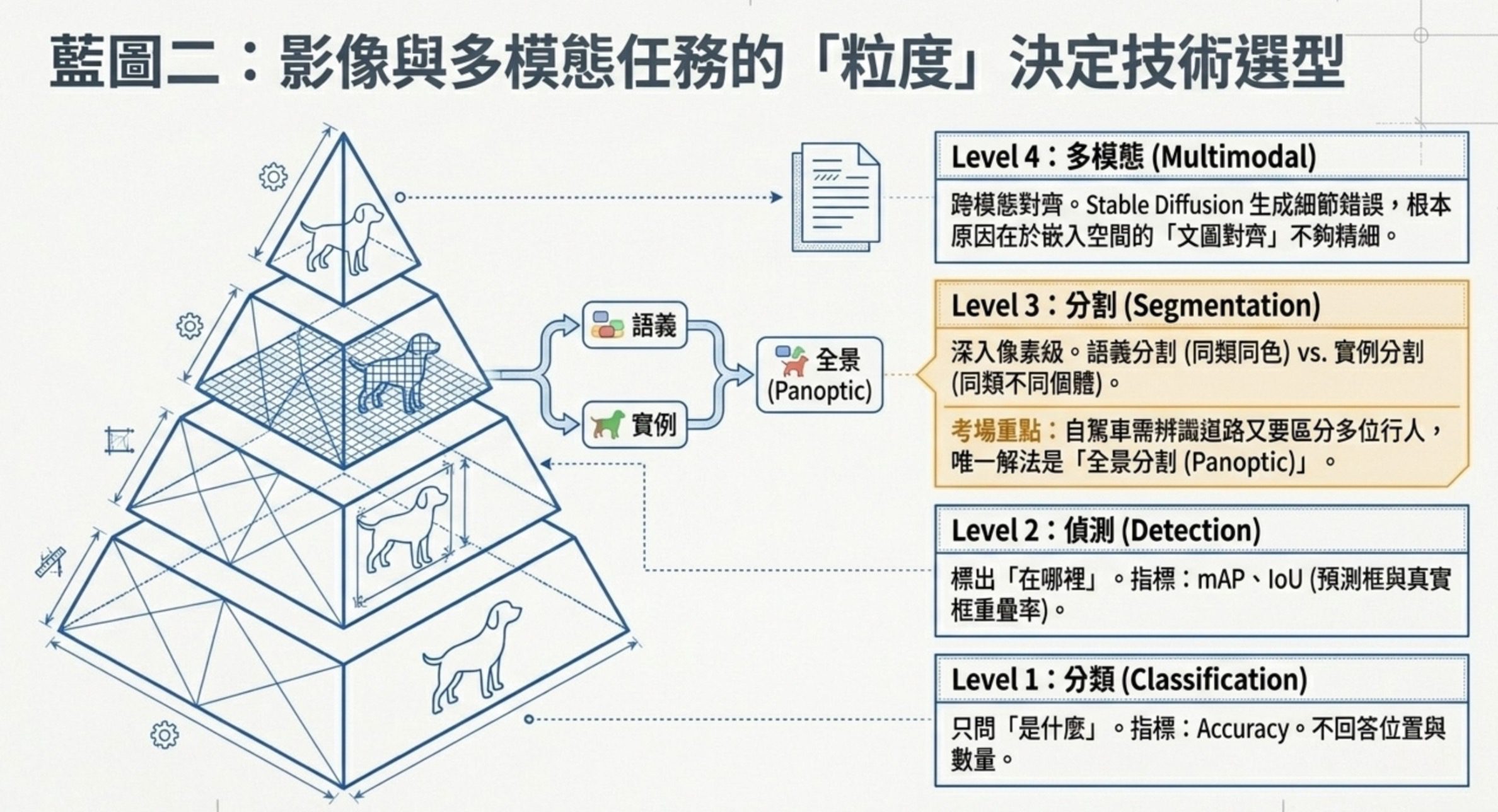
影像任務可依粒度分層,多模態則是另一條資料型態軸:
第一層是影像分類。輸入一張圖,輸出整張圖屬於哪一類。常見指標是 Accuracy(類別平衡時)或 F1(類別不平衡時)。模型只回答這張圖是什麼,不回答位置、不回答數量、不回答像素。
第二層是物件偵測。模型不只說有什麼,還要把位置框出來。指標是 mAP 跟 IoU,IoU 衡量預測框跟真實框的重疊比例,值越高代表框得越準。智慧監控、自駕車的人車辨識都是這層。
第三層是影像分割,可以再分三種子層級,語義分割告訴你每個像素屬於哪一類,所有的人都染同一個顏色。實例分割不只標類別,還區分同類的不同個體,人 A 跟人 B 染不同顏色。全景分割是兩者合一,既標像素類別又區分個體。自駕車要同時辨識像素類別跟區分多位行人,只有全景分割能做。
第四層是多模態。模型同時處理影像跟文字,CLIP 是代表作,它用對比式學習把文字跟影像映射到同一個嵌入空間,所以文字跟影像可以直接算語意相似度,也因此能做零樣本分類。
生成式影像是這個命題的延伸,Stable Diffusion 之類的擴散模型可以根據文字生成圖片,但有個老問題:主題能對、細節常錯。品牌標誌顏色不對、手部姿勢不自然,在本題選項中,最符合題意的是 CLIP 文字與影像編碼器在語意嵌入空間未充分對齊。但實務上,品牌標誌錯誤與手部異常可能還涉及訓練資料分布、局部結構學習、生成模型細節控制等因素,品牌跟手部這類細節特別仰賴文圖對齊。
示範解題:以自駕車的全景分割為例
挑題 34 來示範,因為這題最能展示粒度判斷的推理過程。

題目情境:自駕車影像辨識系統,要求模型同時辨識每個像素的物件類別(道路、建築、行人),又要區分同類物件的不同個體(多位行人),問該用哪個電腦視覺技術。
推理過程:
第一步,把題目的兩個要求拆出來,一個要求是每個像素的類別,一個要求是同類不同個體。
第二步,對應到粒度層級:每個像素的類別,直接想到分割。語義分割能做。但同類不同個體這個要求,語義分割做不到,它會把所有行人染同一個顏色。實例分割能做到個體區分,但它只處理物件、不處理背景(道路、建築)。
第三步,確認唯一同時滿足兩個要求的選項是全景分割,它既標像素類別又區分個體,是語義加實例的合體,所以答案是 D。
這個命題的變形題:
題 7 用智慧監控包裝物件偵測的 IoU、題 8 用 Softmax vs Max-Pooling 包裝細節操作的差異、題 21 用多模態缺資料包裝能感知缺模態的模型、題 35 用 CLIP 包裝跨模態嵌入空間、題 38 用 Stable Diffusion 4K 細節糊化包裝取樣步數、題 50 用品牌標誌跟手部錯誤包裝文圖對齊問題。學會影像粒度分層加上文圖對齊的概念,這 7 題你能自己推。
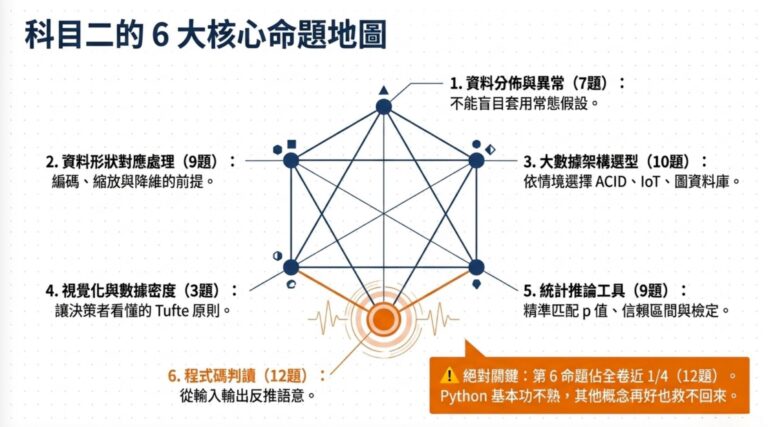
3:資料的形狀決定方法
這組 10 題佔分最重,也最容易被選項繞昏,但底層命題只有兩句:資料的形狀決定你該用什麼處理方法,任務的類型決定你該用什麼指標。人工智慧技術應用與規劃這份考卷的所有處理題跟評估題,都是在問這兩句話的具體應用。
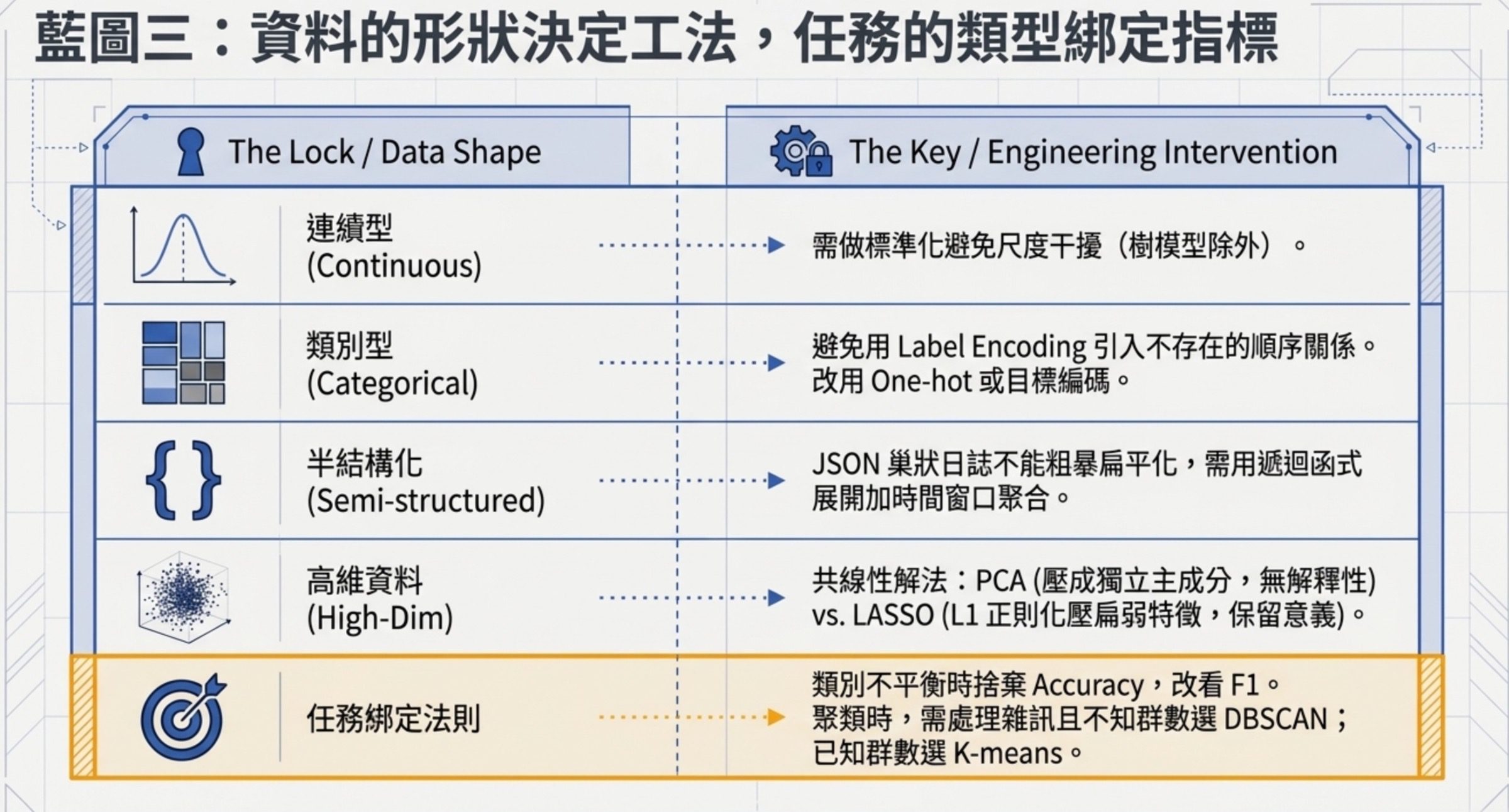
資料的形狀,可以分五種:
連續型(身高、體重、價格)在距離式、線性模型跟神經網路裡通常要先做標準化,因為不同特徵的尺度差異會干擾學習。樹模型對尺度不敏感,可以不做。
類別型(職業、地區)直接用 Label Encoding 編成數字會引入不存在的順序關係,模型會以為 1 跟 2 的距離跟 2 跟 3 的距離一樣有意義,尤其在線性、距離式、神經網路模型裡要小心,通常改用 One-hot 或目標編碼。樹模型對 Label Encoding 比較寬容,但題目情境不指明模型時,還是用 One-hot 或目標編碼比較穩。
半結構化(JSON 日誌)有巢狀欄位,不能粗暴扁平化,要設計遞迴函式展開欄位再用時間窗口聚合。
時序資料要做窗口切分跟時間特徵萃取。
高維資料訓練慢、易過擬合,要降維。
降維有兩條路,如下:
PCA 是無監督的維度轉換,把相關特徵壓成正交的主成分,適合純粹要降維、不需要可解釋性的場景。
LASSO 是有監督的特徵選擇,用 L1 正則化把不重要的特徵係數壓到零,適合需要保留原始特徵意義的場景。多重共線性(特徵彼此高度相關)會讓線性迴歸的係數變得不穩定。PCA 和 LASSO 都能處理共線性造成的建模困擾,但機制不同:PCA 是把相關特徵轉成較少的主成分;LASSO 則透過 L1 正則化壓低部分係數進行特徵選擇。
評估這邊,指標跟任務類型綁死。
分類任務看 Precision 跟 Recall 的綜合,選 F1;單看 Accuracy 在資料不平衡時會騙人。迴歸任務看 RMSE 或 MSE。聚類任務裡 DBSCAN 跟 K-means 的差別最常考,DBSCAN 靠密度自動區分主群跟雜訊,參數是 Epsilon(鄰域半徑)跟 MinPts(核心點最少鄰居),它不需要事先決定 K。
資源限制是這個命題的工程面。
GPU 記憶體不足,核心是不要硬塞,解法是減少 batch size、用資料分片、混合精度、gradient checkpointing。提高學習率不會解決記憶體問題反而更不穩。超參數搜尋空間大,系統化測試用 Grid Search、快速探索用 Random Search、根據歷史結果動態調整用 Bayesian Optimization。
示範解題:以房價預測的多重共線性為例
挑題 12 示範,因為它最能展示從資料形狀直接推方法這個判斷邏輯。

題目情境:金融科技公司建房價預測模型,用建坪、房齡、樓層、總價等多個特徵做線性迴歸。發現特徵之間存在高度相關性,導致模型係數不穩定、預測誤差上升,問用什麼方法解決。
推理過程:
第一步,辨識題目給的訊號,多個特徵之間存在高度相關性、導致模型係數不穩定,這是多重共線性的標準描述。多重共線性是線性模型的死穴。
第二步,想多重共線性的解法,兩條路,PCA 或 LASSO。題目要的是將相關特徵轉換為彼此獨立,這是 PCA 的招牌動作:把相關特徵壓成正交的主成分。LASSO 的做法是壓係數,沒有轉換為獨立特徵這個動作,所以這題答案是 PCA。
第三步,排除誘餌選項,繼續保留所有特徵不處理直接違反題目要求、新增更多原始變數會讓共線性更嚴重、改用分類模型是換問題不是換方法。答案是 B。
這個命題的變形題:
題 9 用資料增強包裝分布變了會傷害模型、題 10 用 F1 包裝指標選擇、題 11 用 DBSCAN 包裝聚類超參數、題 26 用 LASSO 包裝共線性的另一條解法、題 27 用 JSON 日誌包裝半結構化資料處理、題 28 用連續+類別包裝混合特徵工程、題 36 用 Grid Search 包裝超參數搜尋策略、題 37 用 GPU 記憶體包裝資源限制、題 45 用 PCA 加 SVM 包裝降維的工程意義。學會形狀對應方法、指標對應任務就能自己推完這 10 題。
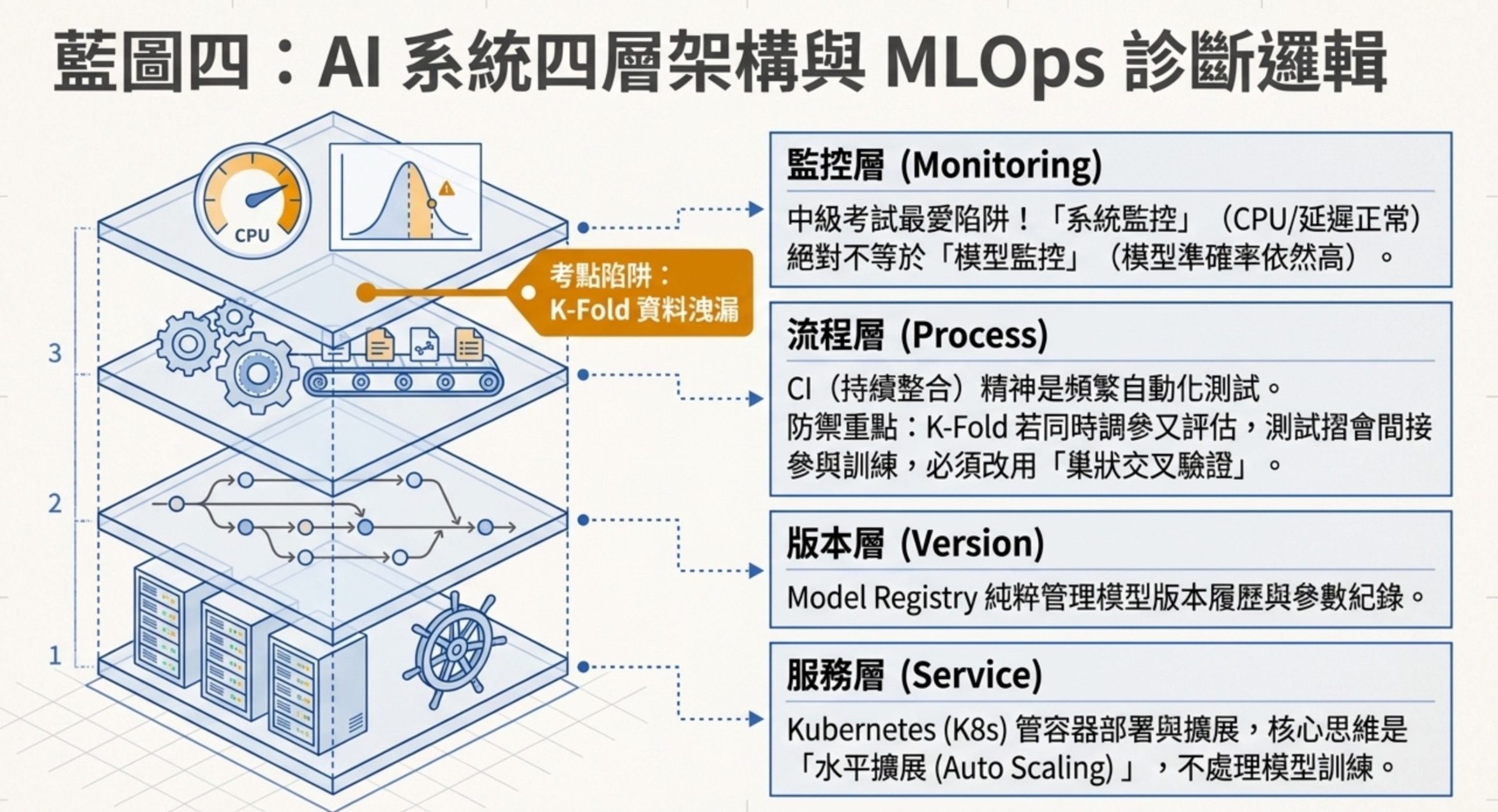
4:AI 系統與 MLOps 流程
這組 10 題的底層命題只有一句:AI 系統不是訓練完就結束,它有四層架構,每一層出問題對應到不同的工具跟監控方法。這是人工智慧技術應用與規劃這個科目裡 MLOps 真正在考的東西,也是把 AI 從模型變成服務的關鍵思維。
四層架構是這樣的:
第一層是服務層。模型訓練完要變成可用的 API,要能應付高流量、能擴展、能容錯。Kubernetes 是這層的工具,它管容器化模型服務的部署、擴展、運行環境。Kubernetes 的考點是容器化服務部署、擴展與運行環境管理。它不是模型版本管理工具,也不是訓練資料治理工具。高流量服務的核心思維是水平擴展(多開幾個服務實例)加 Auto Scaling,而不是垂直擴展(換更強的單機)。
第二層是版本層。每次重新訓練都產生一個新版本,要記錄這個版本用什麼資料、什麼參數、評估指標多少、現在是上線版還是備用版。Model Registry 是這層的工具,它純粹管模型版本履歷。
第三層是流程層。AI 開發跟一般軟體開發一樣需要版本控制跟自動化檢查。CI(持續整合)的核心精神是每次提交都自動觸發建置、單元測試、靜態分析,小步快跑頻繁整合,而不是每天定時手動合併。
第四層也是中級最愛考的一層,是監控層。AI 服務上線之後最大的風險,是系統看起來正常但模型已經失準。所以監控要分兩種:系統監控看 CPU、記憶體、延遲,告訴你服務還活著嗎;模型監控看輸入分布、輸出分布、置信度,告訴你模型還準嗎。系統正常但模型不準的情況非常常見,只看系統監控的團隊會錯過所有真正的問題。
模型失準有兩個根本原因,中級題目最愛分這兩者:
資料漂移(Data Drift)是輸入資料的分布變了,但輸入跟輸出的關係沒變。例如顧客年齡層慢慢從 25-35 變成 35-45,但年齡跟流失率的關係不變。
概念漂移(Concept Drift)是輸入跟輸出的關係本身變了,例如疫情前常出差的人是高消費客戶、疫情後就不成立。
偵測資料漂移有幾種方法:KL Divergence 比較兩個機率分布的差異、PSI 衡量人口穩定度(金融業常用)、用 VAE 監控潛在空間的偏移。
驗證流程的資料洩漏是這組的另一個陷阱。K-Fold 交叉驗證如果同時拿來選超參數又評估最終效能,測試摺資料間接參與了參數選擇,最後評估會過度樂觀。正確做法是巢狀交叉驗證(外層評估、內層調參)。
示範解題:以系統正常但模型不準為例
挑題 46 示範,因為它最能展示先分層、再找對應監控這個 AI 應用規劃師的核心判斷力。
題目情境:電商顧客流失預測模型上線數個月後準確率下降,但系統運作正常、未出現錯誤訊息。經分析發現輸入資料分布與訓練資料相比顯著偏移。問在 MLOps 流程中主動偵測並預警此類問題,最應該做什麼。
推理過程:
第一步,把問題分到層。系統運作正常但模型準確率下降這句話是關鍵,它直接告訴你問題不在前三層(服務、版本、流程),而在第四層(監控)。而且不是系統監控,是模型監控。
第二步,在第四層裡再分。模型失準兩種原因,題目給的訊號是輸入資料分布偏移,直接指向 Data Drift。如果輸入跟輸出的關係也變了,還要加 Concept Drift。
第三步,看選項裡哪個對應到Data Drift / Concept Drift 監測機制。答案 A 直接寫了這件事。其他選項量化降低延遲是優化效能、超參數調整次數是訓練層的事、固定隨機種子是訓練穩定性,通通跟監控漂移沒關係。答案是 A。
這個命題的變形題:
題 13 用 Kubernetes 包裝服務層、題 14 用超參數調整加交叉驗證包裝過擬合預防、題 15 用 Model Registry 包裝版本層、題 22 用 KL Divergence 包裝資料漂移偵測、題 29 用 CI 包裝流程層、題 31 用 10,000 RPS 包裝高流量架構、題 32 用 PSI 包裝最具預測效力的監控指標、題 41 用 K-Fold 同時調參跟評估包裝資料洩漏、題 42 用 VAE 監控潛在空間包裝另一種漂移偵測方式。把四層架構記在腦中當地圖,這 10 題每題都有它的位置。
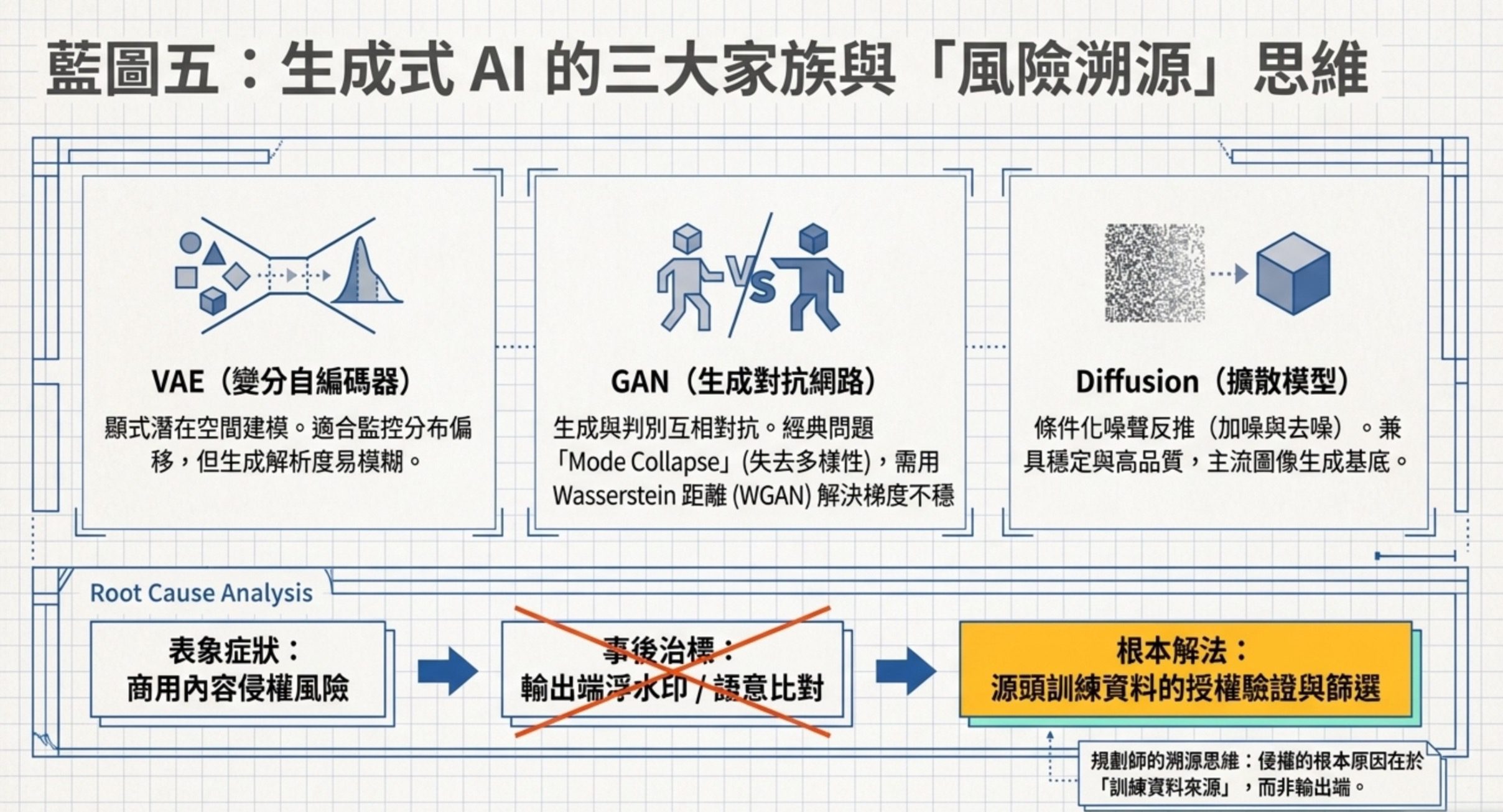
5:生成式 AI 找根本原因
這組 6 題的底層命題很特別,它考的不是技術細節,而是 AI 應用規劃師遇到生成式 AI 的問題時,有沒有能力找到根本原因。問題的表象往往是輸出不對,但根本原因可能在訓練資料、模型家族選擇、訓練動態,完全不同層。人工智慧技術應用與規劃這個科目用這組題目測你能不能跳過表象、抓到真正的風險源頭。
要學會這個命題,先要能分辨三大生成模型家族。
VAE(變分自編碼器)用顯式潛在變數建模。它把輸入壓縮到潛在空間,再從潛在空間解回來,潛在空間是顯式且結構化的。所以 VAE 很適合做跨模態對齊、潛在空間操作、監控分布偏移,但生成解析度有限,圖會比較糊。
GAN(生成對抗網路)用對抗訓練。生成器造假、判別器抓假,兩者互相進步。GAN 生成品質可以做到很高,但訓練不穩定,經典問題叫 Mode Collapse:生成器發現某幾個樣本特別容易騙過判別器就一直產出同一種樣本,失去多樣性。解 Mode Collapse 最常用 WGAN,把損失函數換成 Wasserstein 距離,訓練梯度比較穩。
Diffusion(擴散模型)用條件化噪聲反推。訓練時把資料逐步加噪聲變成純雜訊,生成時從純雜訊逐步去噪變回有意義的資料。Diffusion 兼具穩定跟多樣,在文字生成影像這類高品質影像任務裡,近年已經成為很常見的主流做法。Stable Diffusion 是典型擴散模型。DALL·E 不同版本架構不同:原始 DALL·E 偏自回歸 Transformer,DALL·E 2 才使用 diffusion decoder。
三者的根本差異是:VAE 學潛在空間、GAN 做對抗、Diffusion 做去噪。它們不共享同一個潛在空間,也不都用對抗訓練,也不都用馬爾可夫鏈。任何把三者說成都用同一種機制的選項都是錯的。
找根本原因這個命題還有兩個重要應用面。在這題情境中,資料少且已過擬合,單純加大模型容量不是最佳解法,要想資料增強跟反向翻譯。反向翻譯是用現有模型把單語資料翻成另一種語言,生成偽平行語料補充訓練,對低資源語言特別有效。商用內容侵權風險的根源是訓練資料來源,不是輸出端的浮水印或相似度比對,那些是事後偵測或處理,根源要回到訓練資料。
示範解題:以行銷內容侵權為例
挑題 25 示範,因為它最能展示不要被表象選項騙這個判斷力。
題目情境:企業部署生成式 AI 系統協助行銷與內容產出,被質疑部分生成內容涉及著作權侵權。為降低法律風險,問哪一項策略最能有效預防侵權問題產生。
推理過程:
第一步,辨識題目要的是預防不是事後處理。預防意思是從源頭杜絕,而不是輸出後再補救。
第二步,看四個選項各自在處理哪一層。語意相似度比對是輸出端的事後檢查、差分隱私是訓練端的防記憶機制、浮水印是輸出端的可追溯標記,只有訓練資料篩選與授權驗證是從源頭管控。
第三步,問自己:侵權的根本原因在哪?答案是訓練資料裡有未授權的東西。源頭管控是預防侵權最關鍵的一步,所以根本解是篩選授權,其他三個都是補強,所以答案是 B。
實務上,源頭管控仍會搭配輸出端的審核、相似度比對跟可追溯紀錄一起用,只是這題問的是哪個策略最能預防,源頭管控是唯一從根上解決的選項。
這個命題的變形題:
題 19 用低資源語言包裝資料不足的解法、題 20 用 GAN 人臉生成包裝 Mode Collapse 跟 WGAN、題 40 用三大模型對比包裝家族差異、題 43 用 VAE vs BERT Classifier 包裝低資源比較實驗設計、題 44 用電信顧客流失加 A/B 測試包裝同時要預測跟生成的場景。學會三大家族 + 找根本原因的思維,這 6 題你能自己過。
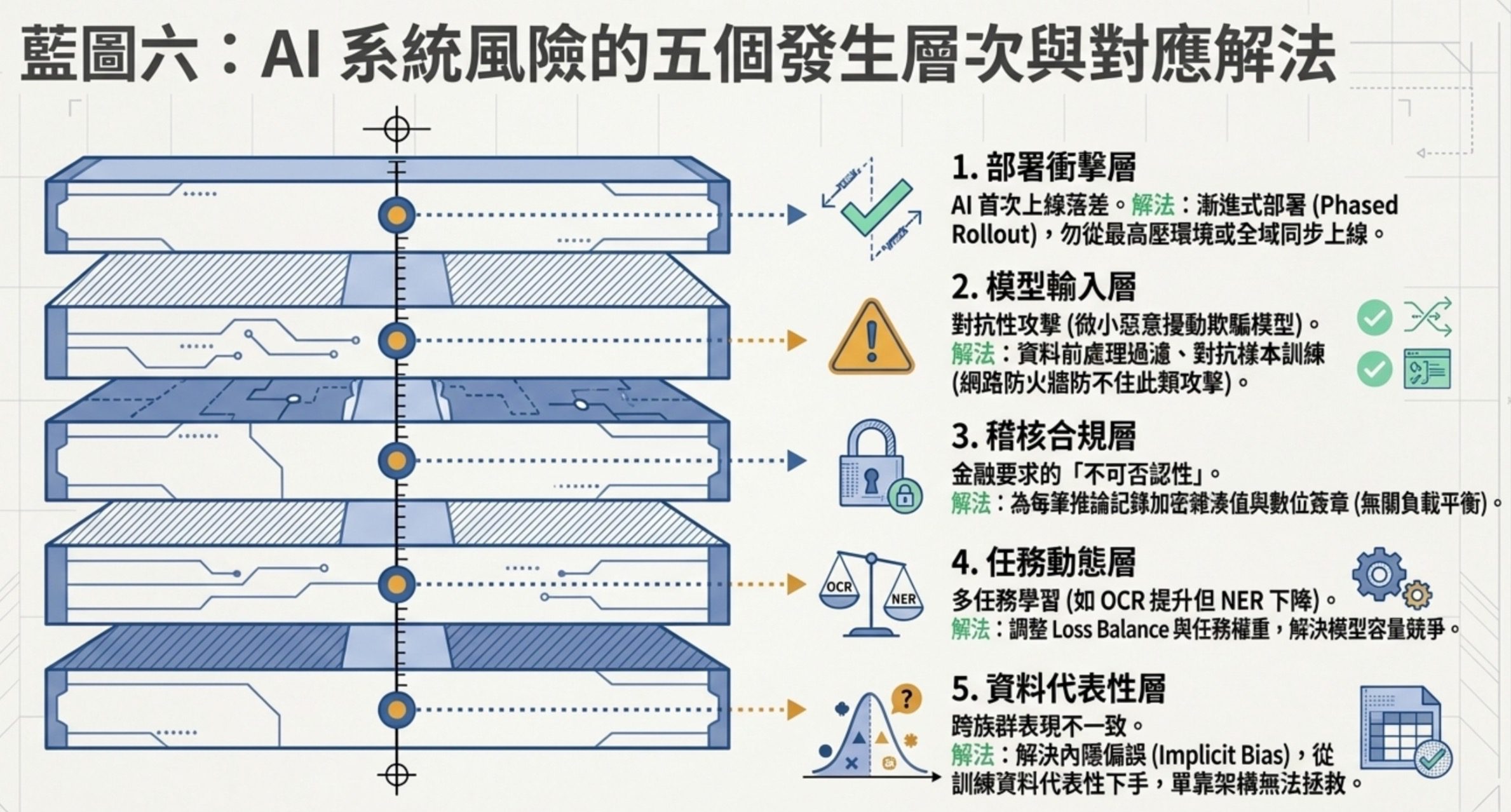
6:AI 風險發生在五個層
這組 5 題的底層命題是:AI 系統的風險不只一種,規劃師要能在 5 秒內判斷風險發生在哪一層,因為每一層的治理手段完全不同。人工智慧技術應用與規劃的這組題目會用醫療、金融、跨族群這些高風險場景包裝,選項裡塞一堆看似合理的 IT 名詞,你要分清楚哪個真的對應到題目的風險層。
五個風險層是這樣:
部署衝擊層。AI 系統第一次上線,實際表現跟測試環境會有落差,而且這個落差會放大臨床或業務衝擊。對應的治理手段是漸進式部署(Phased Rollout),從單一專科或特定病房開始、逐步擴展到全院。先在急診(壓力最大)上線是錯的、全院同步上線風險擴散最大。
模型輸入層。對抗性攻擊是駭客對輸入特徵做微小但惡意的擾動,讓模型產生錯誤輸出。注意:這發生在模型的輸入端,不是網路連線端。對應的治理手段是資料前處理過濾、對抗樣本訓練、推論後規則引擎。網路防火牆防的是另一回事。
稽核合規層。金融監管要求不可否認性,意思是事後不能讓任何一方否認自己做過某個操作。對應的治理手段是為每筆推論記錄輸入跟輸出的加密雜湊值、簽署數位簽章。降低延遲、增加備援、負載平衡都是效能議題,跟不可否認性沒關係。
任務動態層。多任務學習裡,同一個模型同時做兩個任務,有時候 A 進步 B 退步,因為兩個任務在搶模型容量。對應的治理手段是調 loss balance、做任務權重的動態調整。錯誤選項常常說成架構不支援、BERT 不能多任務,那是技術上不對的描述。
資料代表性層。AI 對不同族群表現不一致,根本原因是訓練資料代表性不足或內隱偏誤(Implicit Bias)。Transformer 架構本身能捕捉上下文,但訓練資料偏了,模型還是會學到偏誤。這層的治理是資料層的事,不是改一個技術 flag 就好。
示範解題:以多任務學習任務競爭為例
挑題 47 示範,因為它最能展示分清楚問題層這個判斷力。

題目情境:金融科技公司用單一 Transformer 同時做 OCR 後的文件分類跟 NER。部署初期發現 NER 準確率提升時、文件分類準確率反而下降。架構正確、資料品質良好。問最可能造成此現象的原因。
推理過程:
第一步,辨識題目給的關鍵限制:架構正確、資料品質良好。這直接排除了架構問題跟資料問題兩類選項。
第二步,辨識題目的現象:一個任務上升、另一個任務下降。這是典型的多任務學習任務競爭模式。
第三步,想任務競爭發生在哪一層。發生在訓練動態,具體是 loss 沒平衡好,兩個任務的梯度在搶模型容量。
第四步,排除其他選項。架構無法同時支援直接被題目排除、分類不需要語意化表徵是錯誤敘述、BERT 不支援多輸出頭也是錯的。答案是 C。
這個命題的變形題:
題 23 用醫院 AI 系統包裝漸進式部署、題 24 用金融風控加對抗性攻擊包裝模型輸入層、題 30 用銀行 AI 詐欺偵測包裝稽核合規層、題 49 用情感分析跨族群不一致包裝資料代表性層。五個風險層記熟,這 5 題每題你都能直接定位。
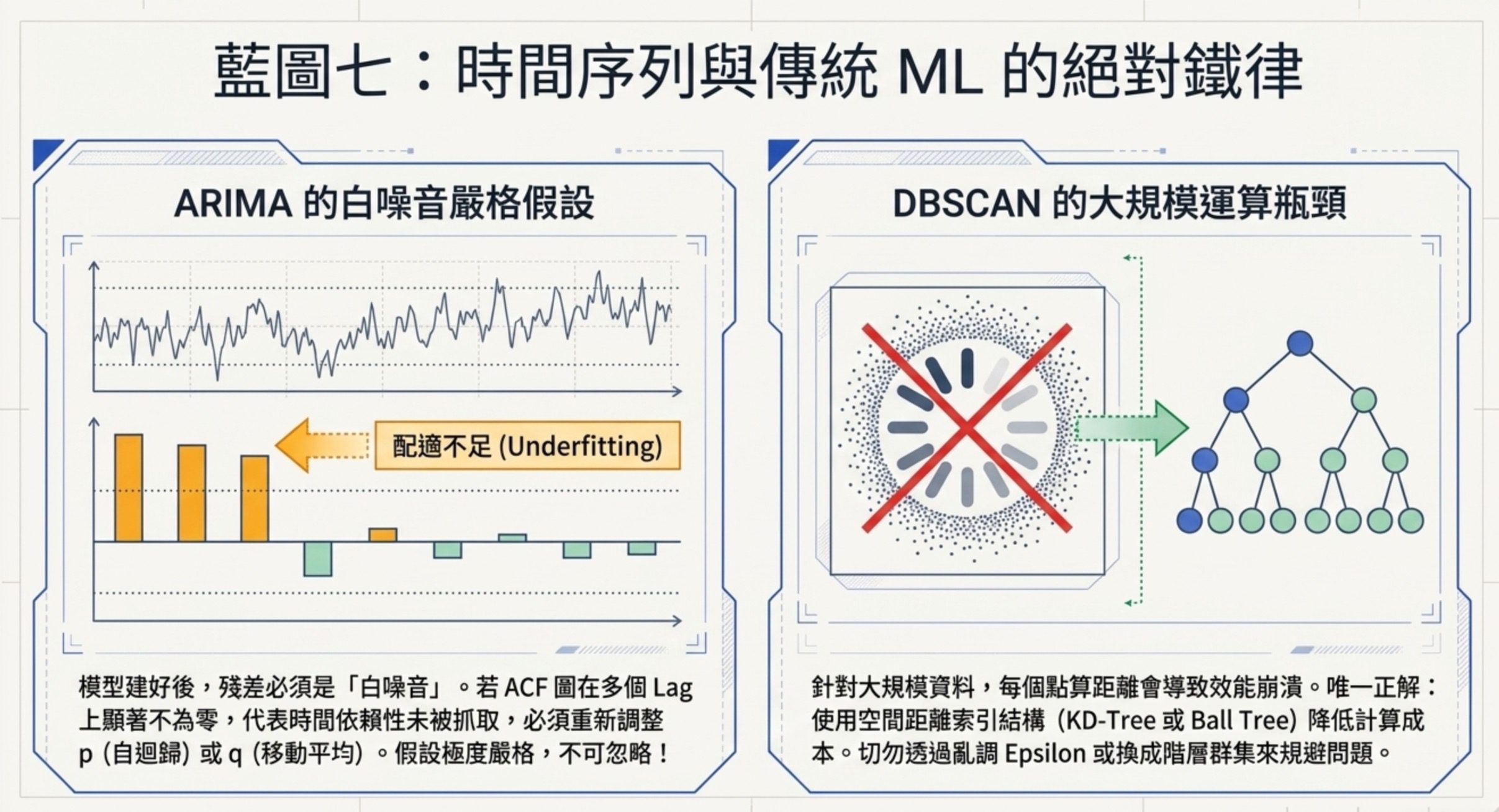
7:時間序列跟傳統機器學習
這組只有 2 題,佔分很少,但都是送分題,規劃師不應該掉。底層命題是兩句:ARIMA 殘差白噪音假設是嚴格的、DBSCAN 大規模問題用空間索引解。
ARIMA 是時間序列預測的經典模型,它假設序列可以用自迴歸 + 差分 + 移動平均三個部分描述。模型建好之後,診斷的核心是看殘差。理想狀況下殘差應該是白噪音:沒有自相關、平均值為零、變異數固定。
如果殘差的 ACF 在多個 Lag 上仍顯著不為零,代表殘差裡還藏著沒被模型抓到的時間依賴性。這是配適不足(Underfitting),要重新調整 p(自迴歸階數)或 q(移動平均階數)。白噪音假設是嚴格的,不能用殘差有點異常但可忽略這種話帶過。
DBSCAN 在大規模資料上會很慢,因為每個點都要算跟其他點的距離。就考題給的選項而言,不改演算法核心邏輯的最佳解法是用 KD-Tree 或 Ball Tree 這類距離索引結構降低距離計算成本。不要把 Epsilon 調極小或改用階層式群集,那是換問題不是解問題。實務上要補一點:KD-Tree 跟 Ball Tree 在低中維度效果好,維度太高時索引效率本身也會下降,真實大規模高維場景常需要近似最近鄰搜尋(ANN)的工具,例如 FAISS。考試選項裡通常不會把這層放進來,認準距離索引這個方向即可。
這兩個底層原理直接對應題 39(ARIMA 殘差有結構,要調 p 或 q)跟題 48(DBSCAN 大規模用 KD-Tree 或 Ball Tree),沒什麼變形空間。
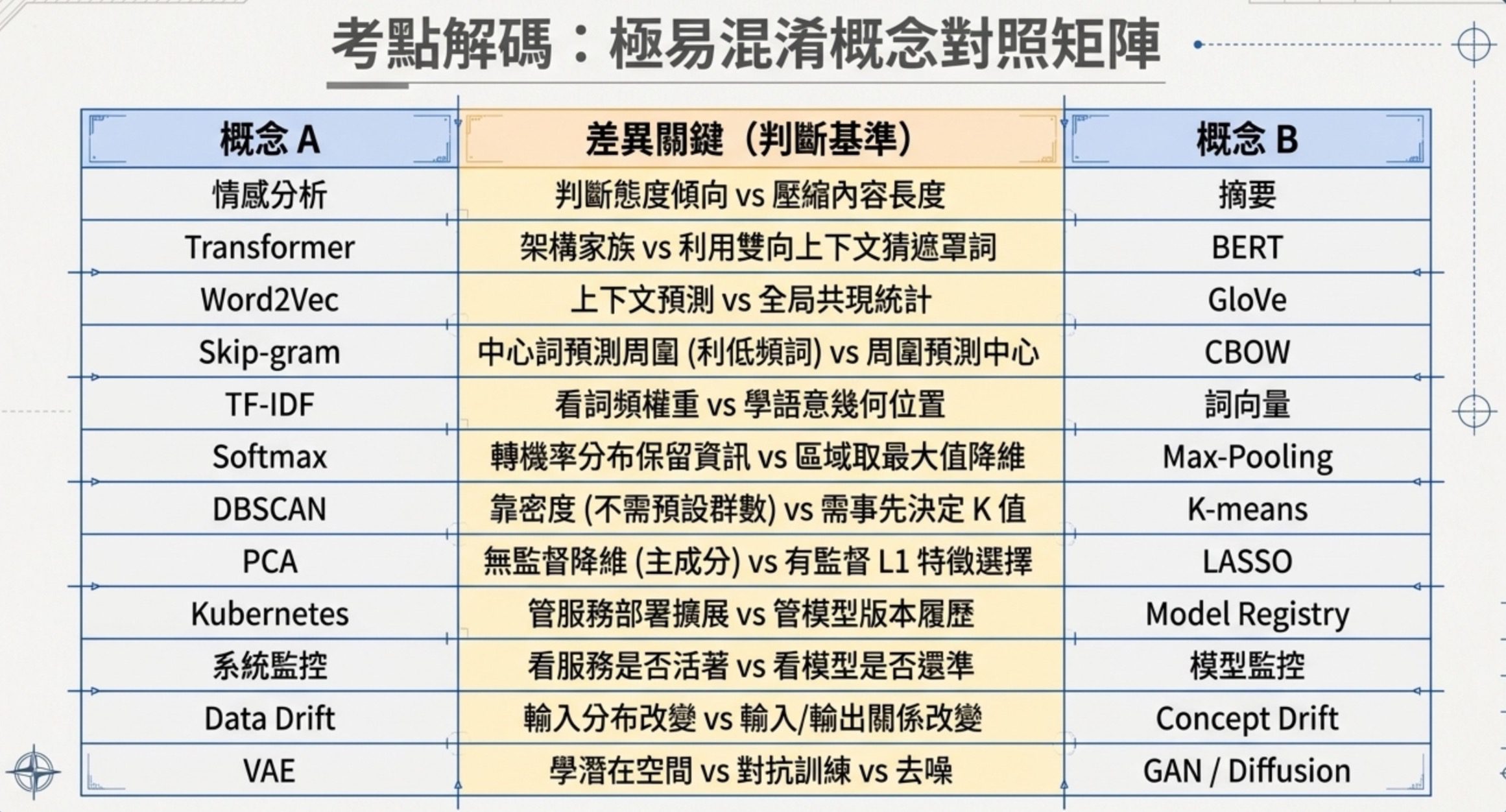
AI 應用規劃師中級科目一最容易混淆的 12 組概念對照
學完七大命題,考前最後一週把下面這 12 組高混淆概念兩兩比較一次。能用自己的話講出差異就過關;講不出來就回去翻對應的命題。
| 兩個概念 | 差異關鍵 |
|---|---|
| 情感分析 vs 摘要 | 情感分析判斷態度傾向,摘要壓縮內容長度 |
| Transformer vs BERT | Transformer 是架構家族,BERT 的 MLM 用雙向上下文猜遮罩詞 |
| Word2Vec vs GloVe | Word2Vec 用上下文預測,GloVe 用全局共現統計 |
| Skip-gram vs CBOW | Skip-gram 用中心詞預測周圍,對低頻詞較好 |
| TF-IDF vs 詞向量 | TF-IDF 看詞頻權重,詞向量學語意位置 |
| Softmax vs Max-Pooling | Softmax 把所有輸入轉成比例分布(不直接丟掉非最大項),Max-Pooling 只保留區域最大值降維 |
| DBSCAN vs K-means | DBSCAN 靠密度跟雜訊,K-means 要先決定 K |
| PCA vs LASSO | PCA 是無監督降維,LASSO 是 L1 正則化做特徵選擇 |
| Kubernetes vs Model Registry | Kubernetes 管服務部署擴展,Model Registry 管模型版本履歷 |
| 系統監控 vs 模型監控 | 系統監控看服務是否活著,模型監控看模型是否還準 |
| Data Drift vs Concept Drift | Data Drift 是輸入分布變了,Concept Drift 是輸入跟輸出的關係變了 |
| VAE vs GAN vs Diffusion | VAE 學潛在空間,GAN 做對抗,Diffusion 做去噪 |
總結:用命題思維準備中級科目一
AI 應用規劃師中級科目一(科目正式名稱:人工智慧技術應用與規劃)這份考卷,真正在測的不是 50 個獨立的名詞,而是 7 個底層命題:文字理解的三道分水嶺、影像與多模態的選型判斷、資料形狀對應方法、AI 系統四層架構、生成式 AI 找根本原因、AI 風險五層、時間序列基本功。
每個命題對應一群題目,只是包裝不同產業情境。
建議的讀法是:讀完一個命題的主線之後,翻到對應的考古題,一題一題用先分命題、再推答案的方式練。練到你不靠看選項就能想到答案,這個命題你就過了。
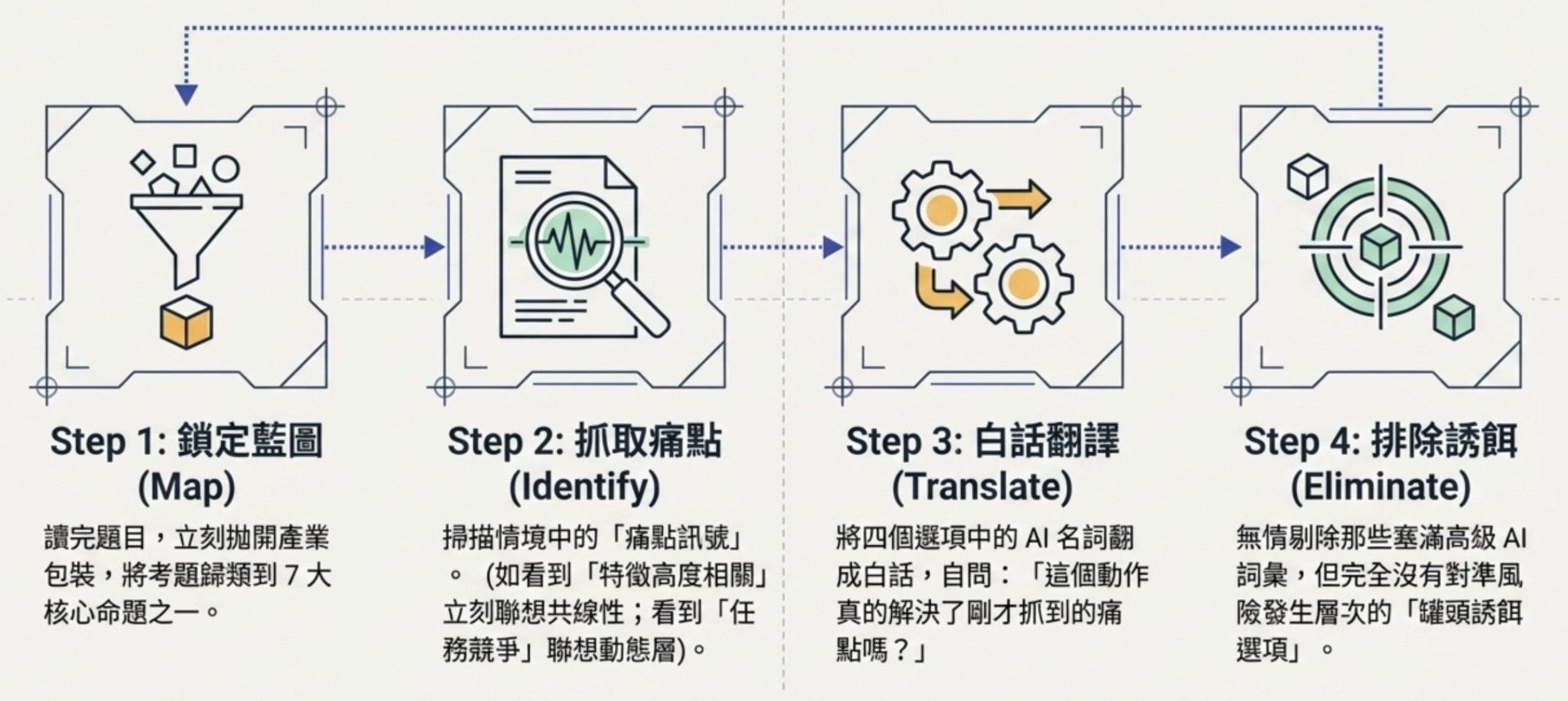
進考場的解題流程,我建議固定這四步。
第一步,讀完題目先把它分到 7 個命題之一。
第二步,辨識題目情境裡的痛點訊號(輸入分布變了、特徵高度相關、任務競爭、跨族群不一致等)。
第三步,把每個選項翻成白話,問自己這個選項真的解到題目的痛點嗎。
第四步,排除丟一堆 AI 名詞但沒對準命題的誘餌選項。
iPAS AI 應用規劃師中級的設計初衷,是檢核你能不能在企業裡擔任 AI 專案的規劃決策角色。
能讀懂題目卡在哪一個命題、能在七大命題之間做出正確判斷,就能通過科目一。
如果你看完這篇還對某個命題不踏實,歡迎到科技翰林院其他文章看更深入的單題拆解,祝大家中級考順利。
考前白話詞表
40 個科目一必考名詞(點擊展開)
考前最後一天翻這張表,確認每個名詞都能用一句白話講出來,講不出來的回去翻對應的命題。
| 名詞 | 白話翻譯 | 一句話理解 |
|---|---|---|
| NLP | 讓電腦讀懂文字 | 處理留言、客服、翻譯、摘要這類文字任務 |
| 情感分析 | 判斷文字態度 | 看一段留言是正面、負面還是中性 |
| TF-IDF | 找「這篇特別常出現、但不是大家都常講」的詞 | 用詞頻和稀有度抓關鍵字 |
| 詞向量 | 把詞變成座標 | 意思接近的詞,在座標上比較靠近 |
| Word2Vec | 靠猜前後文學詞座標 | 用文字周圍關係學語意 |
| GloVe | 靠全資料庫的共現次數學詞座標 | 看哪些詞常一起出現 |
| CBOW | 看周圍猜中間 | 用上下文預測中心詞 |
| Skip-gram | 看中間猜周圍 | 用中心詞預測附近詞,低頻詞較常考 |
| Self-Attention | 每個字自己判斷該看誰 | 讓模型知道一句話裡哪些字彼此重要 |
| MLM | 克漏字訓練 | 遮住幾個字,叫模型用上下文猜回來 |
| RAG | 先查資料再回答 | 先檢索文件,再交給語言模型生成答案 |
| Context Window | 模型一次看得到的文字容量 | 超過容量的內容,模型看不到或放不下 |
| IoU | 兩個框重疊多少 | 預測框和正確框重疊越多越好 |
| mAP | 物件偵測的總成績 | 綜合評估框得準不準、找得全不全 |
| 語義分割 | 每個像素貼類別標籤 | 所有人都標成「人」,不分人 A 人 B |
| 實例分割 | 每個物件個體分開標 | 人 A、人 B 要分開 |
| 全景分割 | 語義分割 + 實例分割 | 背景類別和個體都要處理 |
| CLIP | 把圖片和文字放到同一張語意地圖 | 讓「狗的照片」和「dog」可以互相比對 |
| Contrastive Learning | 拉近正確配對、推遠錯誤配對 | 圖文配對訓練常用 |
| Zero-shot | 沒看過也能試著判斷 | 不重新訓練,只靠文字提示分類 |
| PCA | 把重疊特徵整理成幾條新軸 | 降維、減少重複資訊 |
| LASSO | 把不重要特徵的係數壓到 0 | 做特徵選擇 |
| 多重共線性 | 特徵彼此太像,模型分不清誰重要 | 例如房間數和坪數高度相關 |
| Data Drift | 來的資料變了 | 顧客年齡層、消費型態變了 |
| Concept Drift | 規則變了 | 同樣的輸入,對結果的意義變了 |
| PSI | 資料分布穩定度指標 | 比較現在資料和訓練資料差多少 |
| KL Divergence | 兩個分布差多遠 | 用來量資料分布有沒有漂移 |
| Model Registry | 模型履歷表 | 記錄模型版本、訓練紀錄、部署狀態 |
| Kubernetes | 模型服務調度員 | 管部署、擴展、服務運行,不是模型訓練工具 |
| CI | 每次改程式就自動檢查 | 自動建置、測試、靜態分析 |
| Data Leakage | 答案偷跑進訓練流程 | 模型看到了不該看的驗證或測試資訊 |
| Non-repudiation | 事後不能抵賴 | 要能證明誰做了什麼、資料沒被改 |
| Adversarial Attack | 用很小的惡意改動騙模型 | 人看不出差異,但模型判錯 |
| Loss Balance | 多任務的分數權重 | 一個模型做多件事時,不能讓某任務權重壓過其他 |
| Mode Collapse | 生成器一直生差不多的東西 | GAN 失去多樣性 |
| WGAN | 讓 GAN 訓練比較穩的版本 | 用 Wasserstein 距離改善訓練不穩 |
| Latent Space | 模型腦中的壓縮地圖 | 資料被壓縮後所在的隱藏座標 |
| ARIMA | 用過去、趨勢、誤差預測未來 | 時間序列預測經典模型 |
| DBSCAN | 找密集群,孤單點當雜訊 | 不必先指定 K 群 |
| KD-Tree / Ball Tree | 快速找附近點的索引 | 幫 DBSCAN 減少距離計算 |
推薦閱讀
- iPAS AI 應用規劃師中級科目三:機器學習技術與應用 6 大核心命題
- iPAS AI 應用規劃師中級科目二:大數據處理分析與應用 6 大核心命題
- [新手入門] 中級科目一:費曼學習法,7 個故事讓你讀完就懂
參考資料
iPAS 經濟部產業人才能力鑑定 (2025). AI 應用規劃師中級能力鑑定考試簡章
iPAS 經濟部產業人才能力鑑定 (2025). 114 年第二次 AI 應用規劃師中級能力鑑定公告試題第一科
Google Developers (2025). Machine Learning Crash Course
Scikit-learn Documentation (2025). Model evaluation: quantifying the quality of predictions
IBM (2025). What is Natural Language Processing
IBM (2025). What is Retrieval-Augmented Generation (RAG)
FAQ
AI 應用規劃師中級科目一為什麼不適合逐題背答案?
中級題型刻意把同一個命題用不同產業情境包裝,逐題背的學生背了三個答案卻不知道那三題其實是同一個命題的變形。下次考試換成新情境就會錯。學會七大底層命題,任何變形都能自己推。
七大命題裡面該優先讀哪幾組?
優先讀資料形狀對應方法跟 AI 系統與 MLOps 流程,加起來 20 題,是分數的基底。即使對生成式 AI 不熟,這兩組讀通可以大幅提高及格機率。生成式 AI 雖然當紅,但只佔 6 題,投資報酬率沒那麼高。
中級科目一最常踩的地雷是什麼?
把系統正常誤判成模型也正常。AI 應用規劃師中級科目一非常愛考系統運作正常但模型準確率下降這種情境,只看系統監控的人會錯過所有真正的問題。記得系統監控跟模型監控是兩件事。
RAG 答錯時不要先怪大模型,是什麼意思?
RAG 是檢索 + 生成兩階段架構。生成階段給的答案如果不對,根本原因往往在檢索階段拿錯東西,而不是大模型不夠強。AI 應用規劃師中級科目一這類題目的判斷邏輯是先找系統卡在哪一層,再選工具。
生成式 AI 商用為什麼要管訓練資料來源,不是管輸出?
就這題的考試邏輯,最能「預防」侵權風險的是訓練資料篩選與授權驗證,因為它從源頭降低風險。輸出端的相似度比對、浮水印、差分隱私仍有價值,但比較像事後控管或輔助措施。實務上的法律風險還可能涉及輸出內容與既有作品的實質近似、使用情境、授權範圍等,不能只看訓練端。
考前最後一週怎麼複習最有效?
不要重看名詞解釋,改成做命題到題目的反向練習。隨機翻一題考古題,給自己 5 秒判斷它屬於七大命題的哪一組,再做答案。能在 5 秒內分對命題的人,基本上就能穩定及格。