iPAS AI 應用規劃師中級科目三:機器學習技術與應用 6 大核心命題
科目三:機器學習技術與應用
這是考點命題拆解版,幫你抓中級科目三(機器學習技術與應用)的出題重點。如果你想先用白話故事讀懂,請看 [新手入門] 中級科目三:費曼學習法,6 個故事讓你讀完就懂。
是中級三科裡技術細節最密、深度學習比重最高的一科,50 題裡面光是 CNN、RNN、LSTM、Transformer、VGG16 的結構題就佔了 7 題,加上正則化、優化器、評估指標、程式碼判讀,看起來名詞滿天飛。
但出題者藏在背後的判斷邏輯,其實只有 6 個底層命題。
官方題目來源:https://ipd.nat.gov.tw/ipas/certification/AIAP/learning-resources
AI 應用規劃師中級科目三的考試邏輯跟六大命題地圖
科目三的題目密度最高的兩個區塊,一個是深度學習(CNN、LSTM、Transformer 加上 VGG16 的詳細結構),另一個是訓練的工程細節(正則化、優化器、學習率、早停)。這兩塊加起來佔了將近一半題目,剩下的是評估指標、偏誤治理、隱私技術、程式碼判讀。
跟科目二類似,科目三也有大量程式碼判讀題(numpy、sklearn、keras、torchvision),但科目三的程式碼題更技術導向,要會看 Dropout 的數學定義、VGG16 的層結構摘要、transfer learning 的凍結語法。
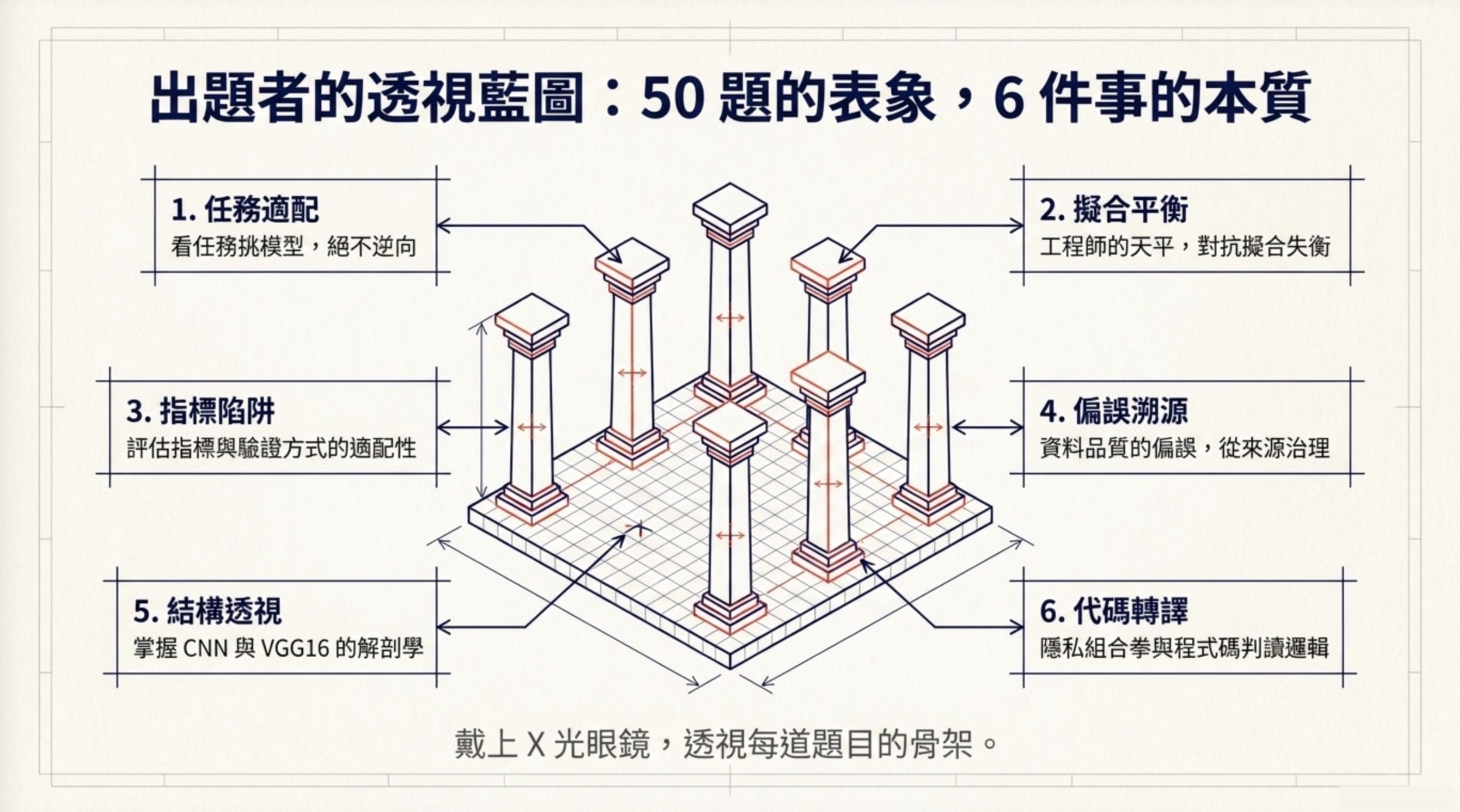
AI 應用規劃師中級科目三的六大核心命題地圖
我把 114 年第二次公告試題的 50 題逐一拆過之後,歸納出下面這張命題地圖。後面六個 H2 會依序講每一個命題。
| 命題 | 出題者想測的判斷力 | 對應題號 |
|---|---|---|
| 看任務挑模型不要逆向 | CNN、LSTM、Transformer、邏輯迴歸、貝氏、Monte Carlo 各自的適用情境 | 5, 6, 7, 8, 10, 18, 22, 23, 25 |
| 訓練要平衡擬合不足跟過擬合 | L1、L2、Dropout、Adam、早停、學習率的使用時機 | 2, 3, 11, 12, 17, 26, 27, 31, 32 |
| 指標跟驗證方式對應任務類型 | F1、R²、Accuracy 陷阱、時間序列 CV、分層 CV 的選擇 | 1, 14, 15, 16, 19, 24, 29, 30, 34 |
| 資料品質的偏誤要從來源治理 | 標籤偏差、取樣偏差、特徵縮放、PCA 變異量、DBSCAN 雜訊 | 4, 9, 13, 20, 28, 35 |
| CNN 結構與遷移學習的直覺 | 卷積層、池化層、全連接層的參數量跟運算量、VGG16 凍結語法 | 21, 42, 43, 44, 45 |
| 隱私技術與程式碼判讀 | 同態加密組合、numpy 矩陣運算、Dropout 偽碼、Monte Carlo 條件機率 | 33, 36, 37, 38, 39, 40, 41, 46, 47, 48, 49, 50 |
這份地圖最值得看的是程式碼判讀這組高達 12 題,跟科目二一樣佔了將近四分之一。如果你不熟 numpy、sklearn、keras 的基本語法,光看其他五組概念懂得再好也救不回來。考前最後一週至少留一天集中練程式碼題。
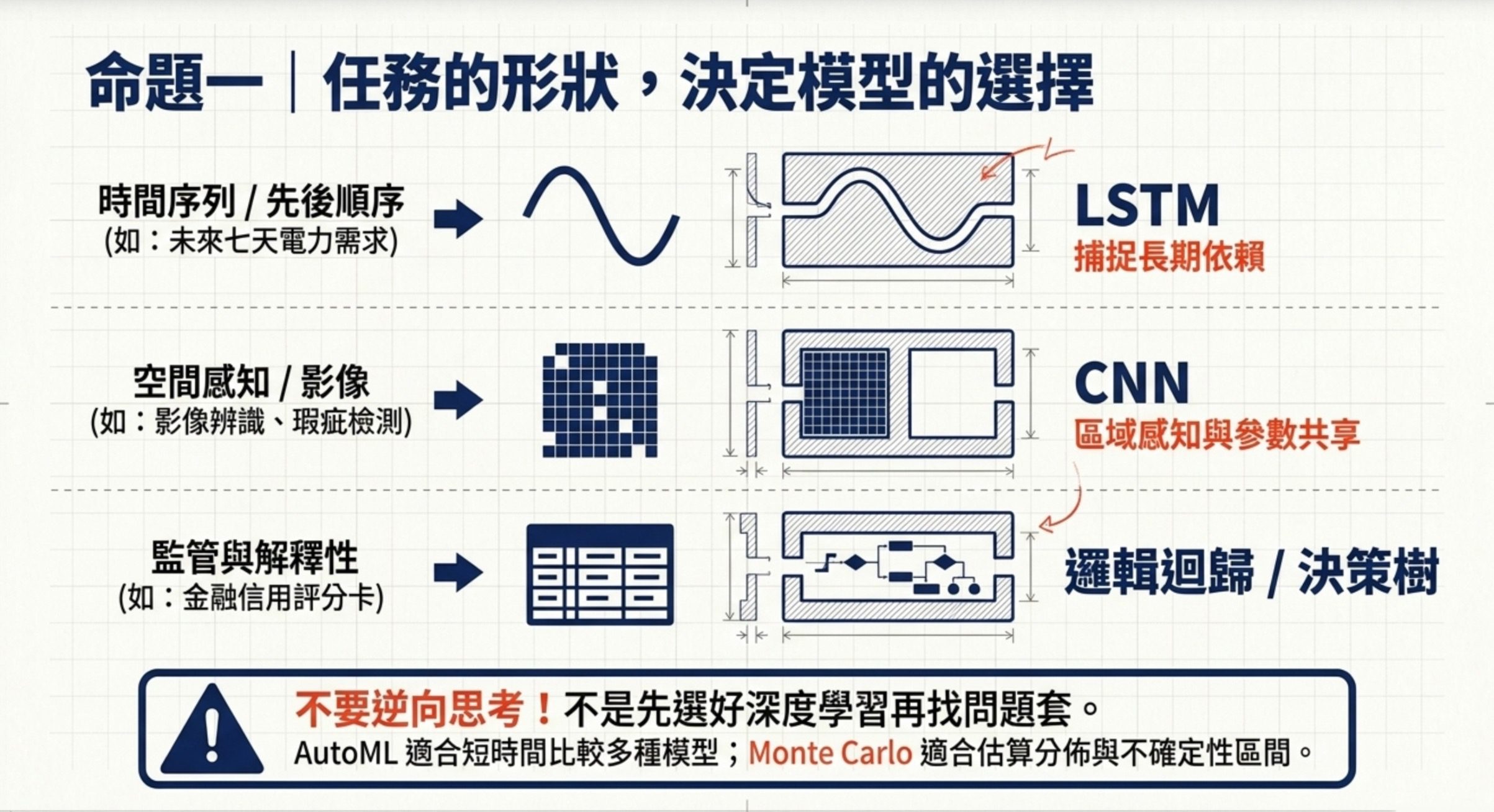
1.任務來決定模型的選擇
這 9 題的底層命題只有一句:任務的形狀決定模型的選擇,不是看哪個模型潮就用哪個。
機器學習技術與應用這個科目把模型選擇放在最核心的位置。AI 應用規劃師最該避免的反模式,是先選好深度學習再硬找問題套上去。
要學會這個命題,先建立四個核心模型家族的選型直覺。
第一個家族是 CNN(卷積神經網路):它的兩個核心機制是區域感知(Local Receptive Field)跟參數共享(Parameter Sharing)。區域感知讓每個神經元只關注影像的局部區域,參數共享讓同一個卷積核在整張圖片上滑動,大幅降低參數量。CNN 適合影像分類、物件偵測、瑕疵檢測這類影像任務。CNN 不是自動有旋轉與比例不變性,那是訓練資料增強才能達到的。CNN 也沒有捨棄激活函數,而是用 ReLU 等非線性激活引入表達能力。
第二個家族是 RNN/LSTM:它的核心能力是處理時間序列跟有先後順序的資料。LSTM 用閘門(gate)機制解決普通 RNN 的長期依賴問題,適合預測未來電力需求、語音辨識、文字生成這類序列任務。看到未來七天、時間趨勢、序列預測這類關鍵字,優先想 LSTM。看到影像辨識、分群這類非序列任務,不要硬塞 LSTM。
第三個家族是 Transformer:它的核心是多頭注意力(Multi-head Attention)機制。為什麼要多頭?因為不同的頭可以從不同的表示子空間同時捕捉不同層次的關聯。例如語音辨識同時要懂發音特徵、語速變化、語意脈絡,單一注意力頭只能看一種關聯,多頭能並行處理多種。多頭的目的不是減少參數或避免梯度消失,那些是 Transformer 其他設計帶來的副效果。
第四個家族是傳統 ML 跟機率模型:決策樹用資訊增益遞迴分裂,適合可解釋性需求高的場景(例如醫療診斷)。邏輯迴歸是金融信用評分卡的標配,因為監管要可解釋。貝氏定理用條件機率算給定行為特徵下,顧客屬於會購買的機率,適合行為分類。Monte Carlo 方法用隨機抽樣模擬,適合不確定變數多、需要估算分佈或風險區間的場景(例如太陽能發電量預測)。AutoML 適合短時間內比較多種模型、缺乏專職工程師的場景,不適合已有資深團隊的成熟流程。
示範解題:以電力需求預測為例
挑題 7 示範,因為它最能展現時序任務優先 LSTM這個判斷力。

題目情境:問下列哪一種應用最適合採用 LSTM 模型。四個選項分別是預測未來七天的電力需求變化趨勢、辨識監視影像中不同類別的物件、將大量顧客資料依相似特徵自動分群、將高維度的感測器資料壓縮成低維表示。
推理過程:
第一步,辨識每個選項是什麼任務。預測未來七天是時間序列預測、影像辨識是 CNN 任務、自動分群是無監督學習(K-means、DBSCAN)、壓縮高維是降維(PCA、自編碼器)。
第二步,把 LSTM 的核心能力跟選項對應。LSTM 處理有時間先後的序列、捕捉長期依賴,只有未來七天電力需求變化趨勢符合這兩個條件。
第三步,確認其他選項都不是序列任務。答案是 A。
這個命題的變形題:題 5 跟題 6 用 CNN 卷積層跟區域感知參數共享包裝、題 8 用資訊增益包裝決策樹、題 10 用行銷部門短時間比較模型包裝 AutoML 適用情境、題 18 用 XGBoost 跟 GBDT 比較包裝集成學習改進、題 22 用顧客瀏覽購買包裝貝氏定理、題 23 用太陽能發電預測包裝 Monte Carlo、題 25 用信用評分卡包裝傳統建模流程。
把四個家族建立好,這 9 題你能自己過。
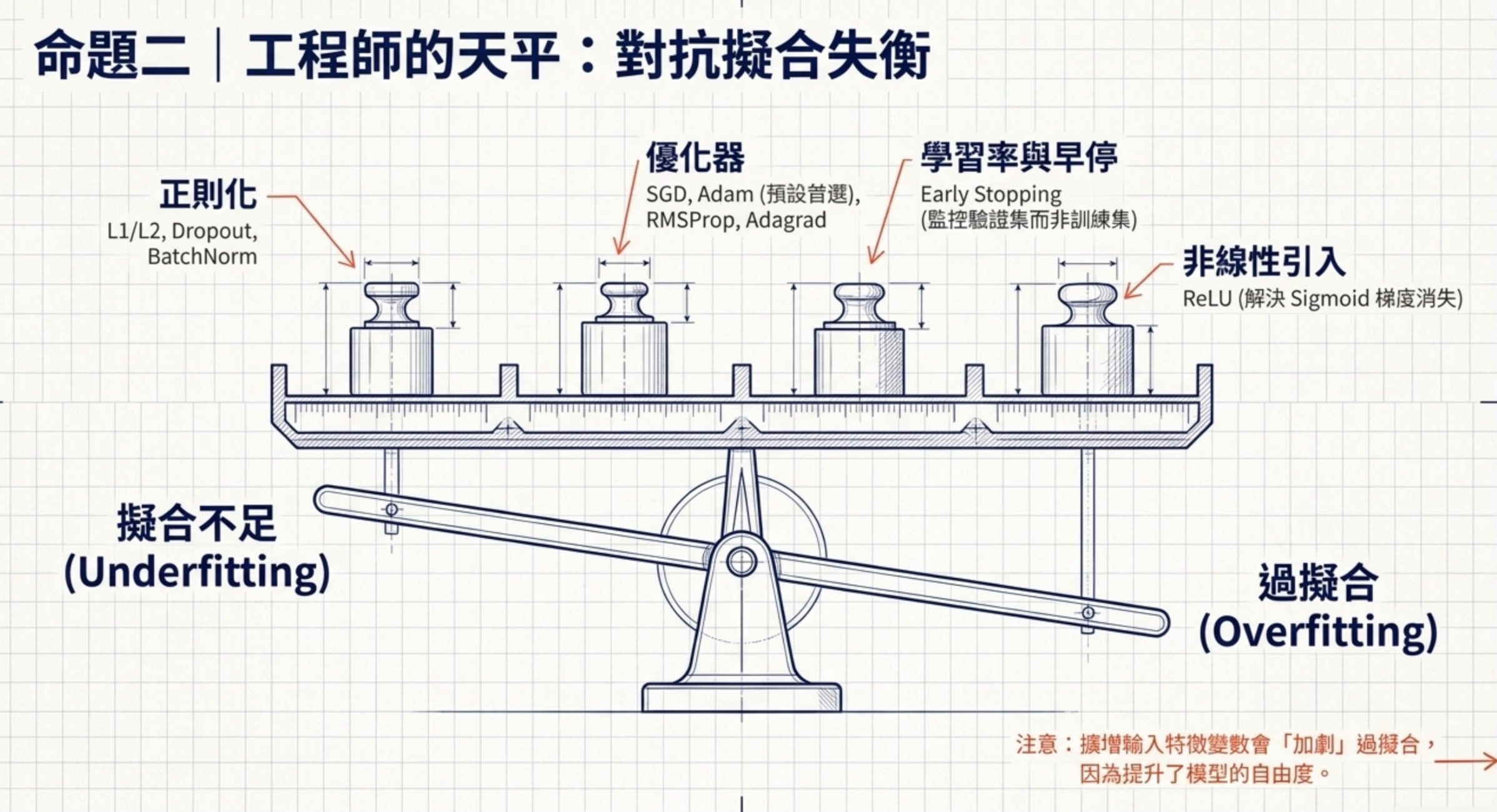
2.訓練要平衡擬合不足跟過擬合
這 9 題的底層命題是:模型訓練的兩個敵人是擬合不足跟過擬合,而每一種正則化或優化工具都對應一種解法。
在機器學習技術與應用裡,這組題目佔分將近五分之一,AI 應用規劃師要能在 3 秒內判斷現在的痛點是哪一邊。
訓練的工程工具可以拆成四類。
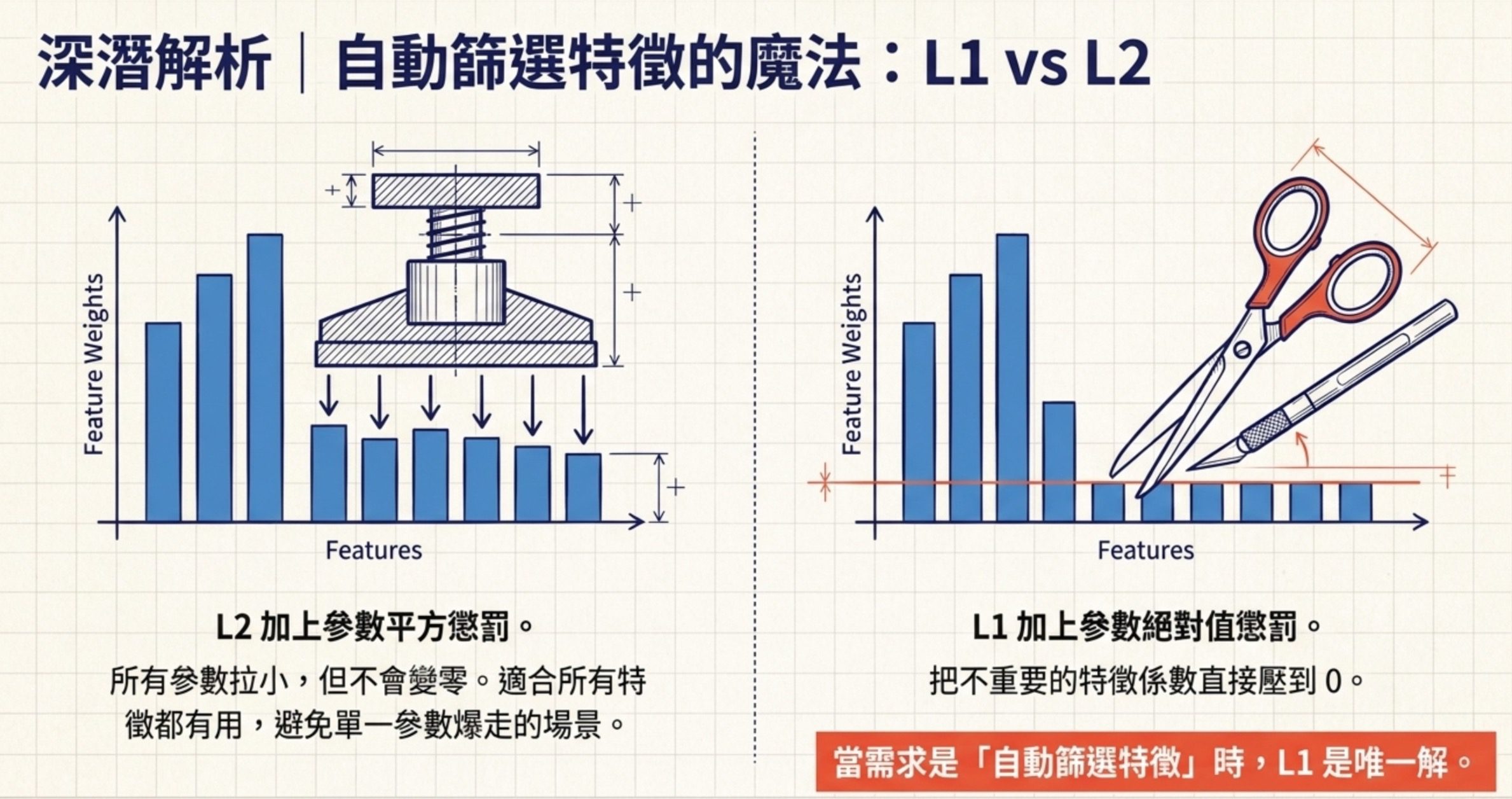
第一類是正則化:L1 正則化(Lasso)在損失函數加上參數絕對值的懲罰,效果是把不重要的特徵係數壓到 0,自動完成特徵選擇,適合特徵很多但懷疑大半沒用的場景。L2 正則化(Ridge)加上參數平方的懲罰,效果是把所有參數都拉小但不會變 0,適合所有特徵都有用但要避免某個參數爆走。Dropout 是訓練時隨機關掉一部分神經元,強迫網路不依賴特定路徑,程式碼長相是 mask = np.random.binomial(1, p, size=x.shape); return x * mask / p(注意要除以 p 做縮放,保持期望值)。Batch Normalization 也有正則化效果但主要功能是穩定訓練。
第二類是優化器:SGD 是基本的隨機梯度下降。SGD with Momentum 加入動量項,讓梯度方向有慣性,避免來回震盪。Adam 同時內建動量(一階矩)跟自適應學習率(二階矩),是大部分情況的預設首選。RMSProp 的核心考點是根據平方梯度調整有效學習率;但在 PyTorch 等框架中 RMSProp 也有 momentum 參數(預設為 0),所以不能說「RMSProp 永遠沒有動量」。Adagrad 也是自適應學習率但長期會讓學習率衰減到太小。所以問哪個內建動量答案是 Adam(SGD+Momentum 是顯式加上動量不算內建)。
第三類是學習率跟早停:學習率太大訓練會震盪、太小會收斂太慢甚至卡住,所以是最關鍵的超參數之一。早停(Early Stopping)是監控驗證集損失,連續多輪沒改善就停止訓練,避免過擬合。實務上要設定 patience(耐心值),例如連續 5 輪沒改善才停,避免被一兩輪的隨機波動誤導。早停監控的是驗證集損失,不是訓練集損失(訓練集會一直下降)、也不是測試集損失(測試集要保留到最後評估,中途用會造成資料洩漏)。
第四類是非線性的引入:如果模型只用線性激活函數,不管疊幾層本質上都是線性模型,沒辦法學複雜特徵。改用 ReLU 之類的非線性激活函數,才能讓深度神經網路發揮表達能力。Sigmoid 雖然也是非線性但有梯度消失的問題,深層網路用 ReLU 是標準做法。
防過擬合的方法有 L1/L2、Dropout、早停、增加訓練資料、降低模型複雜度。注意擴增輸入特徵變數以提升模型表達能力不是防過擬合,反而會加劇過擬合,因為它增加了模型的表達能力(自由度)。
示範解題:以 L1 自動篩選特徵為例
挑題 32 示範,因為它最能展現L1 對 L2 的關鍵差異這個判斷力,而且這個差異是科目三最常考的正則化題型。

題目情境:某電信公司開發客戶流失預測模型,使用大量顧客行為特徵(通話時長、上網頻率、帳單金額、客服聯絡次數等)。團隊發現部分特徵高度相關,同時懷疑有些特徵對流失預測貢獻有限。希望模型在避免過擬合的同時,能自動篩選出較具代表性的特徵。問用哪一種方法最合適。
推理過程:
第一步,辨識題目的兩個需求。一個是避免過擬合,一個是自動篩選代表性特徵。這兩個需求合起來指向能把不重要的特徵壓掉的正則化。
第二步,看選項。A 早停只控制訓練回合不做特徵篩選。B 同時移除多重共線性加 L2,但 L2 不會把係數壓到 0,所以不是自動篩選。C 只用 L2,跟 B 一樣的問題。D 用 L1(Lasso),L1 的懲罰項是參數絕對值的和,數學性質會把不重要的特徵係數壓到剛好 0,等同於把那些特徵剔除,這就是自動篩選。
所以答案是 D。
這個命題的變形題:題 2 用稀疏模型包裝 L1 的核心特性、題 3 用非凸函數包裝局部最優、題 11 用 Random Search 包裝高維參數空間、題 12 用學習率包裝模型權重更新速度、題 17 用 Adam 包裝內建動量機制、題 26 用擴增輸入特徵包裝防過擬合不屬於的選項、題 27 用線性激活函數準確率停滯包裝 ReLU 改進、題 31 用驗證集損失波動包裝早停 patience。
把四類工具建立好,這 9 題你能自己過。
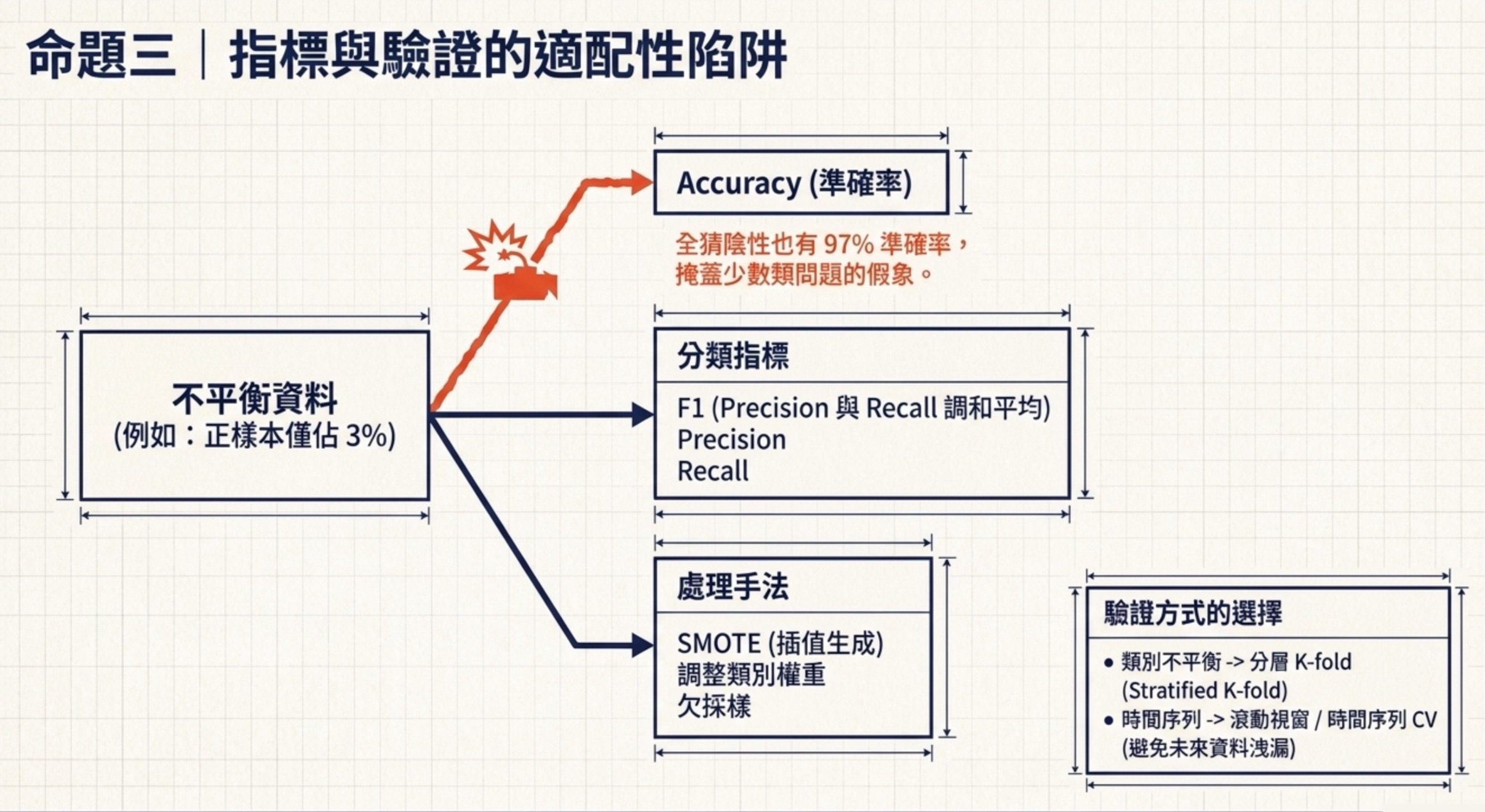
3.指標跟驗證方式對應任務類型
這 9 題的底層命題跟科目二類似,但更深入評估指標的細節:評估指標跟驗證方式不是越複雜越好,要看任務類型跟資料特性。
機器學習技術與應用的評估題,AI 應用規劃師最該避免的是不平衡資料用 Accuracy這種經典錯誤。
評估這層可以拆成五個關鍵點。
第一點是分類指標的選擇。Accuracy 在類別不平衡時會騙人,例如罕見疾病確診率只有 1%,模型全部猜陰性也有 99% Accuracy。所以不平衡資料要看 F1、Precision、Recall。F1 是 Precision 跟 Recall 的調和平均,公式是 2 * P * R / (P + R)。Precision=0.8、Recall=0.6 時,F1 = 2*0.8*0.6/(0.8+0.6) = 0.96/1.4 ≈ 0.686。題目給數字就要會算。
第二點是迴歸指標的解讀。R² = 0.85 不是模型準確率 85%,而是模型解釋了 85% 的變異量,剩下 15% 是模型無法解釋的部分(可能是噪音、可能是缺失的變數)。預測誤差是另一個概念,要看 RMSE 或 MAE。MSE 的數學定義是 sum((y_true - y_pred) ** 2) / len(y_true),公式直接寫出來就是平方誤差的平均。
第三點是不平衡的處理。SMOTE 用插值生成合成樣本、調整類別權重讓模型對少數類更敏感、欠採樣多數類都是有效方法。使用 Accuracy 評估反而會掩蓋問題,所以使用準確率作為評估指標是不平衡資料最不適合的做法。
第四點是驗證方式的選擇。K-fold 是基本款,但類別不平衡時要用分層 K-fold(Stratified K-Fold)。時間序列資料不能用一般 K-fold,因為會造成用未來資料訓練、預測過去的時間洩漏,要用時間序列交叉驗證(Time Series CV)或滾動視窗驗證(Rolling Window Validation)。資料量極少又不平衡時(例如 150 筆、陽性 8%),官方題目的答案是「分層留一法」。考試重點是:不平衡資料要避免抽樣切分破壞類別比例、小資料要盡量保留訓練資料。但嚴格實作上,Leave-One-Out 每折只有一筆驗證資料,無法像 Stratified K-Fold 那樣維持每個 fold 的類別比例;分層的效果體現在訓練集的切法上,確保少數類不會在某折被完全排除。
第五點是殘差圖的診斷。線性迴歸殘差應該隨機散佈在零附近。如果殘差呈現系統性彎曲(例如高價區出現曲線分佈),主要暗示模型規格不足,例如線性模型無法捕捉非線性關係;異常值也可能干擾殘差分布,但不是第一優先解釋。殘差均勻分佈才是模型符合假設的訊號,看到系統性樣態就是模型違反假設。
跨語言模型在新語言資料集上 F1 從 0.91 暴跌到 0.58,最合理的解釋是語言轉移造成召回率下降,模型無法正確辨識關鍵情緒詞彙。這不是 macro F1 的波動性問題、也不是過度擬合(過擬合在訓練集上會表現好,題目沒提訓練集)。
示範解題:以罕見疾病的評估陷阱為例
挑題 19 示範,因為它最能展現不平衡資料的指標陷阱這個 AI 應用規劃師最該避開的反模式。

題目情境:某醫療機構開發疾病早期偵測模型,正樣本(確診病例)僅佔 3%。問下列哪一種作法最不適合用於提升對少數類病例的預測能力。四個選項是 SMOTE 過採樣、調整類別權重、使用準確率作為評估指標、欠採樣多數類。
推理過程:
第一步,辨識題目的關鍵。正樣本只佔 3% 是極度不平衡的場景,而且題目問的是最不適合。
第二步,看每個選項是不是真的有幫助。SMOTE 過採樣是處理不平衡的標準做法,有幫助。調整類別權重讓模型對少數類更敏感,有幫助。欠採樣多數類雖然丟資料但能平衡比例,有幫助。使用準確率作為評估指標,正樣本只有 3% 時,模型全猜陰性也有 97% 準確率,完全看不出模型對少數類的真實表現,反而會誤導決策。
所以答案是 C,使用準確率不適合。
這個命題的變形題:題 1 用銷售預測新資料包裝交叉驗證、題 14 用醫療影像診斷包裝可解釋性的關鍵情境、題 15 用 R² 0.85 包裝變異量解釋、題 16 用 P=0.8 R=0.6 包裝 F1 計算、題 24 用殘差圖系統性彎曲包裝迴歸診斷、題 29 用設備工況變化包裝時間序列 CV、題 30 用跨語言 F1 暴跌包裝召回率下降、題 34 用 150 筆陽性 8% 包裝分層 LOOCV。
把五個關鍵點建立好,這 9 題你能自己過。
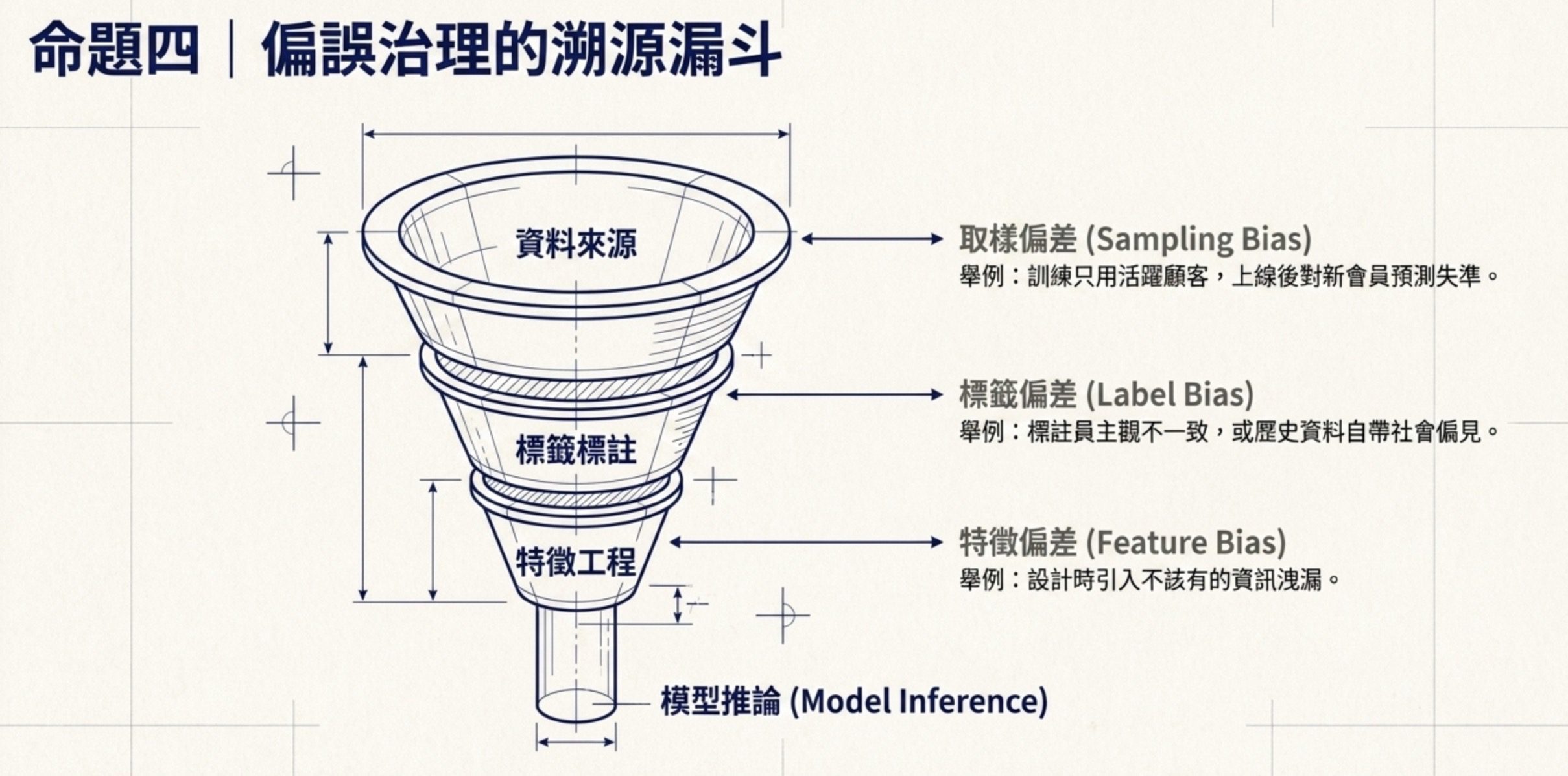
4.資料品質的偏誤要從來源治理
這 6 題的底層命題是:模型上線後出現偏誤,第一優先通常要檢查訓練資料代表性、取樣方式、標籤規則與特徵設計。很多公平性問題在資料蒐集與問題定義階段就已經發生,不要只怪演算法。
機器學習技術與應用考的就是這個分層判斷力,AI 應用規劃師要能在使用者抱怨模型對新會員不準時,優先檢查訓練資料怎麼選的。
資料偏誤可以分成三種典型來源。
第一種是取樣偏差(Sampling Bias):訓練資料的樣本範圍不能代表推論時要面對的整體分佈。例如題 28 的情境:訓練資料只選曾經購買三次以上的活躍顧客,模型在新註冊會員或低消費會員的預測自然不準。這是取樣偏差的標準案例,跟特徵設計、標籤標註、超參數調整都無關。
第二種是標籤偏差(Label Bias):標籤資料本身帶有主觀偏見。例如人工標註某個情緒詞時,不同標註員的判斷不一致;或者歷史資料反映過去的偏見,讓模型學到年輕人比較會違約這種跟現實未必相符的關聯。標籤偏差的原因不是訓練資料量過大、不是模型結構、不是特徵數量,是標註過程本身。
第三種是特徵偏誤/代理變數偏誤(Feature Bias):模型沒有直接使用敏感屬性,但某些特徵高度代理了敏感屬性(例如郵遞區號、消費地點),或特徵設計引入了不該有的資訊洩漏,讓模型學到不可推廣的關聯。
防偏誤的方法在資料層,不是模型層。
距離型模型(KNN、SVM)的特徵縮放也是資料層的基本功,沒做縮放會讓尺度大的特徵主導距離計算。
互動特徵是把兩個或多個特徵做乘積或交互組合,用來捕捉特徵間的關聯影響(例如價格跟滿意度的交互效果)。
不是把單一特徵取平方、不是對所有特徵取對數、不是標準化,那些是其他類型的特徵工程。
DBSCAN 的雜訊點(Noise Point)定義是:鄰域內樣本數不足以形成核心點(Core Point),也未被任何核心點的鄰域包含,且未與其他群集形成密度可達關係。簡單說就是不夠密集、也不在其他群集附近的孤立點。
PCA 的變異量解讀也是資料品質的一部分。三個特徵值 λ1=6、λ2=3、λ3=1,前兩個的累積變異量是 (6+3)/10 = 90%,超過 80% 的門檻,所以保留前兩個主成分是合理的。不要被第二主成分貢獻 30%這種說法誤導,30% 是相對總變異而言,不是 80% 門檻的判斷依據。
示範解題:以高活躍顧客的取樣偏差為例
挑題 28 示範,因為它最能展現訓練資料的選擇決定模型的能耐這個 AI 應用規劃師最該記住的判斷力。

題目情境:某零售電商公司建立顧客流失預測模型,訓練時僅採用曾經購買三次以上的活躍顧客紀錄作為樣本。模型上線後,對整體會員進行預測時,發現對新註冊會員與低消費會員的預測準確率明顯偏低,問造成此現象最可能的原因。
推理過程:
第一步,辨識訊號。訓練樣本只用活躍顧客是關鍵,而題目要解釋模型對新會員跟低消費會員不準,這是典型的訓練分佈跟推論分佈不一致。
第二步,看選項。
A 特徵偏差是特徵設計引入不該有的資訊,題目沒提特徵設計問題。
B 標籤偏差是標籤本身有偏見,題目沒提標籤怎麼來。
C 取樣偏差是訓練樣本不能代表整體,完全符合題目情境,訓練只看活躍顧客,模型自然不會處理新會員。
D 過擬合是在訓練集上太好但泛化差,但題目的問題是特定子群預測差,不是泛化整體不好。
所以答案是 C。
這個命題的變形題:題 4 用 DBSCAN 雜訊點包裝聚類診斷、題 9 用 KNN SVM 包裝距離模型的特徵縮放、題 13 用標籤偏差包裝標註偏見、題 20 用互動特徵包裝特徵工程設計、題 35 用 PCA 變異量包裝降維保留比例的解讀。
把三種偏誤來源建立好,這 6 題你能自己過。
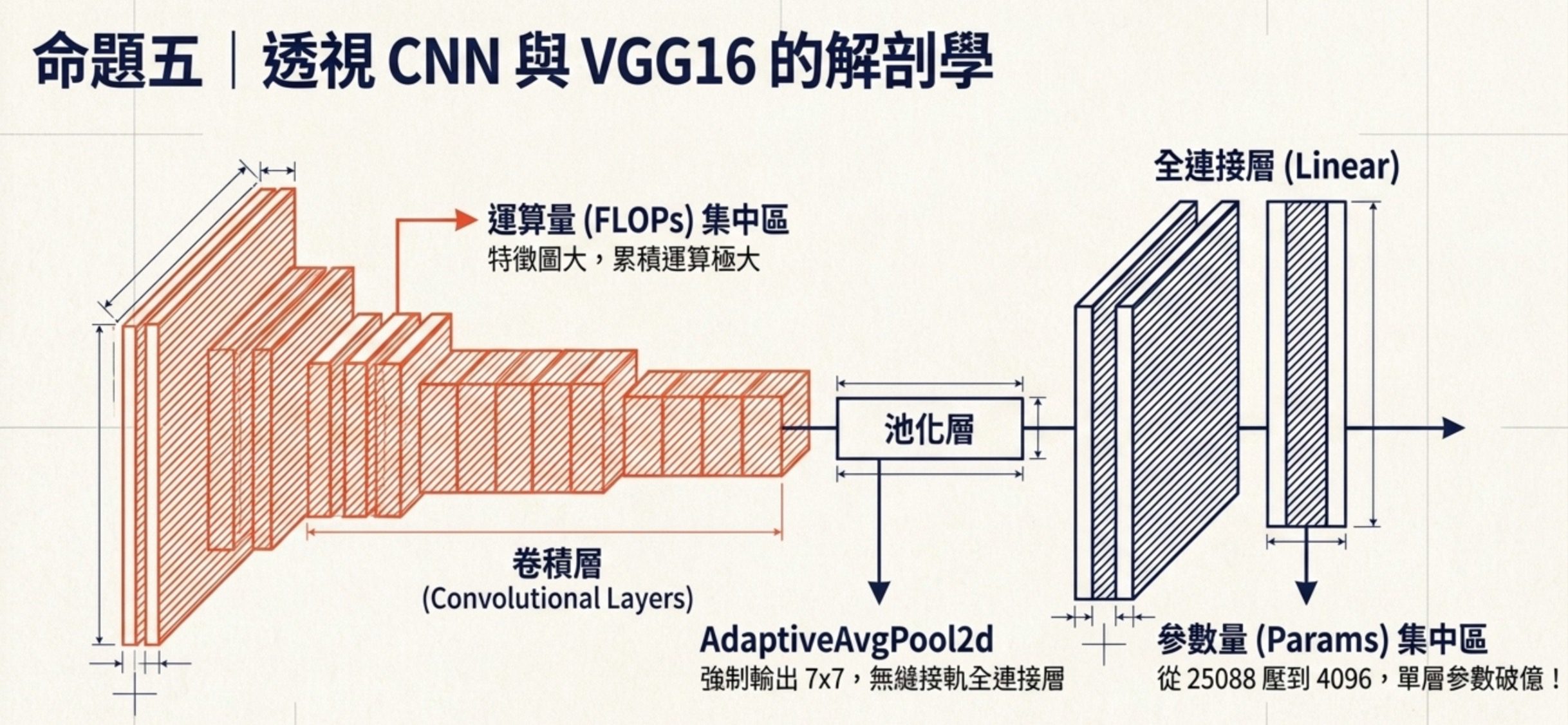
5. CNN 結構與遷移學習
這 5 題的底層命題是:讀懂 CNN 的層結構摘要,跟掌握遷移學習的凍結語法,是科目三深度學習的硬實力。
機器學習技術與應用必考的就是 VGG16 的層結構細節。VGG16 在科目三是必考的範例,因為它結構規則容易考細節。
掌握 CNN 結構需要四個關鍵直覺。
第一個直覺是參數量分佈:CNN 的卷積層雖然有很多層,但每層參數量受限於 kernel size 跟 channel 數,例如 3×3 卷積核從 64 channel 到 128 channel 只有約 7 萬參數。但全連接層(Linear)的參數量會爆量,例如 VGG16 第一個 Linear 從 25088 (=512*7*7) 到 4096,參數量就有 102,764,544,超過一億。所以 CNN 模型的參數最多通常在全連接層,不是卷積層。
第二個直覺是運算量分佈:FLOPs(浮點運算次數)的計算方式是輸出特徵圖大小 × kernel 計算量。早期的卷積層雖然 channel 少,但特徵圖很大(例如 150×150),所以每層的運算量很大。後期的卷積層雖然 channel 多到 512,但特徵圖被池化到 9×9,反而運算量沒那麼大。全連接層的運算量看輸入維度 × 輸出維度,VGG16 的全連接層輸入 25088 輸出 4096,單層運算量約 1 億,但卷積層的累積運算量遠超這個。所以 FLOPs 最多的是卷積層,而參數量最多的是全連接層。
第三個直覺是 AdaptiveAvgPool2d 的特殊行為:VGG16 的分類器固定吃 512×7×7 的向量,因此 PyTorch 版 VGG 用 AdaptiveAvgPool2d((7, 7)) 把最後特徵圖整理成 7×7。若輸入是標準 224×224,最後池化前通常已經接近 7×7;若題目給的是較小或非標準輸入,才可能看到 4×4 再被 adaptive pooling 轉成 7×7。這讓 VGG16 在模型可運算的尺寸範圍內可以處理不同大小的輸入影像(PyTorch 的 VGG16 最小輸入尺寸為 32×32,預訓練推論標準前處理為 224×224)。攤平後傳入第一個全連接層的維度是 512×7×7 = 25088,不是 512×4×4 = 8192。
第四個直覺是遷移學習的凍結語法:model.features.parameters() 是 VGG16 卷積層的參數,凍結這部分才能保留預訓練學到的特徵。model.classifier.parameters() 是全連接層,如果凍結這部分就只能訓練卷積層,跟遷移學習的目的相反。model.parameters() 是全部,凍結等於整個模型都不訓練。model.requires_grad = False 不是凍結模型參數的正確寫法;它不會逐一修改 model 裡的 parameter。凍結卷積層的正確寫法是 for param in model.features.parameters(): param.requires_grad = False,實務上也可使用 model.features.requires_grad_(False)。
示範解題:以 VGG16 遷移學習的凍結語法為例
挑題 45 示範,因為它最能展現讀懂 CNN 結構摘要加上 PyTorch 語法這個整合判斷力。

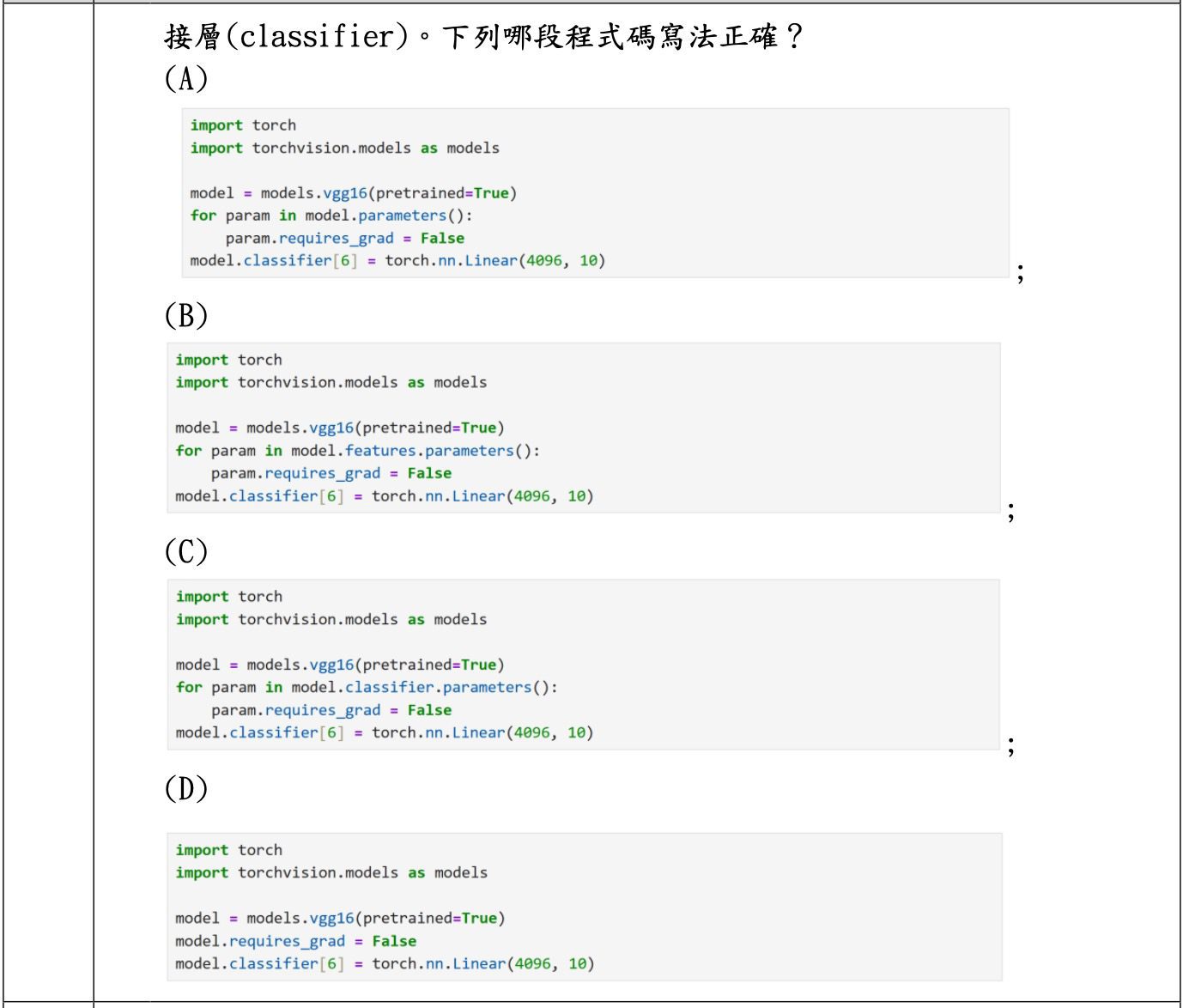
題目情境:對 VGG16 進行遷移學習,要凍結卷積層的參數,只訓練最後全連接層(classifier),問哪一段程式碼寫法正確。
推理過程:
第一步,辨識遷移學習的目的。要保留卷積層學到的影像特徵,只重新訓練分類層。所以要凍結的是 model.features(卷積層),要訓練的是 model.classifier(全連接層)。
第二步,看選項。
A 用 for param in model.parameters(): param.requires_grad = False 凍結整個模型,連 classifier 也被凍結,不對。
B 用 for param in model.features.parameters(): param.requires_grad = False 只凍結卷積層,正確。
C 用 for param in model.classifier.parameters(): param.requires_grad = False 反過來凍結分類層,跟遷移學習目的相反。
D 用 model.requires_grad = False 不是正確的凍結寫法,不會逐一修改 module 內的參數。
第三步,確認 B 後面的 model.classifier[6] = torch.nn.Linear(4096, 10) 是把最後一層換成 10 類輸出,合理。
所以答案是 B。
這個命題的變形題:題 21 用 Multi-head Attention 包裝多頭注意力的多樣化關聯、題 42 用 VGG16 參數量包裝全連接層佔大宗、題 43 用 VGG16 FLOPs 包裝卷積層運算量大、題 44 用 AdaptiveAvgPool2d 7×7 攤平包裝結構細節。
把四個直覺建立好,這 5 題你能自己過。
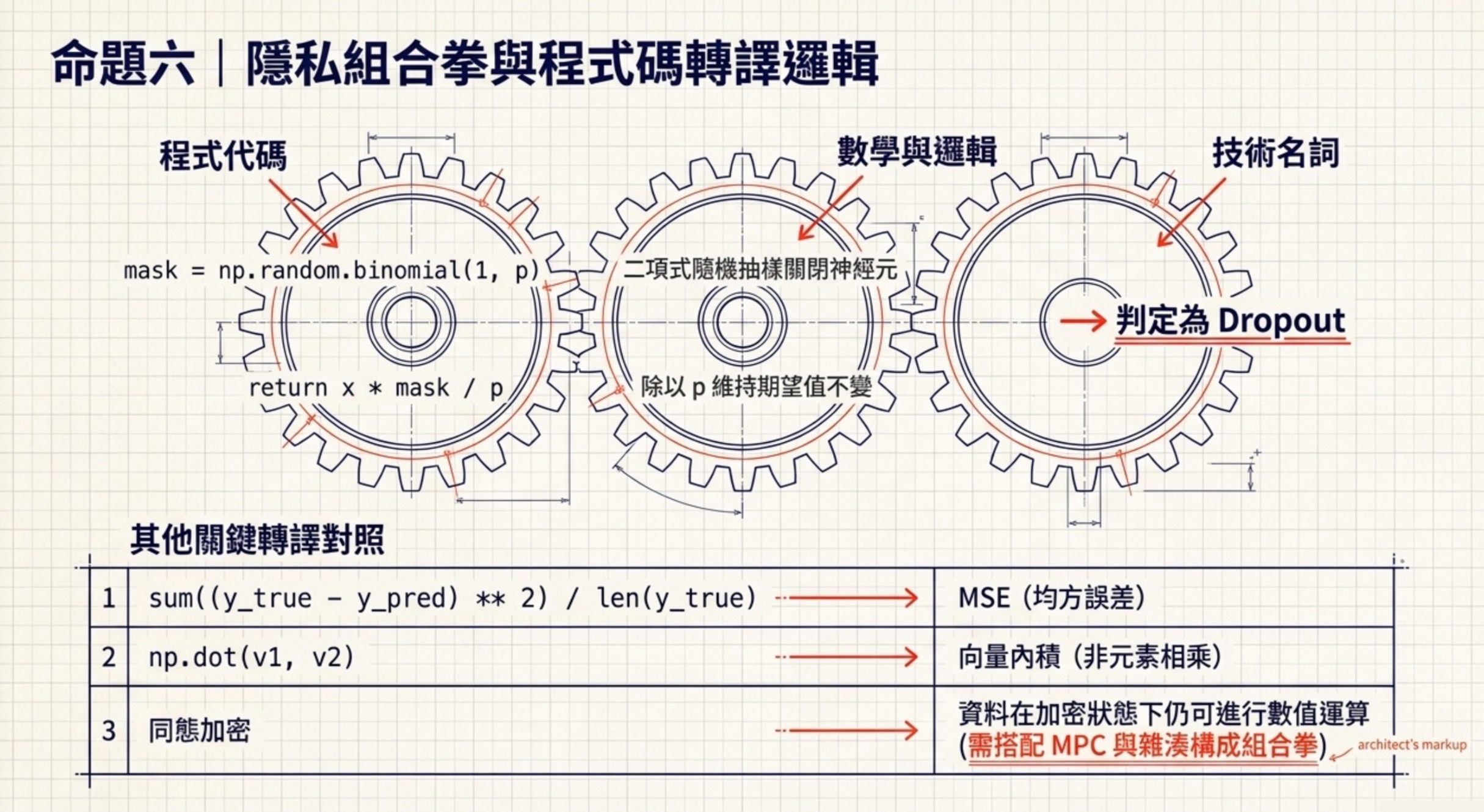
6.隱私技術與程式碼判讀
這 12 題佔了將近四分之一,其中程式碼判讀題又佔了大多數。
底層命題是兩句:隱私技術不是孤立工具而是組合應用,程式碼判讀要從數學公式推回函式語意。
機器學習技術與應用的程式碼題,絕大多數都需要這兩種能力一起用。
隱私技術的部分:同態加密(Homomorphic Encryption)的關鍵特性是允許在不解密的情況下對密文執行特定運算,解密後可得到對應的明文運算結果。它適合隱私敏感的外包運算或雲端分析,但成本、效能與可支援運算型態都有限制。這跟匿名化(去欄位)、雜湊(不可逆但不能還原)、差分隱私(加噪聲)是完全不同的技術。實務上,跨銀行協作需要多種隱私技術組合。依官方第 37 題答案,正確的技術組合是:同態加密 + 非對稱加密 + 單向雜湊 + 對稱加密。同態加密處理「資料不解密也能運算」;非對稱加密處理「安全通訊、金鑰交換、身分驗證」;單向雜湊處理「完整性檢查、防竄改」;對稱加密處理「大量資料傳輸加密」。MPC 雖然也是隱私計算技術,但不是本題官方答案。
程式碼判讀的核心能力可以拆成三個面向。
第一個面向是看數學公式辨識指標:sum((y_true - y_pred) ** 2) / len(y_true) 是平方誤差的平均,直接對應 MSE(Mean Squared Error)的定義。如果再開根號就是 RMSE。MAE 是絕對值的平均,公式不同。R² 是 1 減去殘差平方和 / 總平方和,結構完全不同。
第二個面向是看抽樣邏輯辨識正則化技術:mask = np.random.binomial(1, p, size=x.shape); return x * mask / p 在訓練時用,推論時直接回傳 x,這是 Dropout 的標準寫法,p 是保留機率,除以 p 是維持期望值不變(inverted dropout)。L1/L2 不會用 binomial 抽樣、BatchNorm 用的是統計量不是隨機 mask。
第三個面向是 numpy 跟條件機率:np.dot(v1, v2) 是向量內積,1*4 + 2*5 + 3*6 = 32。v1 * v2 是元素相乘(element-wise),結果是 [4, 10, 18] 不是 [5, 7, 9]。np.linalg.inv(A) 是反矩陣,不是行列式(行列式是 np.linalg.det)。np.linalg.eig(A) 是特徵值跟特徵向量,不是反矩陣。Monte Carlo 計算 P(A|B) 的條件機率,用同時發生 A 跟 B 的次數除以B 發生的次數,所以是 A_and_B.sum() / B.sum(),不是除以 A 或除以兩者和。
時間複雜度的部分,要逐一比對每位顧客跟其他所有顧客,組合數是 n*(n-1)/2 ≈ O(n²),代表執行時間跟資料量平方成正比。當資料量從 1 萬變 10 萬,時間會變 100 倍。
示範解題:以 Dropout 的數學定義為例
挑題 39 示範,因為它最能展現從程式碼結構辨識技術這個判斷力。

題目情境:程式碼如下:def forward(x, p, training=True): if training: mask = np.random.binomial(1, p, size=x.shape); return x * mask / p; else: return x。問這實現的是哪一種正則化技術。
推理過程:
第一步,看 import 跟函式結構。函式有 training 參數,訓練跟推論行為不同,這是有訓練模式切換的技術。
第二步,看訓練時做什麼。np.random.binomial(1, p, size=x.shape) 是按機率 p 隨機抽 0 或 1 的 mask,然後 x * mask / p 是用 mask 關掉一部分輸入再除以 p 縮放。隨機關掉一部分加上除以 p 縮放保持期望是 Dropout 的標準特徵(inverted dropout)。
第三步,排除其他選項。L1 正則化是在損失函數加懲罰項,不會在 forward 函式做、L2 正則化也是、Batch Normalization 用統計量不用 binomial 抽樣。
所以答案是 C。
這個命題的變形題:題 33 用 O(n²) 包裝時間複雜度、題 36 跟題 37 用同態加密包裝隱私技術組合、題 38 用 MSE 公式包裝指標判讀、題 40 用 numpy 矩陣運算包裝內積跟特徵值、題 41 用 Monte Carlo 條件機率包裝 P(A|B) 計算、題 46 用 PCA 降噪包裝 inverse_transform、題 47 用 cross_val_score 包裝 KNN 驗證、題 48 用 X_train -= mean 包裝標準化的數學動作、題 49 用 Dense 層的 Param 包裝參數量計算(Param = 輸入維度 × 輸出維度 + 偏差項數量)、題 50 用 matplotlib 線條樣式包裝 "b-"(藍色實線,Training Loss)跟 "r--"(紅色虛線,Validation Loss)的繪圖語法。
把三個面向練熟,這 12 題你能自己過。
AI 應用規劃師中級科目三最容易混淆的 12 組概念對照
學完六大命題,考前最後一週把下面這 12 組高混淆概念兩兩比較一次。能用自己的話講出差異就過關,講不出來就回去翻對應的命題。
| 兩個概念 | 差異關鍵 |
|---|---|
| L1 vs L2 正則化 | L1 把不重要的係數壓到 0 適合特徵選擇,L2 把所有參數拉小但不歸零 |
| SGD vs Adam vs RMSProp vs Adagrad | SGD 基本款,Adam 同時內建動量跟自適應學習率,RMSProp 核心是自適應學習率(框架可選 momentum),Adagrad 學習率會衰減過小 |
| CNN vs LSTM vs Transformer | CNN 處理空間關係,LSTM 處理時序長依賴,Transformer 透過 self-attention 捕捉序列中遠距位置的關係,但可處理長度仍受 context window 與計算成本限制 |
| ReLU vs Sigmoid vs 線性 | 線性沒法學非線性特徵,Sigmoid 有梯度消失問題,ReLU 是深度網路的標配 |
| Accuracy vs F1 vs Precision vs Recall | Accuracy 不平衡時騙人,F1 是 Precision 跟 Recall 的調和平均 |
| Grid Search vs Random Search vs Bayesian | Grid 全試但慢,Random 高維高效,Bayesian 根據歷史結果動態調整 |
| K-fold vs Stratified vs Time Series CV | K-fold 純隨機,Stratified 保比例,Time Series 避免時間洩漏 |
| Dropout vs BatchNorm vs Early Stopping | Dropout 隨機關神經元,BatchNorm 穩定訓練順便有正則化效果,Early Stopping 監控驗證集 |
| 取樣偏差 vs 標籤偏差 vs 特徵偏差 | 取樣是訓練集不代表整體,標籤是標註有偏見,特徵是設計引入不該有的資訊 |
| 卷積層 vs 全連接層 | 卷積層運算量大但參數少,全連接層參數多但每筆運算少 |
| 同態加密 vs 差分隱私 vs MPC | 同態加密能加密下運算,差分隱私加噪聲,MPC 多方協作不洩漏各方資料 |
| SMOTE vs Random Oversampling vs Undersampling | SMOTE 插值生成,Oversampling 重複貼上易過擬合,Undersampling 丟資料 |

總結:用命題思維準備中級科目三
AI 應用規劃師中級科目三(機器學習技術與應用)這份考卷,真正在測的不是 50 個獨立的名詞,而是 6 個底層命題:看任務挑模型、訓練平衡擬合不足跟過擬合、指標跟驗證方式對應任務、資料品質的偏誤治理、CNN 結構與遷移學習、隱私技術與程式碼判讀。
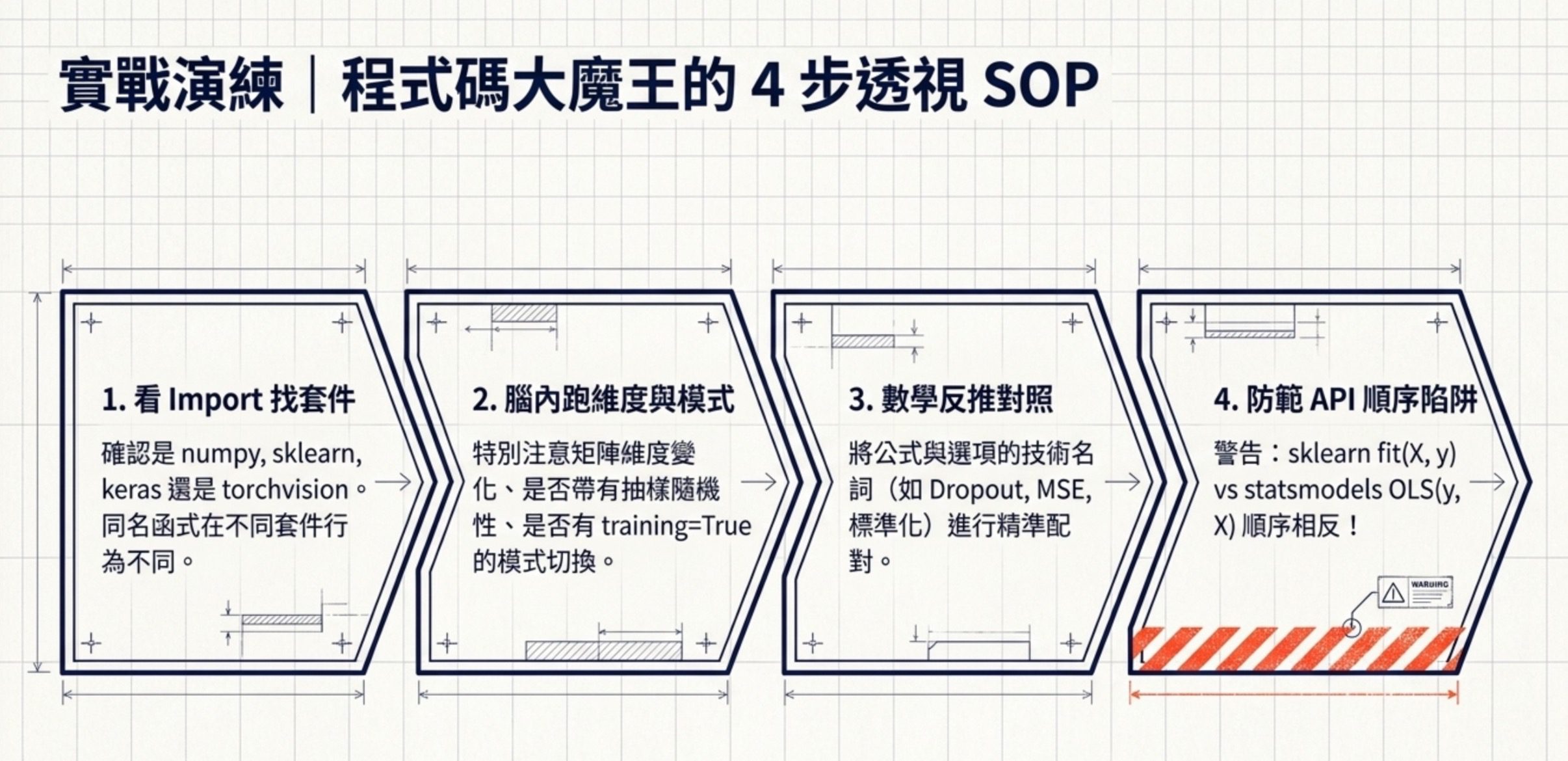
進考場的程式碼題解題流程,我建議固定這四步。
第一步,先看 import 確認用了哪個函式庫(numpy、sklearn、keras、torchvision、scipy.stats),不同函式庫的同名函式行為不同。
第二步,在腦中執行一次程式碼,特別注意維度變化、是否有抽樣、是否有訓練推論模式切換。
第三步,對照選項,看哪個結果對得上。
第四步,記得 sklearn 的 fit() 順序是 (X, y),statsmodels 的 OLS 順序是 (y, X),別搞錯。
iPAS AI 應用規劃師中級科目三的設計初衷,是檢核你能不能在機器學習專案裡擔任技術規劃的角色。能在六大命題之間做出正確判斷、能讀懂 numpy 跟 keras 的常見語法,就能通過科目三,祝各位考試順利!
考前白話詞表:44 個科目三必考名詞
| 原名詞 | 白話翻譯 | 一句話記憶 |
|---|---|---|
| CNN | 看圖片小區塊的模型 | 不是一次看整張圖,而是用小視窗掃過去找特徵 |
| Convolution Kernel | 掃描用的小濾鏡 | 像一個小放大鏡,專門找邊緣、線條、紋理 |
| Local Receptive Field | 只看局部區域 | 每個神經元只負責看圖片的一小塊 |
| Parameter Sharing | 同一組濾鏡重複用 | 一把規則掃全圖,所以參數比較少 |
| Pooling | 壓縮特徵圖 | 保留重點、縮小尺寸、降低運算量 |
| AdaptiveAvgPool2d | 固定輸出尺寸的平均池化 | 不管前面特徵圖多大,最後整理成指定格數 |
| Fully Connected Layer / Linear | 全部接在一起的分類層 | 把前面抽出的特徵拿來做最後判斷 |
| Parameters | 模型要學的數字 | 模型記在腦中的權重數量 |
| FLOPs | 運算量 | 模型算一次大概要做多少計算 |
| Transfer Learning | 拿現成模型再改最後幾層 | 用別人已學好的底子,換成自己的任務 |
| Freeze Layers | 凍結層 | 這些權重不再更新,只訓練後面幾層 |
| LSTM Gate | 記憶開關 | 決定舊資訊要留下、丟掉,或寫入新資訊 |
| Multi-head Attention | 多組視角同時看關係 | 一組看語意,一組看位置,一組看其他關聯 |
| Overfitting | 背答案 | 訓練題很會,換新題就不行 |
| Underfitting | 學不夠 | 連訓練題都學不好 |
| Regularization | 限制模型不要太任性 | 加一點約束,避免模型連雜訊都背起來 |
| L1 / Lasso | 把沒用特徵剪掉 | 會把部分權重壓成 0,適合特徵選擇 |
| L2 / Ridge | 把權重壓小 | 不一定歸零,但避免某些權重過大 |
| Dropout | 訓練時隨機關掉神經元 | 強迫模型不要太依賴固定路線 |
| Batch Normalization | 幫每層輸入重新校準 | 讓數值分布穩定,訓練比較順 |
| Learning Rate | 每次修正的步伐大小 | 太大會亂跳,太小會學很慢 |
| Early Stopping | 見好就收 | 驗證集沒變好就停止,避免越練越過擬合 |
| Accuracy | 整體猜對率 | 類別不平衡時很容易騙人 |
| Precision | 抓到的人裡,有多少是真的 | 預測為陽性的人,有多少真的是陽性 |
| Recall | 真的有病的人裡,抓到多少 | 真陽性有多少被模型找出來 |
| F1 Score | Precision 和 Recall 的折衷分數 | 兩邊都不能太差 |
| R² | 模型解釋了多少變動 | 不是準確率,是解釋變異量 |
| SMOTE | 造出新的少數類樣本 | 用少數類附近的點內插產生新資料 |
| Stratified K-fold | 分層切資料 | 每一折盡量保留原本的類別比例 |
| Time Series CV | 不能偷看未來的驗證法 | 時間序列資料要用過去預測未來 |
| Sampling Bias | 抽樣抽錯人 | 訓練資料不能代表真正會遇到的人 |
| Label Bias | 答案本身有偏見 | 標註或歷史決策本來就不公平 |
| Feature Bias | 餵了會讓模型歪掉的線索 | 特徵可能不公平、上線拿不到,或偷帶答案 |
| Data Leakage | 偷看答案 | 訓練時用了預測時不可能知道的資訊 |
| PCA | 把很多欄壓成幾個代表方向 | 保留主要變化,捨掉比較小的變化 |
| Explained Variance | 保留下來的資訊比例 | 主成分解釋了多少原始資料變動 |
| DBSCAN Noise Point | 孤兒點/雜訊點 | 附近不夠密,也不屬於任何群 |
| Homomorphic Encryption | 加密狀態下也能算 | 不解密也能做某些運算 |
| Asymmetric Encryption | 公鑰上鎖、私鑰解鎖 | 常用於安全通訊、金鑰交換、身分驗證 |
| Symmetric Encryption | 同一把鑰匙加解密 | 適合大量資料快速加密傳輸 |
| One-way Hash | 資料指紋 | 可檢查有沒有被改,但不能還原原文 |
| Differential Privacy | 統計結果加雜訊 | 讓單一個人的資料不容易被反推出來 |
| MPC | 大家一起算,但不亮底牌 | 多方合作計算,各自不公開原始資料 |
| O(n²) | 平方級時間 | 資料變 10 倍,時間可能變 100 倍 |
推薦閱讀
- [新手入門] 中級科目三:費曼學習法,6 個故事讓你讀完就懂
- iPAS AI 應用規劃師中級科目二:大數據處理分析與應用 6 大核心命題
- iPAS AI 應用規劃師中級科目一:人工智慧技術應用與規劃 7 大核心命題
參考資料
iPAS 經濟部產業人才能力鑑定 (2025). AI 應用規劃師中級能力鑑定考試簡章
iPAS 經濟部產業人才能力鑑定 (2025). 114 年第二次 AI 應用規劃師中級能力鑑定公告試題第三科
PyTorch Documentation (2025). torchvision.models.vgg16
Scikit-learn Documentation (2025). Cross-validation: evaluating estimator performance
Keras Documentation (2025). The Sequential model
IBM (2025). What is Convolutional Neural Network
IBM (2025). What is Long Short-Term Memory (LSTM)
FAQ
AI 應用規劃師中級科目三跟科目二最大的差別是什麼?
科目二是大數據分析(pandas、seaborn、統計推論),科目三是機器學習技術(模型訓練、評估、深度學習、優化器)。兩科都有大量程式碼判讀題,但科目三的程式碼題更技術導向,要會看 Dropout 的數學定義、VGG16 的層結構摘要、PyTorch 的凍結語法。
六大命題裡面該優先讀哪幾組?
優先讀程式碼判讀那組(12 題)跟模型選擇那組(9 題),加起來 21 題,佔分將近一半。如果有 CNN/深度學習基礎,加上 CNN 結構直覺(5 題)會很穩。傳統 ML 跟訓練細節要平均花時間,不要押在某一個演算法上。
VGG16 為什麼這麼常考?
因為它結構規則容易出細節題,而且是遷移學習的經典範例。考試常考的點是參數量分佈(全連接層佔最多)、運算量分佈(卷積層佔最多)、AdaptiveAvgPool2d 的特殊行為(輸出固定 7×7)、凍結語法(`model.features.parameters()` 凍結卷積層)。把這四個點記熟,VGG16 相關題目都不會錯。
不平衡資料的處理跟評估指標怎麼配?
處理用 SMOTE、調整類別權重、欠採樣多數類;評估用 F1、Precision、Recall、ROC-AUC,但不要只用 Accuracy 當主要判斷依據。更穩的做法是搭配 Precision、Recall、F1、PR-AUC 或混淆矩陣。考試最愛考的反模式就是不平衡資料只看 Accuracy,看到這個組合要特別小心。
模型上線後對特定子群不準是什麼問題?
第一優先要檢查的是取樣偏差,不是過擬合也不是模型架構。AI 應用規劃師遇到這種情境,優先檢查訓練資料怎麼選的、有沒有排除某些族群、推論時要面對的人口分佈跟訓練時是不是一致。
考前最後一週怎麼複習最有效?
不要重看名詞解釋,改成做命題到題目的反向練習。隨機翻一題考古題,給自己 5 秒判斷它屬於六大命題的哪一組,再做答案。程式碼題每天練 3 到 5 題,實際在筆電上打一遍,比看十題還有效。VGG16 跟 Dropout 這兩個題型一定要練到不假思索。
![[新手入門] 中級科目三:費曼學習法,6 個故事讓你讀完就懂](https://www.techhanlin.tw/wp-content/uploads/2026/05/l23-768x419.jpg)