iPAS 初級 AI 應用規劃師考前重點!分析 115 年考古題趨勢
我今年三月考完 iPAS 初級 AI 應用規劃師之後,我真心覺得光是刷題是不太可能考過。
光是 114 年第四梯次跟 115 年第一次兩屆的公告試題,加起來就有 200 題,再翻一翻官方學習指引,以及網路上各種用 Notebooklm 或 AI 做出來的學習題庫,絕對有幾千題,內容多到正常人絕對讀不完。
這場考試是 70 分及格,不是 100 分,把目標設對,策略才會對,學習才會事半功倍。
與其平均花時間在每一個範圍,不如把火力集中在高頻考點、固定題型、跟那些每屆都把考生玩到崩潰的混淆概念。
這篇文章用 114 年第四梯次跟 115 年第一次兩屆 iPAS 考古題交叉比對,幫大家整理出考試重點的出題趨勢、最容易失分的陷阱題,還有八組必須分清楚的混淆概念,搭配 aiterms.tw/ipas/L1 把混淆題型做一遍,幫助各位穩穩拿到 70 分。
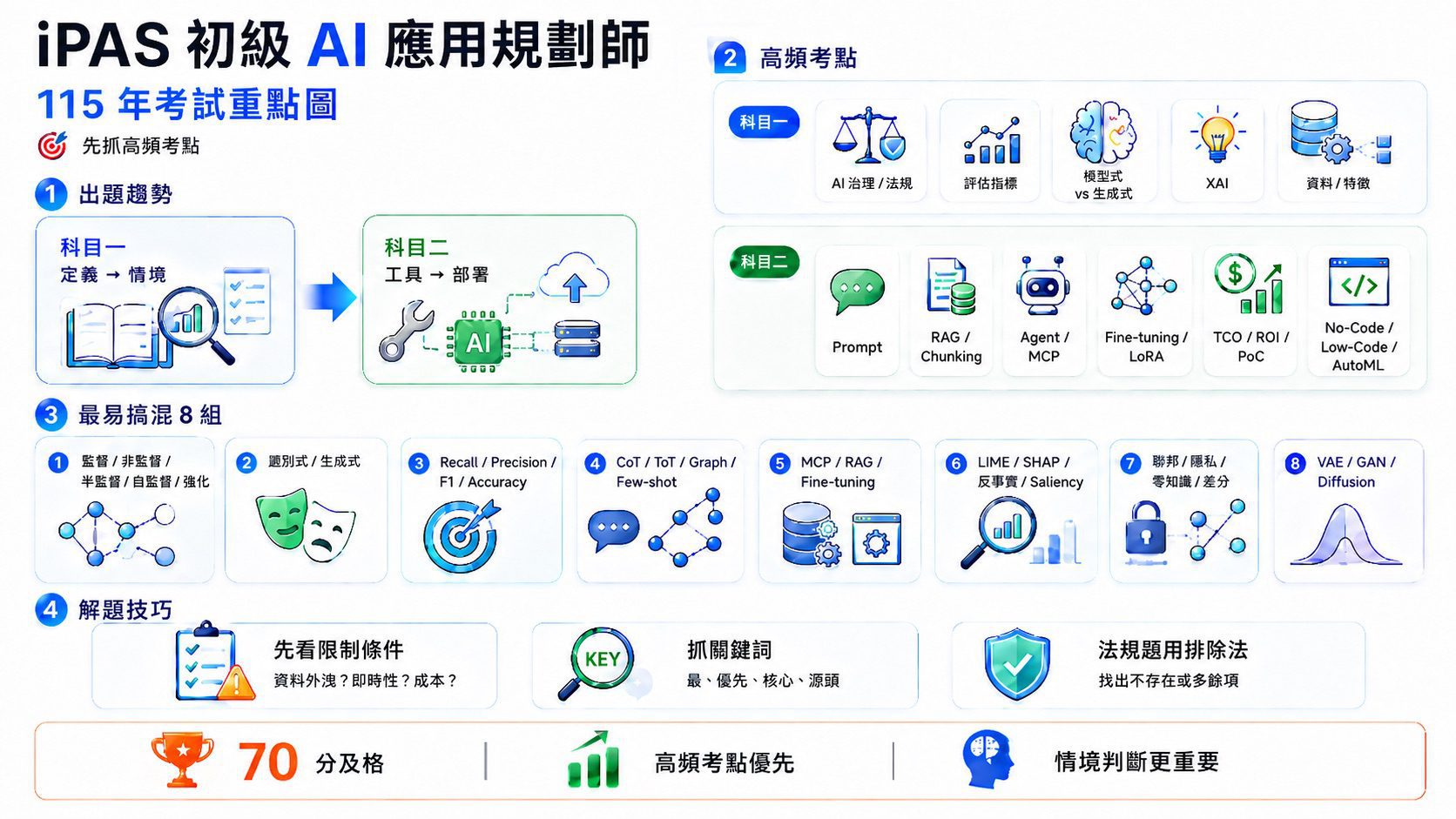
115 年初級 AI 應用規劃師的出題趨勢
科目一:從定義題轉向多條件情境判斷題
114 年第四梯次的科目一,還能看到一些單純問定義的題目,例如什麼是貝氏分類器、KNN 怎麼判斷類別、L1 跟 L2 正則化的差別,這些只要把學習指引背熟就有分。
115 年第一次明顯不同,科目一題目越來越長,幾乎每一題都套上情境,要考生先看懂某公司、某醫院、某銀行的應用場景,再選出最合適的方法。
舉個例子,115 年第一題問資料整合的目的,看起來是基礎題,但選項裡放了「依資料保存政策延長原始資料留存期限」這種乍看合理的干擾項。考生如果只記得資料整合有四個目的,卻沒想過資料留存政策根本不屬於整合範疇,就會被拐走。
這個出題趨勢對初級 AI 應用規劃師的考生來說,意味著一件事。
背定義不夠,要會在情境裡判斷哪個選項才符合題目要解決的問題。

科目二:加入大量新工具與部署實務的考試重點
114 年第四梯次的時候,生成式 AI 應用與規劃還是繞著 Prompt Engineering、Fine-tuning、RAG 在出題。
到了 115 年明顯加入了一批新工具和新概念,包括 PEFT LoRA、RFT、Vibe Coding、GPT-Realtime、AgentKit、Sora 的 C2PA、可見浮水印與內部反向搜尋機制,以及 Veo / Gemini 影片的 SynthID 數位浮水印。
還有 n8n 工作流、TCO 跟 ROI 跟 Token Economics 的成本評估、Edge Computing 邊緣運算、Context Engineering。
這些都是 2025 到 2026 年初業界真正在用的東西,學習指引可能還沒寫進去,但題目已經考了。
這就是為什麼很多人靠死背指引也只能拿到五十幾分,考試重點不只在指引裡,更在 OpenAI、Anthropic、Google 這些公司近期的官方文件跟產品發表。
考古題重複出現的高頻初級 AI 應用規劃師命題清單
兩屆都考、而且幾乎一定還會再考的題型,整理在下面這張表。考前一週時間有限的話,先把這份表的內容弄通就對了。
| 考點主題 | 114-Q4 出題 | 115-Q1 出題 | 預期出題機率 |
|---|---|---|---|
| 機器學習五種類型分辨 | Q11, Q13, Q40 | Q3, Q30, Q31, Q39, Q43 | 極高 |
| 鑑別式 AI vs 生成式 AI | Q22 | Q22, Q23 | 高 |
| XAI 解釋方法 LIME SHAP 反事實 Saliency | Q29, Q30, Q31 | Q26, Q27, Q28, Q29 | 極高 |
| 金融機構運用 AI 規範 | Q10 | Q13 | 高 |
| RAG 與 Chunking | Q38, Q47 | Q10, Q13, Q31, Q37 | 極高 |
| MCP 與 Agent 架構 | Q7, Q8, Q11, Q49 | Q12, Q15, Q16, Q21 | 高 |
| Fine-tuning 與微調技術 | Q17, Q18, Q19 | Q2, Q10, Q40 | 高 |
| 模型評估指標 F1 Recall MSE | Q19, Q39 | Q40, Q50 | 高 |
| 不平衡資料處理 | Q33, Q35 | Q5 | 中高 |
| 隱私保護技術 聯邦 同態 差分 | Q42 | Q42 | 中高 |
iPAS 初級科目一:五大核心考試重點
1.AI 治理與法規
兩屆考古題科目一都至少有 2 題在考治理跟法規,這部分根本是送分題,前提是你有念過官方文件。
要看的文件就三份:金管會的金融機構運用人工智慧技術作業規範《金融業運用人工智慧(AI)指引》,數位發展部的 AI 產品與系統評測中心評估項目,立法院 2025 年 12 月 23 日三讀通過的《人工智慧基本法》(主管機關為國科會,數位發展部負責風險分類框架)。
114 年考 AI 基本法的創新實驗環境,正確答案是參考歐盟的 Regulatory Sandbox。114-Q4 Q10 考金融機構運用 AI 治理措施,正確答案是排除「每日公布人工智慧系統運作狀況」這個不存在的規定。
115 年一樣考金融機構規範,這次問哪一項不是必要揭露資訊,答案是 AI 模型原始程式碼。
法規題的考法很固定,幾乎都是給你四個選項,找出那個不存在或不符合的規定。這類題型如果你看過原文,10 秒就能選出答案。考前一週實在沒時間細讀,至少要把每份文件的目錄掃過。

2.機器學習評估指標
科目一另一個固定題型是模型評估指標。
114 年 Q19 問迴歸任務用什麼損失函數,答案 MSE。114 年 Q39 問住院日數預測用什麼評估方式,答案要同時看 MAE 跟重症子群誤差。
115 年 Q40 問瑕疵品偵測用什麼指標,答案 F1-score,因為類別不平衡。115 年 Q50 問癌症篩檢看什麼,答案 Recall,因為要降低漏診。
這四題其實在問同一件事。什麼情境用什麼指標。
判斷邏輯也很簡單。迴歸任務看 MSE 或 MAE,分類任務看 Accuracy、Precision、Recall、F1。
不能漏掉是 Recall。
不能誤判、降低誤報是 Precision。
兩類別不平衡通常是 F1。
題幹說同時兼顧多群誤差就是要看分群指標。
把這個邏輯內化,評估就會更準。

3.鑑別式與生成式 AI 模型
兩屆考古題都有題目要你判斷某個應用情境屬於鑑別式還是生成式 AI,或是直接問該選哪一個模型架構。
自動判斷理賠案件是否為詐欺案件,這是鑑別式 AI。自動生成理賠調查報告,這是生成式 AI。
判斷邏輯講白了就是,模型輸出是一個分類標籤或數值,就是鑑別式。
模型輸出是一段新生成的內容,無論文字、影像、聲音,就是生成式。
接著模型選擇題的對應關係,預測房價用線性迴歸或隨機森林、信用違約分類用邏輯迴歸或隨機森林、影像分類用 CNN、時間序列預測用 LSTM、異常偵測用 VAE、高品質圖像生成用 Diffusion Model、多樣性圖像生成用 GAN、對話語言任務用基於 Transformer 的自迴歸模型,也就是 GPT 系列。
每一個模型背後對應的應用場景是固定的,死背就能拿分。
4.可解釋 AI XAI
XAI 是這次出題趨勢變化最大的部分之一。
114年已經考了 LIME(Q29, Q30)跟反事實解釋(Q31)三題。115年更狠,連考 LIME(Q26)、SHAP(Q27)、反事實解釋(Q28)、Saliency Map(Q29)四題。
這代表初級 AI 應用規劃師的考試重點正在朝黑箱模型的可解釋性傾斜。
出題者預設考生要能分辨四種主流 XAI 方法的差異跟使用情境,這部分我會放在後面混淆考點區塊一次拆解。
考前看到這四個英文字串都要有反應,是 iPAS 考古題穩定出現的得分題型。

5.資料處理與特徵工程進階題
資料處理題每屆至少 5 題以上,是科目一分數佔比最高的單元,考試重點分成幾類:
第一類是資料清理跟轉換,ETL 流程(114-Q4 Q3)、資料整合目的(115-Q1 Q1)、資料正規化或標準化要不要避免資料洩漏(115-Q1 Q6)、離群值處理(114-Q4 Q45 跟 115-Q1 Q4)。
第二類是特徵工程,特徵交叉(114-Q4 Q2)、One-hot 編碼(114-Q4 Q41 跟 115-Q1 Q7)、對數轉換處理偏態(115-Q1 Q44)、特徵選擇(114-Q4 Q46)。
第三類是不平衡資料,SMOTE(115-Q1 Q5)、樣本偏向多數類別(114-Q4 Q35)、預測性維護的異常樣本(114-Q4 Q33)。
第四類是視覺化跟敘述性統計,散佈圖(114-Q4 Q12)、直方圖(114-Q4 Q48 跟 115-Q1 Q17)、百分位數(115-Q1 Q16)。
這幾類題目要把判斷邏輯背熟,例如數值範圍差很大要用標準化、類別不平衡用 SMOTE、偏態分布用對數轉換、想看分布用直方圖、想看兩變數關係用散佈圖。
iPAS 初級科目二:六大核心考試重點
1.提示工程 CoT、ToT、Graph Prompting
提示工程兩屆都考至少 4 題以上,每屆都有變化。
114-Q4 Q39 考 CoT 跟 ToT 的使用情境差異,簡單流程用 CoT,多方案比較用 ToT。
Q40 考 Graph Prompting 的優勢,適合處理非線性結構與上下文關聯。
115-Q1 Q36 又考一次 Graph Prompting,這次情境是多條件彼此相關的補貨決策。
115-Q1 Q45 再考 CoT,要選最符合思維鏈的提示語句。
判斷邏輯抓住幾句話就好,CoT 是線性逐步推理,ToT 是樹狀多路徑比較,Graph Prompting 是圖狀關係處理,Few-shot 是給範例引導,Zero-shot 是不給範例直接執行。
題幹講到逐步思考或分析過程就是 CoT,講到比較多方案就是 ToT,講到多條件相互影響就是 Graph Prompting。
2.RAG 與 Chunking
RAG 跟 Chunking 兩屆加起來考了 7 題以上,幾乎是科目二最高頻的考試重點。
114-Q4 Q38 考 RAG 索引更新,答案是增量更新。
Q47 考 Chunking 目的,答案是提高檢索相關性、降低長文件干擾。
Q48 考 Multi-vector Retriever。
115-Q1 Q10 考 RAG 加 Knowledge Distillation 降低成本。
Q13 又考 Chunking。
Q31 考農場病蟲害用 RAG 結合向量資料庫。
Q37 考品牌客服用 Prompt 加 RAG。
RAG 題的常見干擾選項是重新訓練模型、降低生成溫度、使用 Fine-tuning 這些跟 RAG 沒關係的解法。
看到題目說文件會更新、資料每天新增、要即時查詢最新內容,幾乎都是選 RAG 相關方案。
Chunking 題就更單純,記住兩個目的,精準對應檢索段落、降低長上下文噪音。
3.AI Agent、MCP、Solution Graph
Agent 相關題型是 2025 年下半年到 2026 年初的新出題趨勢。
兩屆都考 MCP(Model Context Protocol)跟 Solution Graph。
114-Q4 Q7 考 MCP 運作順序,AI Host 到 MCP Client 到 MCP Server 到資料查詢到結果回傳。Q44 考 MCP 跟 RAG 的差異。Q49 考 Solution Graph 的功能。
115-Q1 Q12 一樣考 MCP vs RAG。Q15 考 Context-aware Agent。Q16 又考 Solution Graph。Q21 新增考 OpenAI AgentKit。
判斷邏輯整理一下:
MCP 是讓 AI 連接外部工具或資料來源的標準化協議。
RAG 是補充模型知識來源的檢索方法。
A2A 是不同代理之間的通訊架構。
Solution Graph 是代理執行任務時的決策路徑參考。
Context-aware Agent 是會利用對話歷史跟任務狀態調整行為的代理。
容易混淆的是 MCP vs RAG,記住一句話,MCP 連工具、RAG 找知識。

4.Fine-tuning、PEFT、LoRA、RFT
Fine-tuning 在 114-Q4 已經出現,115-Q1 則進一步強化 PEFT、LoRA、RFT 與 Knowledge Distillation 等更細的微調與模型效率化概念。
115-Q1 Q2 直接問 PEFT 哪一種技術最能降低需更新的參數數量,答案是 LoRA(Low-Rank Adaptation)。
Q40 問 RFT(Reinforcement Fine-tuning)的目的,答案是透過 reward 訊號調整模型回應策略與行為偏好。
這部分學員最常搞混的是六個技術,Fine-tuning 用標註資料更新模型權重、PEFT 是參數高效微調的總稱、LoRA 是 PEFT 的一種具體方法只更新低秩矩陣、RFT 用獎勵訊號調整模型行為偏好、RLHF 用人類偏好資料訓練獎勵模型再調整 LLM、Knowledge Distillation 讓小模型學習大模型的行為以降低推論成本。
Knowledge Distillation 不是微調,是壓縮。
考試時最常出現的混淆就是 Knowledge Distillation vs Fine-tuning,看到題幹說降低運算成本、讓小模型替代大模型就是蒸餾。
5.導入評估 TCO、ROI、PoC、Token Economics 的成本效益題
115-Q1 大量加入了商業導入評估題型。
Q24 考 TCO(Total Cost of Ownership)總體擁有成本,要把 API 調用、維護人力、基礎設施、訓練、整合、資安合規全部納入。
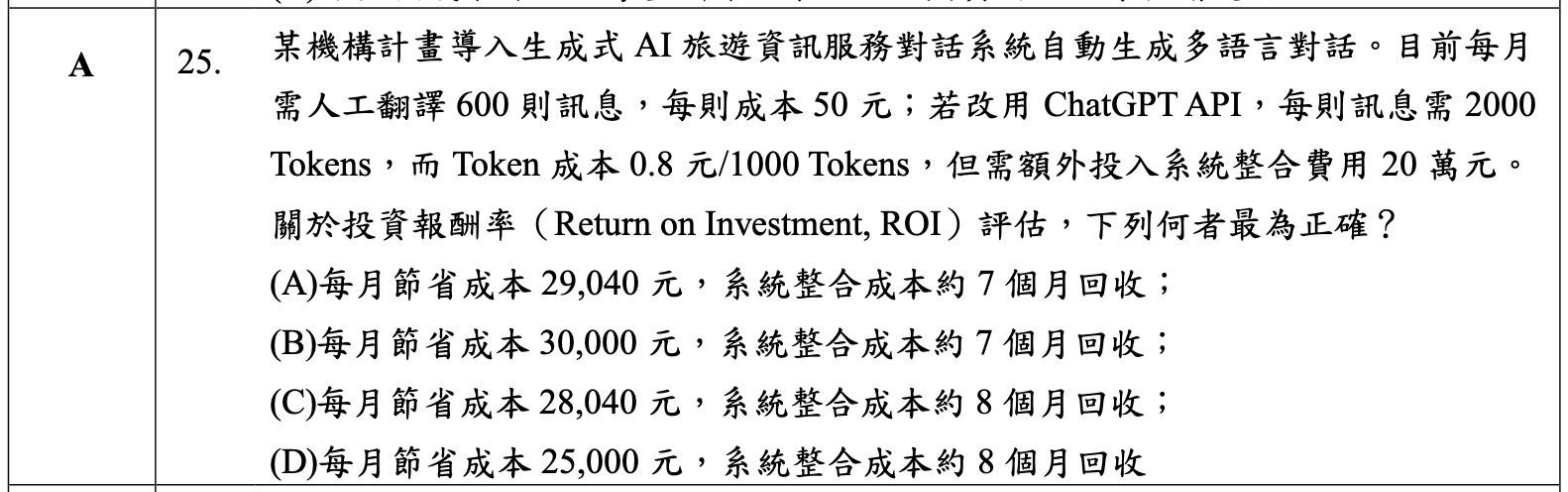
Q25 考 ROI 計算,給數字算節省成本跟回收期。(少數需要計算的題目!)
Q28 考 Token Economics 的範圍,要排除模型訓練 GPU 記憶體成本這個非 Token Economics 範疇的選項。
Q38 考 PoC 概念驗證階段的工作範圍,要排除制定長期治理框架這個屬於正式部署階段的選項。
這類題目對非商管背景的人不太友善,但有個訣竅。
TCO 算總體成本要包山包海。
PoC 是試水溫,不要做正式部署的工作。
只要記住 PoC 階段不做治理框架、不做長期維運規劃,就比較能分辨。
ROI 算投資報酬率,公式是淨收益除以投資成本。
回收期 = 一次性投資成本 ÷ 每月淨節省成本。以下面 Q25 為例,200,000 ÷ 29,040 ≈ 6.89 個月,因此約 7 個月回收。
6.No-Code、Low-Code、AutoML
平台類工具是兩屆都會出 3 到 5 題的固定題型,關鍵在於分辨三種工具的功能定位。
| 工具類型 | 主要使用者 | 核心功能 | 典型出題情境 |
|---|---|---|---|
| No-Code | 業務人員、無程式背景 | 視覺化拖拉建立應用,純拖拉 | 各部門自行建表單、儀表板 |
| Low-Code | 有少量程式概念人員 | 視覺化加少量程式碼 | IT 人力不足、需彈性調整 |
| AutoML | 有資料分析需求人員 | 自動化模型訓練 | 沒有 AI 工程師但要建模型 |
115-Q1 Q11 直接考 No-Code vs AutoML 的功能定位,正解是 No-Code 做分析儀表板、AutoML 做模型建立。
Q29 考 IT 人力有限要做病蟲害通報流程,選 Low-Code。
Q34 考 No-Code 開放後產生治理混亂,問根本問題,答案是缺乏統一管理機制。
判斷原則,純拖拉是 No-Code,要寫一點程式是 Low-Code,要訓練模型是 AutoML。
初級考試最常混淆的 8 個概念
這一段是這篇文章的核心,考試大部分失分不是因為你不會,是因為兩個概念太像,題幹一變化就分不清楚。
下面是兩屆 iPAS 考古題裡學員最容易搞混的概念,每組我都用一個判斷句幫你更好理解。
1.監督式、非監督式、半監督式、自監督式、強化式學習
這五種學習方式兩屆加起來考了至少 8 題以上,是科目一 CP 值最高的考試重點。
監督式學習有完整標註資料,學習輸入跟目標的對應,例如已知洗錢案例訓練詐欺偵測模型(115-Q1 Q30)。
非監督式學習沒有標註資料,找資料內在結構,例如顧客分群、股價趨勢型態識別(115-Q1 Q39)。
半監督式學習是少量標註加大量未標註資料,例如 30% 病害影像有標註、70% 沒標註(115-Q1 Q31)。
自監督式學習利用資料本身產生訓練目標,不需人工標註(115-Q1 Q43)。
強化式學習透過環境互動跟獎勵訊號調整策略,例如智慧投資系統根據盈虧調整買賣決策(114-Q4 Q17)。
最常搞混的是半監督式跟自監督式。
判斷句:半監督式是有標註也有未標註兩種都用,自監督式是沒有人工標註但資料本身能產生目標。
2.鑑別式 AI 與生成式 AI
這組看起來簡單,但題幹一加情境就會有人選錯。
判斷句:輸出是判斷結果就是鑑別式,輸出是新內容就是生成式。
詐欺偵測、信用評分、影像分類、垃圾郵件辨識都是鑑別式。
寫報告、生成圖像、生成影片、續寫文章都是生成式。
例如題目問醫院誤把生成式 AI 用於 X 光肺炎判讀的風險,正確答案是模型可能生成與實際影像不符的診斷結論,考生如果不知道生成式 AI 的本質是生成新內容而非判斷,就會選錯。
3.召回率、精準率、F1-score、Accuracy
這四個指標每屆至少考 2 題。
Accuracy 是準確率,適合類別平衡時的整體表現。
Precision 是精準率,預測為正類中真的是正類的比例,要降低誤報用這個。
Recall 是召回率,實際正類中被預測出來的比例,要降低漏報用這個。
F1-score 是 Precision 跟 Recall 的調和平均,類別不平衡時用。
判斷句:怕漏抓看 Recall,怕誤抓看 Precision,類別不平衡用 F1,平衡資料用 Accuracy。
Q50 考癌症篩檢,題幹強調希望盡量找出所有可能的癌症患者,明顯是降低漏報,選 Recall。
Q40 考瑕疵品偵測,題幹說瑕疵品比例極低,選 F1-score。
4.CoT、ToT、Graph Prompting、Few-shot
四種提示工程方法的判斷句已經在前面講過,這邊再強調一次差異。
CoT(Chain of Thought)是線性逐步推理,題幹有逐步或分析過程。
ToT(Tree of Thoughts)是樹狀多路徑探索,題幹有比較多方案、跨部門複雜任務。
Graph Prompting 是圖狀關係處理,題幹有多條件相關、網絡化資訊。
Few-shot 是給範例引導,題幹有提供範例、依範例風格。
Zero-shot 是不給範例直接執行,題幹有直接判斷、無示範。
四選一的時候,先看題幹的關鍵字,再對應上面五個判斷句。
5.MCP、RAG、Fine-tuning 三種知識擴展技術
這組兩屆都考,是科目二必考的考試重點。
MCP(Model Context Protocol)是標準化協議,讓 AI 連接外部工具或系統。
RAG(Retrieval-Augmented Generation)是檢索增強,補充模型的知識來源。
Fine-tuning 透過資料更新模型權重,改變模型行為。
114-Q4 Q44 跟 115-Q1 Q12 都直接考 MCP vs RAG 差異。
判斷句:MCP 連工具、RAG 找知識、Fine-tuning 改行為。
進一步的混淆題會把這三個跟 Knowledge Distillation 放在一起。蒸餾的目的是降低推論成本,不是擴展知識,這點不要搞錯。
6.LIME、SHAP、反事實解釋、Saliency Map 四種 XAI
XAI 方法是 115 第一次考最多的一組。
LIME 解釋單一樣本的局部預測,屬於後處理方法。
SHAP 分配各特徵對單一預測的貢獻值。
反事實解釋(Counterfactual)分析資料怎麼變才能讓決策改變,常用於金融授信。
Saliency Map 在輸入資料中標示對單一預測影響較大的區域,常用於影像。
判斷句:LIME 跟 SHAP 都是局部解釋,差別在 SHAP 給出明確的貢獻分配。反事實解釋是反推改變什麼會改變結果。Saliency Map 是視覺化重要區域。
115-Q1 Q28 考反事實解釋的金融應用情境,要選分析客戶申請資料變動對授信決策結果的影響。
7.聯邦學習、同態加密、零知識證明、差分隱私
這四種隱私保護技術各有定位。
聯邦學習是原始資料不出本地,各端訓練後上傳模型參數。
同態加密是資料維持加密狀態下仍能進行計算。
零知識證明是證明某事為真但不揭露資料本身。
差分隱私是在資料中加入噪音降低個資識別風險。
判斷句:跨機構訓練不能集中資料用聯邦學習。加密狀態下要做計算用同態加密。證明身分但不揭露細節用零知識證明。統計資料要降低個人識別風險用差分隱私。
114-Q4 Q42 考跨國醫院資料不能集中,選聯邦學習。
115-Q1 Q42 考資料可集中於安全環境,但要在加密狀態下完成計算,選同態加密。
差一個關鍵字答案就不同,要仔細看題幹。
8.VAE、GAN、Diffusion Model 三種生成模型
三種主流生成模型的差異。
VAE(變分自編碼器)將資料壓縮到潛在空間再重建,常用於異常偵測。
GAN(生成對抗網路)用生成器跟判別器對抗訓練,多樣性高但不穩定。
Diffusion Model(擴散模型)從噪音逐步去噪生成資料,品質穩定、細節好。
判斷句:要做異常偵測,用正常資料學習分佈,選 VAE。要高多樣性生成選 GAN。要高品質穩定生成選 Diffusion Model。
115-Q1 Q21 考時尚品牌服裝設計,題幹強調高視覺品質、細節穩定、風格變化自然,選 Diffusion Model。Q22 考工廠設備異常偵測,選 VAE。
iPAS 初級考古題的陷阱題拆解
兩個選項看起來都對時如何判斷?
iPAS 考古題最常見的陷阱,是兩個選項看起來都對。
這時候判斷邏輯不是對不對,是優先順序。
題幹通常會有關鍵字提示哪個是優先目標,例如首要、優先、最應該、最關鍵、核心。
舉個例子,115年問導入生成式 AI 客服系統,要從資料層面降低敏感資訊暴露風險,下列何者最為合理?
選項裡 A 強化模型輸出審查、B 設定回覆範圍、C 加密儲存、D 提供必要資料加去識別化,四個都對。

但題幹寫從資料層面、降低敏感資訊暴露,所以要選最源頭的解法,也就是 D 資料最小化跟去識別化。
輸出審查、回覆範圍、加密儲存都是後段防護,源頭沒處理好都還是有風險。
判讀句:看到優先、最、源頭、根本這類詞,選格局最大、最源頭的選項。
情境題要先找限制條件再選答案
很多人寫情境題會直接看答案,這是錯的。
正確順序是先看題幹的限制條件,再回頭看選項。
常見的限制條件包括模型架構與推論設定皆未調整、資料不得外洩、不大幅增加標註預算、兼顧即時性與可靠性、避免重新訓練成本、資料可集中於安全環境。這些限制條件會直接砍掉一半選項。
115 年 Q42 是經典案例,題幹強調資料可集中於安全環境中處理加上資料處於加密狀態仍能完成模型計算,這兩個條件一加,聯邦學習(不能集中)跟匿名化(不是加密)就被砍了,答案直接是同態加密。
寫題前先把限制條件圈起來,是初級 AI 應用規劃師考試最有效的判讀技巧。
法規與治理題用排除法處理多餘揭露項
法規題的固定考法是下列何者不是、下列何者並非。
這類題目用排除法最快,先想一遍規範裡會寫的項目,把選項裡符合的劃掉,剩下那個就是答案。
115 年 Q13 問金融機構使用 AI 時哪個非必要揭露資訊。B 服務適用對象、C 是否為 AI 自動完成、D 是否提供替代方案,這三項都是規範裡明文要求的揭露事項。A 「AI 模型原始程式碼」根本不在規範裡,而且揭露原始碼會造成資安問題,答案就是 A。
114 年 Q10 是另一個例子,問金融機構治理措施哪一項並非明訂須落實的,選項裡 C 每日公布人工智慧系統運作狀況聽起來很合理,但規範裡根本沒有每日公布這種頻率要求,這就是多餘項。
判讀技巧:看到每日公布、即時提供、完全公開、原始程式碼這類過度具體或過度透明的字眼,幾乎都是多餘項,直接選它。
初級 AI 應用規劃師的考前重點是抓住高頻考試命題邏輯
初級 AI 應用規劃師考試的本質,不是測試你是不是 AI 專家,是測試你能不能在企業真正導入 AI 時做對判斷。
考試是 70 分及格,不需要全部都會,只要掌握高頻考點跟核心判斷邏輯,就能穩穩過關。
考試重點會隨工具更新一直變,2026 年下半年的考題大概又會加入新一波 Agent 工具跟微調技術,但底層的判斷邏輯不會變。
把這套邏輯練起來,後面任何一級的 iPAS 認證都會輕鬆很多。
搭配 aiterms.tw/ipas/L1 把這篇提到的混淆題型做一輪實戰練習。
考前不要再讀新內容,把已經看過的判斷句反覆熟讀,考試當天判讀速度自然就上來了,祝大家順利通過初級考試!
推薦閱讀
- iPAS AI 應用規劃師是什麼?台灣唯一官方 AI 證照完整攻略
- iPAS AI 應用規劃師中級跟初級差別?從 150 題考古題看穿出題思維
- iPAS AI 應用規劃師中級科目一:人工智慧技術應用與規劃 7 大核心命題
- iPAS AI 應用規劃師中級科目二:大數據處理分析與應用 6 大核心命題
- iPAS AI 應用規劃師中級科目三:機器學習技術與應用 6 大核心命題
參考資料
iPAS 經濟部產業人才能力鑑定。115 年度 AI 應用規劃師能力鑑定簡章
iPAS 經濟部產業人才能力鑑定。114 年第四梯次初級 AI 應用規劃師公告試題
perng/ai-cert。115 年第一次初級 AI 應用規劃師公告試題備份
金融監督管理委員會主管法規共用系統。金融業運用人工智慧 AI 指引
AITerms.tw。iPAS 初級 AI 應用規劃師題庫與考前練習
FAQ
iPAS 初級 AI 應用規劃師考試幾分及格?
同時報考同一級等所有科目:平均達 70 分,且每科不得低於 60 分。考前策略不要追求全部背完,而是先抓高頻考試重點,把機器學習類型、XAI、RAG、MCP、法規治理、生成式 AI 工具差異這幾組容易混淆的題型練熟。
iPAS 考古題要怎麼用才有效?
iPAS 考古題不要只看答案,要把每題錯誤選項也整理成判斷句。115 年出題趨勢更偏向情境判讀,題目會把企業、醫療、金融或教育場景包進去,考你能不能選出最合適的 AI 方法。
115 年 iPAS 初級 AI 應用規劃師出題趨勢是什麼?
115 年 iPAS 初級 AI 應用規劃師出題趨勢是題幹變長、工具變新、情境判斷變多。除了基礎機器學習與統計概念,PEFT、LoRA、RFT、AgentKit、MCP、RAG、TCO、ROI 這些新概念也開始進入題目。
沒有程式背景能考 iPAS 初級 AI 應用規劃師嗎?
可以,初級考試不考寫程式,重點是理解 AI 概念與應用情境。沒有程式背景的人要先掌握 AI 專有名詞的白話意思,再用考古題練判斷,尤其是 No-Code、Low-Code、AutoML、RAG、MCP 這些容易被題目混在一起的概念。
考前一週準備 iPAS 初級 AI 應用規劃師還來得及嗎?
考前一週還來得及,但不要從頭讀完整指引。比較有效的做法是先做兩屆 iPAS 考古題,錯題回頭查本文整理的考試重點,再用 AITerms.tw 的 iPAS 初級題庫補弱項,把時間集中在高頻考點。
企業主為什麼要看 iPAS 初級 AI 應用規劃師考試重點?
企業主不一定要考證照,但值得看 iPAS 初級 AI 應用規劃師考試重點,因為這份範圍反映台灣官方對 AI 導入能力的基本期待。你可以用它檢查團隊是否懂資料治理、模型評估、AI 法規、導入成本與生成式 AI 工具選型。