iPAS AI 應用規劃師中級跟初級差別?從 150 題考古題看穿出題思維
如果你考過初級,再打開中級考古題,第一個感覺通常不是「變難了」,而是「怎麼看不懂題目在問什麼」。
初級會直接問你:情感分析的主要目的是什麼?你只要知道「判斷文本的情感傾向」就能選對。中級也有這種定義題,但更常出現的是這種問法
例如中級會問:某電商平台導入情感分析模型後,發現不同語言和族群的評論判斷結果明顯不一致,部分語氣強烈的正面評論被誤判為負面。從技術與資料治理的角度,下列哪一項描述不正確?
同一個概念,初級多數時候測你「認不認得」,中級更常測你「會不會在情境裡判斷」。中級仍會出少量基礎定義題,但整體考法明顯偏向情境應用。
這篇不是教你「第一週讀什麼」,是幫你整理 114 年中級三科共 150 題公告試題,歸納出題者常見的出題策略,三科之間重疊的核心概念,以及如果你是出題老師,下次最可能怎麼出。
目標是讓你讀完這篇之後,看到任何一題中級考題,能在 10 秒內判斷「這題在用什麼策略考我」。
出題者的 5 種常見出題策略
150 題看起來很多,但114 年第二梯次中級公告試題可概括為 5 種常見出題策略,你不需要背 150 個答案,你需要看穿這些策略。
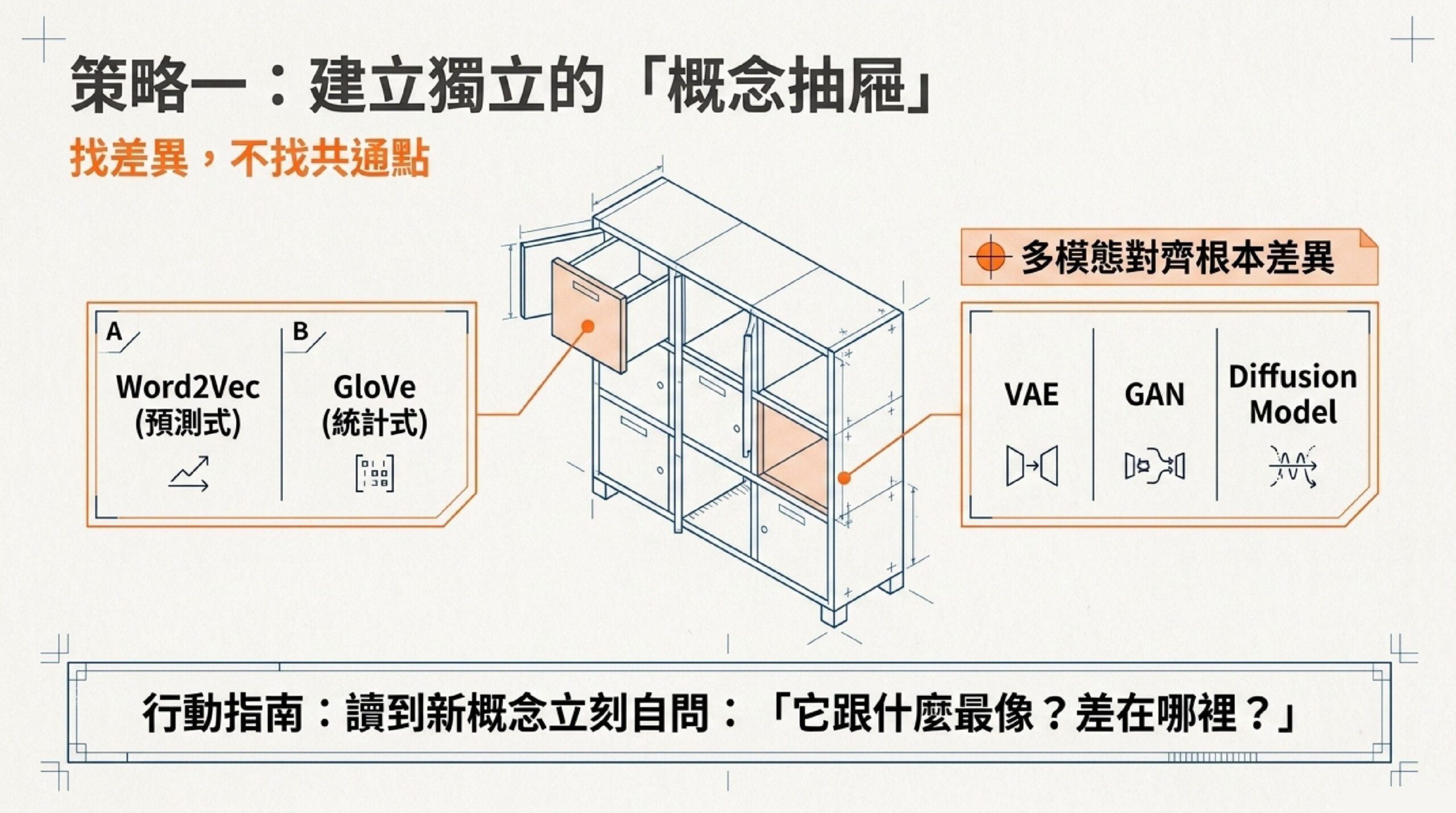
策略一:長得很像的東西,你分得清嗎
出題者最愛做的事,就是把兩三個容易搞混的概念放在同一題的選項裡。他不是在問你「知不知道 A」,他是在確認你腦中的 A 和 B 是分開放的,不是混在一起。
考古題裡有一題問 Word2Vec 和 GloVe 的差異。如果你只背了「都是詞向量」,四個選項你分不出來。
但如果你知道 Word2Vec 是預測式詞向量模型,包含 CBOW(用上下文預測中心詞)和 Skip-gram(用中心詞預測周圍詞)兩種架構;GloVe 則是基於全域共現統計的詞向量方法,答案就很明確。
另一題問自駕車影像辨識該用哪種分割技術,選項有語義分割、物件偵測、實例分割、全景分割。
它在測你能不能分清楚這四個層級:語義分割只管「每個像素是什麼類別」,實例分割進一步區分「同類的不同個體」,全景分割則是兩者結合。題目說要同時辨識類別又要區分個體,所以答案是全景分割。
還有一題直接要你比較 VAE、GAN、Diffusion Model 三個生成模型在多模態潛在空間對齊上的根本差異。如果你只知道「都是生成模型」,這題完全沒辦法答。
這種策略在三科都出現。科目二反覆考 Label Encoding、One-Hot Encoding、Target Encoding 的差異。科目三考 L1(Lasso)和 L2(Ridge)正則化的差別,還考 Grid Search 和 Random Search 各自的優勢。
出題者的意圖:他要確認你腦中每個概念都是「獨立的抽屜」,不是一鍋粥。初級可以一鍋粥混過去,中級不行。
你該怎麼準備:每次讀到一個新概念,立刻問自己「它跟什麼最像?差在哪裡?」。如果你說不出差異,就是還沒真的懂。
下次可能怎麼考:出題者還沒考過的易混淆組合很多。例如 Batch Normalization vs Layer Normalization、Adam vs AdaGrad vs RMSProp 的完整比較、SMOTE vs Random Oversampling 的副作用差異。
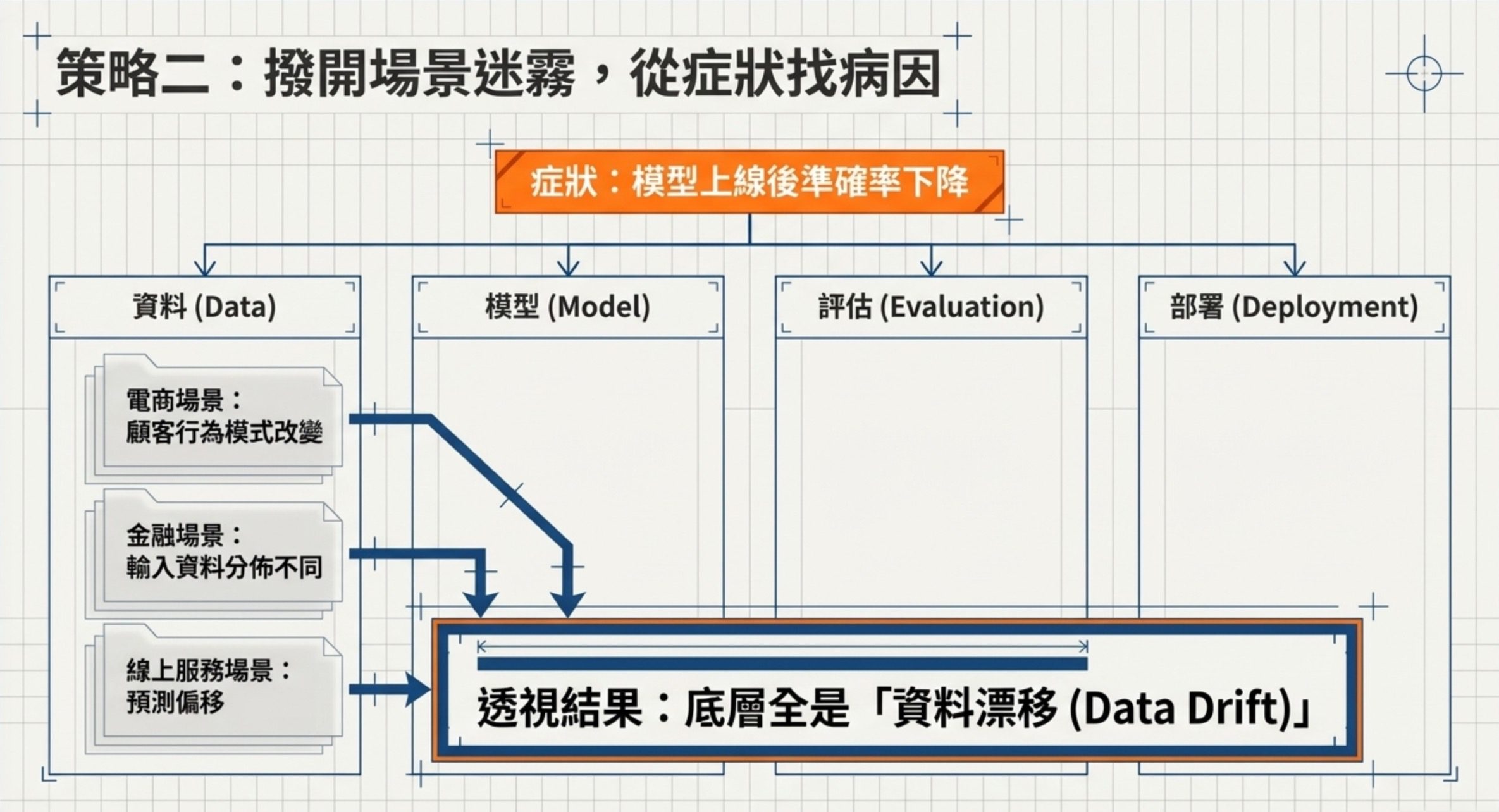
策略二:給你一個症狀,你能找到真正的病因嗎
出題者會描述一個「模型出事了」的場景,然後選項裡放三個看起來合理但不是根因的東西。這是中級最核心的題型。
最明顯的例子是 Data Drift(資料漂移)。這個概念在科目一出了三題,全部都是「模型上線後表現變差」的情境,只是換了不同產業:
- 電商場景:顧客流失預測模型上線數月後,準確率明顯下降。專案團隊懷疑顧客行為模式改變,輸入特徵分佈與訓練資料不同。
- 金融場景:深度學習分類器部署到金融風控系統後,分類錯誤率顯著上升,輸入資料分佈已與原訓練集明顯不同。
- 線上服務場景:即時預測顧客流失的模型,預測準確率逐漸下降,輸入資料的分佈與訓練資料相比出現顯著偏移。
三題的病因完全一樣:模型上線後,真實世界的資料分佈改變了,但模型還在用舊的訓練資料做判斷。出題者用三個不同產業包裝同一個概念,測你能不能看穿表面場景。
但選項的陷阱都不一樣。其中一題的干擾選項是「定期重新訓練模型」,聽起來合理,但題目問的是「怎麼偵測漂移」,不是「怎麼解決」。另一題的干擾是「改用邏輯迴歸提升穩定性」,那是換模型,不是解決分佈偏移。
科目三也有一題考類似的東西:工業設備故障預測模型部署後,隨著設備運行環境改變,原有驗證集已無法反映現況,預測準確率逐漸下降。答案是改用時間序列交叉驗證(Rolling Window),讓驗證資料跟著時間演進。
同一個「症狀找病因」策略,還出現在這些場景:
- 資料增強後模型效能反而下降 → 病因是增強後的資料分佈與原始不一致,破壞了語意。
- ARIMA 模型建完後,殘差呈現週期性波動且自相關顯著不為零 → 病因是模型欠擬合,沒捕捉到時間依賴性。
- 多任務學習中,一個任務的準確率提升,另一個任務反而下降 → 病因是 Loss Function 的權重沒平衡,任務間互相競爭。
- 迴歸模型的殘差圖出現系統性彎曲 → 病因是存在異常值(Outlier)或非線性關係,違反迴歸假設。
- 影像瑕疵檢測模型使用線性激活函數,訓練準確率長期停滯 → 病因是線性激活無法學習複雜特徵,要換 ReLU。
- 英文情感模型部署到西班牙文後 F1 驟降至 0.58 → 病因是語言轉移造成 Recall 下降,模型無法辨識關鍵情緒詞彙。
出題者的意圖:他測的是診斷能力。你能不能從「模型壞了」這個症狀,回推到底是資料問題、模型問題、部署問題、還是評估問題。在真實 AI 專案裡,這就是規劃師最核心的能力。
你該怎麼準備:每次讀到一個「模型出問題」的題目,先分類:這是資料問題(漂移、偏誤、不平衡)、模型問題(過擬合、欠擬合、架構不對)、評估問題(指標選錯、驗證方法不對)、還是部署問題(環境差異、版本管理)。分類對了,答案範圍就縮小 75%。
下次可能怎麼考:「模型上線後出問題」這個母題還有很多變體沒考過。例如:Concept Drift 與 Data Drift 的獨立辨別(Concept Drift 已在監測題的選項中出現,但尚未被獨立考定義差異)、模型在 A/B 測試裡表現好但全量部署後變差(選擇偏差)、模型預測速度隨時間變慢(不是 Data Drift,是系統層問題)。
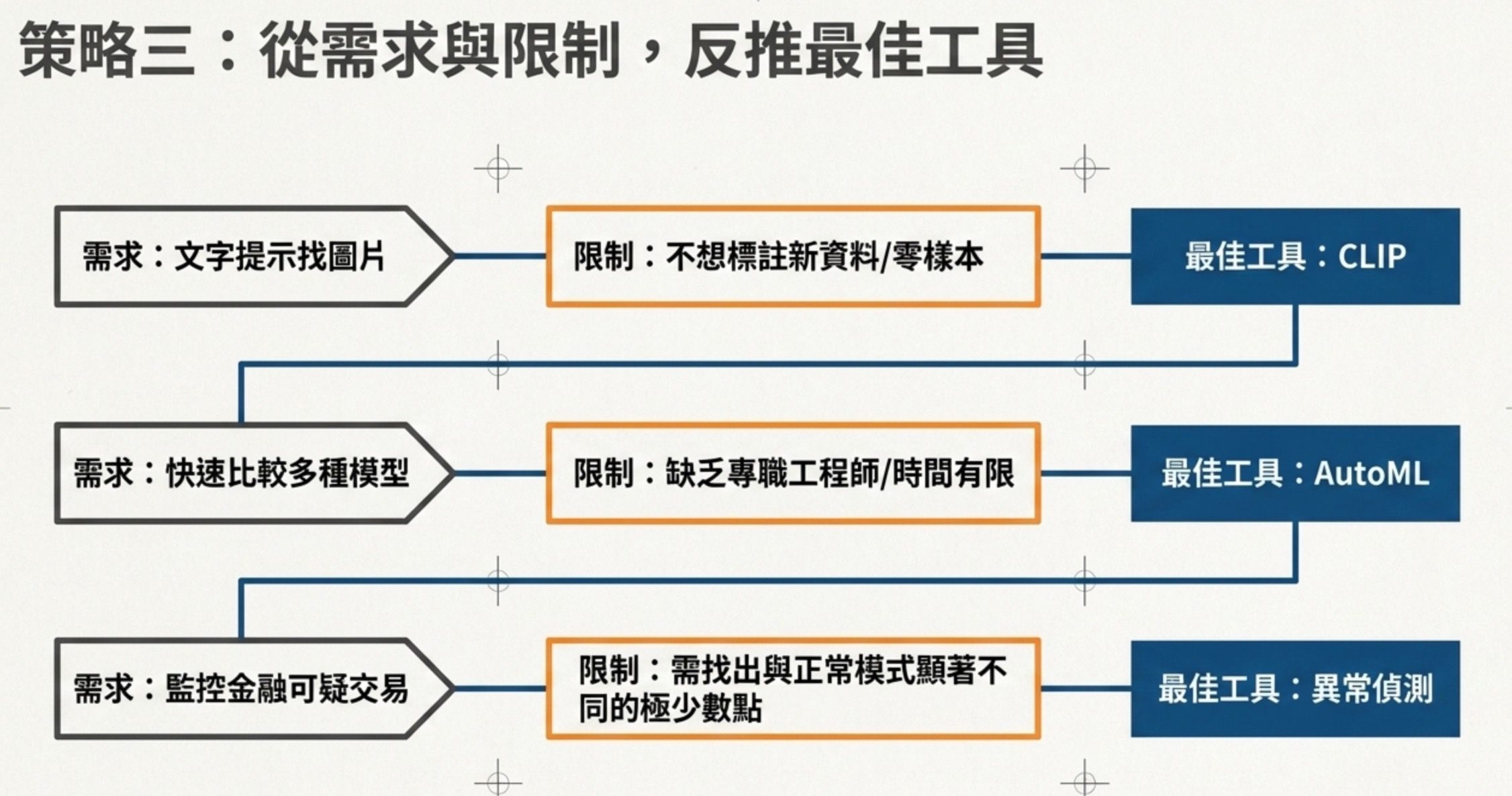
策略三:這個工具該用在什麼時候
給你一個企業場景,測你能不能選出正確的技術,這種題目的關鍵不是你認不認得那個技術名詞,而是你有沒有辦法從需求反推工具。
有一題問哪種情境最適合用 Seq2Seq 模型,選項有銷售預測、命名實體辨識、關鍵字頻率統計、自動翻譯或摘要。
關鍵判斷是:Seq2Seq 的本質是「一段序列進去,另一段序列出來」,翻譯和摘要正好是這個模式。
銷售預測是數值預測,命名實體辨識是序列標註,關鍵字統計根本不需要模型。
另一題描述媒體公司要用文字提示找圖片,而且不想標新資料,問關鍵技術特性是什麼。答案是 CLIP 的對比學習:把圖文映射到共同嵌入空間,所以能做零樣本分類。如果你不知道 CLIP 是什麼,但知道「零樣本 + 文字找圖 = 需要圖文共同空間」,也能選對。
科目二有一題問哪種情境最適合用異常偵測技術,選項有庫存預測、信用風險評估、金融可疑交易監控、登入量趨勢預測。關鍵是異常偵測的定義:找出跟正常模式「明顯不同」的資料點。金融可疑交易正好符合。其他選項都是預測任務,不是偵測異常。
科目三有一題問 AutoML 最適合哪種情境。在這題的四個選項中,AutoML 最適合的是缺乏專職工程師、時間有限、需要快速比較多種模型的情境。已有成熟 MLOps 團隊或需要高度客製化的金融模型,並非完全不能用 AutoML,而是相較之下不是這題的最佳答案。
出題者的意圖:他要你證明你不是只會背工具名稱,而是理解每個工具「解決什麼問題」和「在什麼條件下適用」。
你該怎麼準備:讀每個技術時,寫下三件事:它解決什麼問題、它的輸入和輸出是什麼、什麼時候不該用它。「不該用」比「該用」更重要,因為干擾選項通常是「看起來相關但不適合」的工具。
下次可能怎麼考:出題者可能會考更細的情境配對。例如:什麼時候該用 LoRA 微調而不是全量微調、什麼時候該用 Knowledge Distillation 而不是直接部署大模型、什麼時候該用 RAG 而不是直接微調。
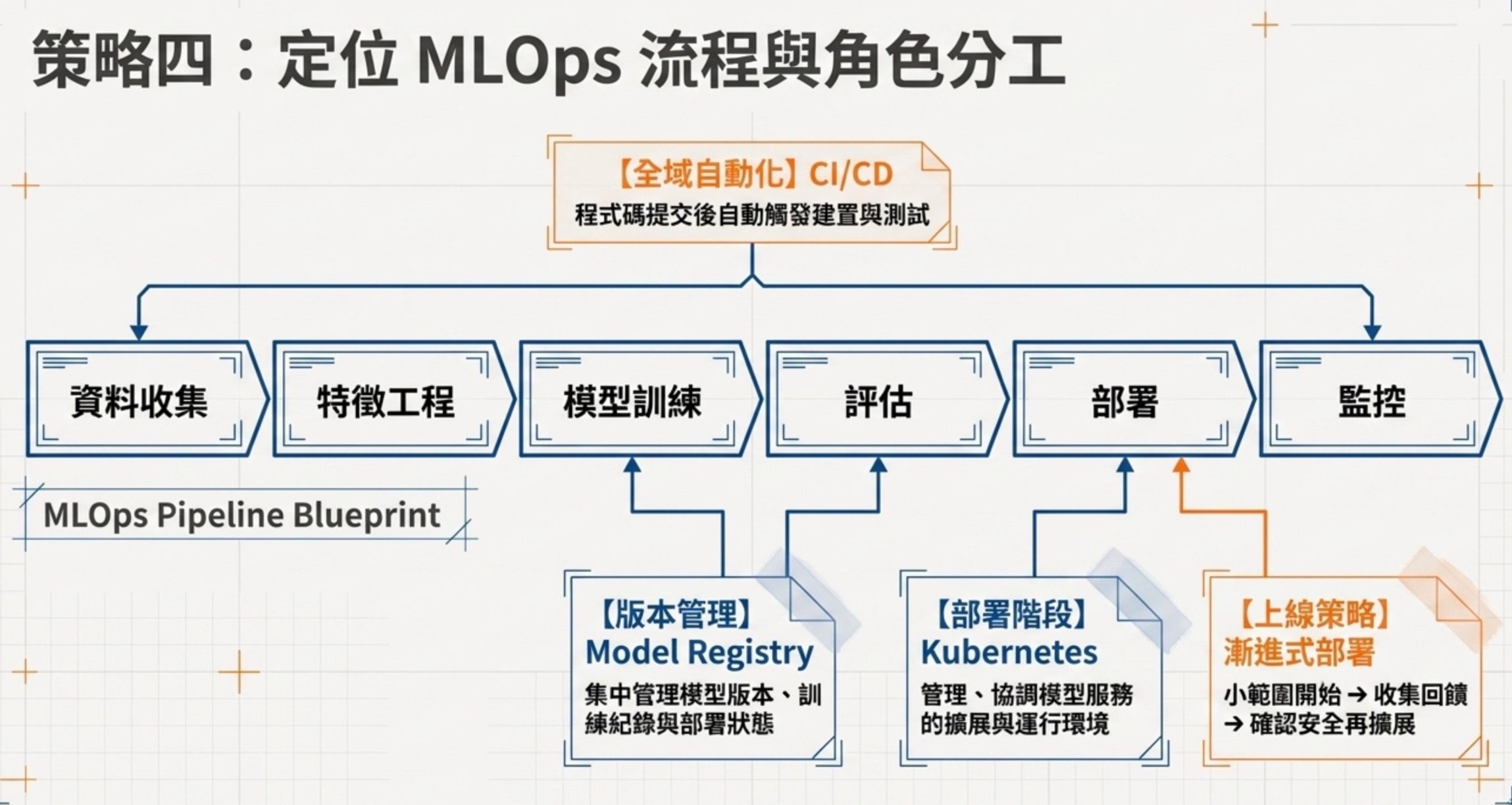
策略四:AI 專案流程的角色分工
中級有一批題目不是考技術本身,而是考你知不知道 AI 專案裡每個環節「誰負責什麼」。
有一題問 Kubernetes 在 AI 模型部署中的核心功能。答案是管理和協調模型服務的部署、擴展與運行環境。如果你選了「自動化管理訓練流程」或「版本控管」,那就是搞混了 Kubernetes(部署管理)跟 Model Registry(版本管理)或 MLflow(實驗管理)的角色。
緊接著有一題問 Model Registry 用於 MLOps 的哪個階段,答案是集中管理模型版本、訓練紀錄與部署狀態。還有一題問 CI(持續整合)的核心實踐,答案是每次程式碼提交後自動觸發建置與測試。另一題問金融監管的不可否認性(Non-repudiation)怎麼落實,答案是 Hash + 數位簽章。
有一題描述醫院要導入 AI 輔助診斷系統,問漸進式部署策略怎麼選。答案是從單一專科開始逐步擴展。選項裡的「先部署在急診」「只在夜班啟用」「全院同步用提示模式」都聽起來合理,但漸進式部署的核心精神是從小範圍開始、收集回饋、確認安全後再擴展,不是一口氣全院上線。
出題者的意圖:中級的目標是培養「能跟工程師和主管一起討論 AI 專案」的人。所以你要知道專案裡的每個角色(部署、版本管理、監控、CI/CD、治理)各自負責什麼,不能全部混在一起。
你該怎麼準備:畫一張 AI 專案流程圖:資料收集 → 資料處理 → 特徵工程 → 模型訓練 → 模型評估 → 部署 → 監控 → 更新。每個環節標上對應的工具和角色。考題裡的每個選項,你都要能對應到流程圖上的正確位置。
下次可能怎麼考:Feature Store、Data Versioning(DVC)、Model Monitoring Dashboard、A/B Testing 在部署後的角色,這些都是 MLOps 流程中還沒被考到的環節。
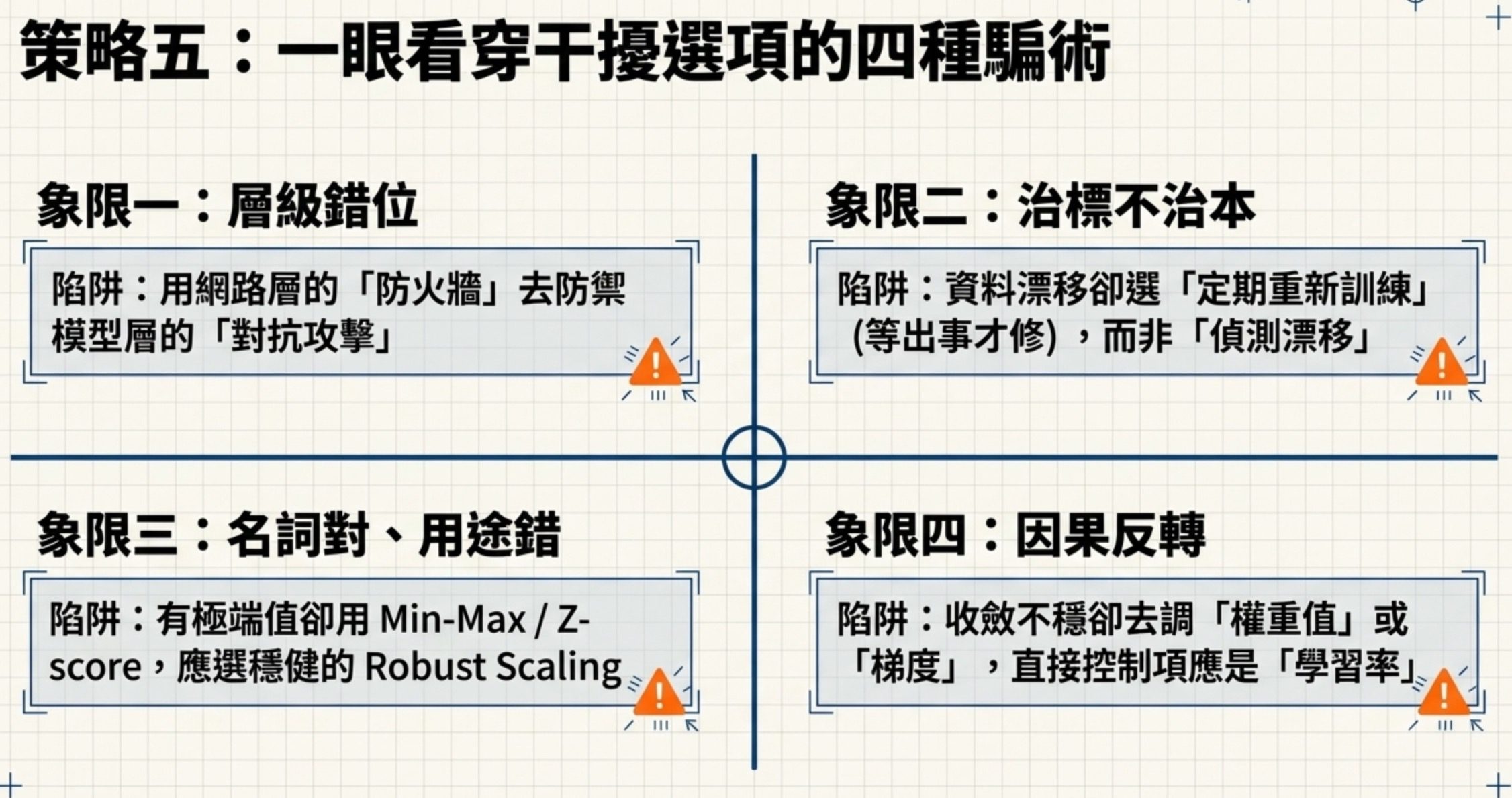
策略五:干擾選項的固定騙術
出題者設計錯誤選項有固定套路,一旦你知道這些套路,就能快速排除:
層級搞錯:有一題問怎麼防禦對抗攻擊(adversarial attack),有個選項是「強化網路防火牆」。防火牆是網路安全層的東西,對抗攻擊是模型層的問題,層級完全不對。科目三有一題問防止過擬合的策略,有個選項是「擴增輸入特徵變數以提升模型表達能力」。增加特徵是增加複雜度,跟防止過擬合方向相反。
治標當治本:前面提到的 Data Drift 題目,有個選項是「定期重新訓練模型」。重新訓練是治標(等問題發生後才修),漂移偵測是監控與預警,重新訓練是可能的處置之一;實務上要先判斷漂移類型,再決定重訓、重新取樣或調整資料流程(在問題擴大前就發現)。
正確名詞但錯誤用途:有一題問資料有極端值時該用什麼標準化方法。Min-Max Scaling 和 Z-score 都是正確的標準化方法,但它們都容易被極端值拉偏。Robust Scaling 用中位數和四分位距,才是對極端值穩健的做法。
因果方向反了:科目三有一題描述深度神經網路訓練時收斂速度不穩定,問該調什麼超參數。選項有 Loss Function 的梯度值、每個神經元輸出、權重值。但收斂速度不穩定的直接控制項是學習率(Learning Rate),不是間接的梯度或權重。
你該怎麼準備:做題時不要只看「哪個是對的」,要同時看「其他三個為什麼是錯的」。每個錯誤選項都有一個出錯模式(層級錯、治標、名詞對但用途錯、因果反了),你要能說出它錯在哪。
三科考的其實是同一批概念
很多人以為三科完全獨立,其實不是。
出題者在三科裡反覆考同一批概念,只是角度不同,搞懂一個概念,可能同時解決三科的題目。
| 跨科概念 | 科目一 | 科目二 | 科目三 | 合計 |
|---|---|---|---|---|
| 過擬合與正則化 | 3 題 | 1 題 | 5 題 | 9 題 |
| 不平衡資料與評估指標 | 2 題 | 3 題 | 3 題 | 8 題 |
| 交叉驗證 | 2 題 | 2 題 | 3 題 | 7 題 |
| 隱私加密與治理 | 3 題 | 3 題 | 2 題 | 8 題 |
| Data Drift 與模型監控 | 3 題 | 0 題 | 1 題 | 4 題 |
| PCA 與降維 | 2 題 | 1 題 | 2 題 | 5 題 |
| DBSCAN | 2 題 | 1 題 | 1 題 | 4 題 |
這代表什麼?如果你真的搞懂「過擬合」這個概念,包含它的成因、症狀、解法、跟欠擬合的差別、跟 Data Drift 的差別,你就同時解決了三科裡至少 9 題。
如果你搞懂「不平衡資料」,包含為什麼不能只看 Accuracy、SMOTE 和 Random Oversampling 的差異、分層交叉驗證的原理,你又解決了 8 題。
150 題看起來很多,但背後可能只有 20 幾個核心概念。
怎麼準備才有用
不是給你「每週讀什麼」的時間表,是告訴你讀考古題時,應該怎麼讀才有效。
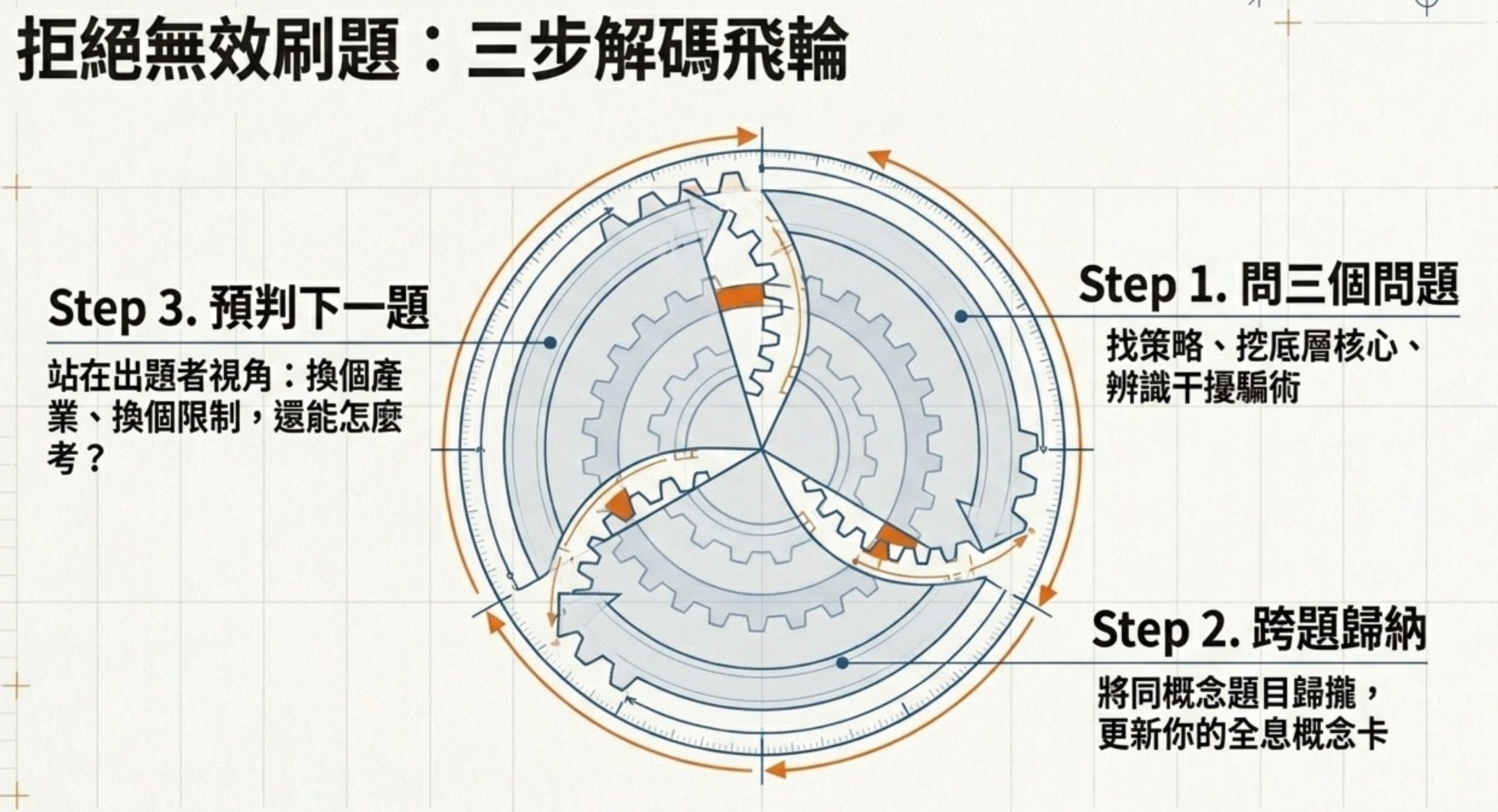
第一步:讀一題就問三個問題
每讀完一題,不要急著看下一題,先問自己:
- 這題用的是哪一種出題策略?(長得像要你分辨?給症狀找病因?工具配情境?流程角色?)
- 它背後真正要測的概念是什麼?(不是題目表面的場景,是底層的概念。)
- 其他三個錯誤選項各錯在哪裡?(層級搞錯?治標?名詞對用途錯?)
如果你能回答這三個問題,這題你就真的搞懂了,不只是記住答案。
第二步:跨題歸納,建立概念卡
讀完一科 50 題後,把考同一個概念的題目放在一起,例如:
概念卡範例:過擬合
- 科目一有一題問超參數調校時怎麼避免過度調參 → 用 Cross-Validation,不要在測試集上反覆調
- 科目一有一題問在交叉驗證資料上同時調參和評估會怎樣 → 造成 Data Leakage,結果過度樂觀
- 科目三有一題問 L1 正則化(Lasso)的主要效果 → 產生稀疏模型,讓部分參數歸零
- 科目三有一題問「哪個不是防過擬合的策略」 → 擴增特徵(那是增加複雜度,方向反了)
- 科目三有一題問 Early Stopping 怎麼設定 → 設 Patience,連續多輪未改善後再停
這樣一張概念卡,你一眼就能看到出題者從哪些角度考過「過擬合」,下次再出,你就知道它可能從哪個角度切入。

第三步:預判下一題
建完概念卡後,問自己:如果我是出題老師,同一個概念我還可以怎麼考?
例如 DBSCAN 已經考過超參數(Epsilon + MinPts)、高維資料效能問題(需要用 KD-Tree / Ball Tree 加速)、雜訊點的定義。那下次可能考什麼?可能考 DBSCAN 跟 K-means 的比較(不需要預設群數 vs 需要)、DBSCAN 在密度不均勻資料上的限制、或者 HDBSCAN。
這個練習的目的不是猜題,而是讓你站在出題者的高度理解概念,當你能從出題者的角度思考,你就不會被題目的表面包裝騙到。
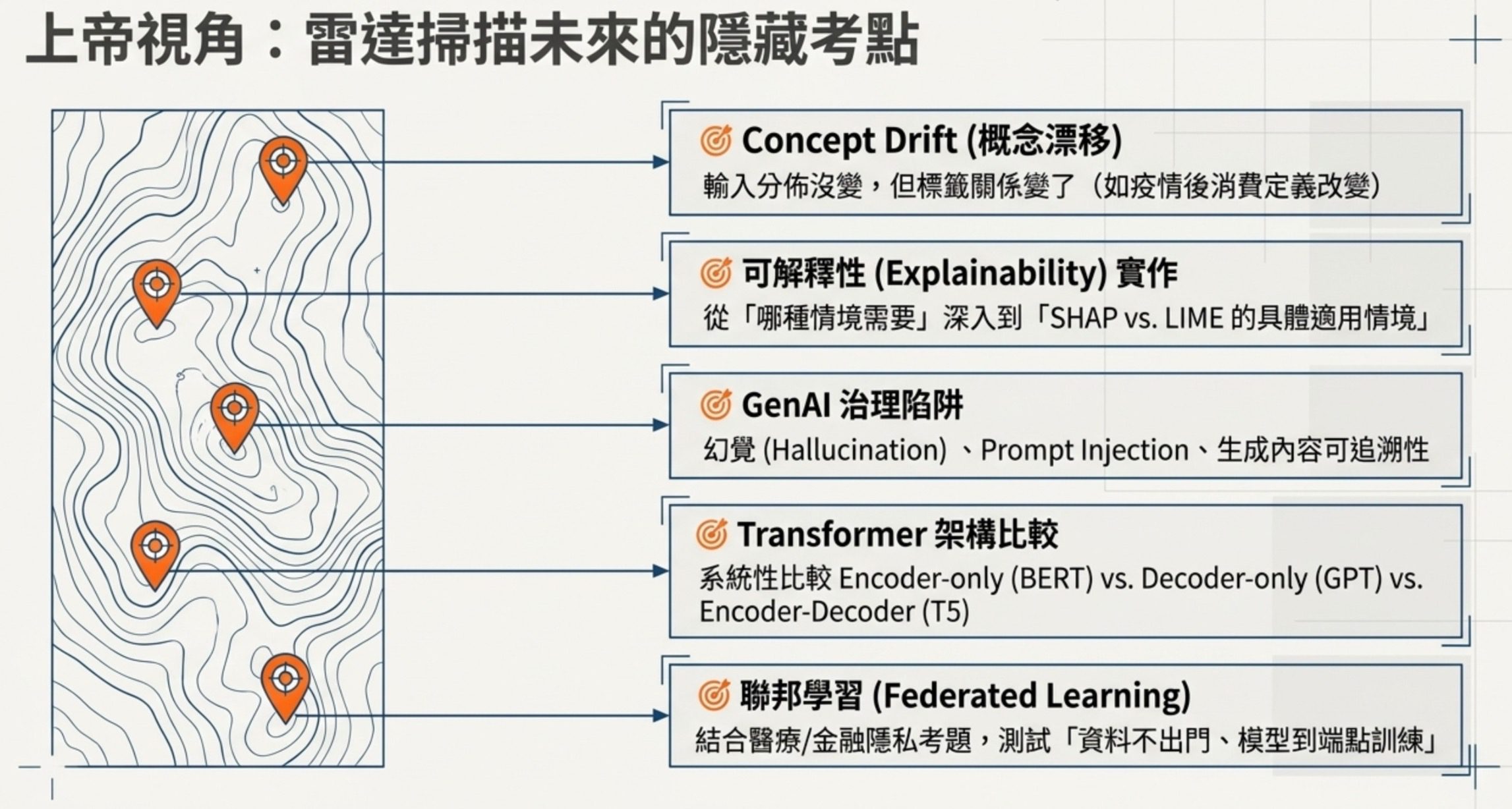
如果我是出題者,下次會怎麼考
基於 150 題的出題模式,以下是出題者很可能但還沒考過的方向:
Concept Drift vs Data Drift:Data Drift 已經考了 4 題,其中一題的正確選項已包含 Concept Drift。但目前還沒有獨立考「Concept Drift 和 Data Drift 的定義差異」。例如:輸入特徵看起來相近,但同樣特徵對應到的結果或決策邊界改變了。例如相同消費頻率、金額與通路,在疫情前後可能代表不同的流失風險或購買意圖。
可解釋性(Explainability)的實作:考古題有問過哪種情境需要可解釋性(答案是醫療診斷),但沒考 SHAP、LIME 這些具體工具。下次很可能考「以下哪種方法最適合解釋某模型的預測」。
生成式 AI 的治理陷阱:考古題考過著作權和隱私問題,但 Hallucination(幻覺)、Prompt Injection、生成內容的可追溯性、AI 生成內容的標示義務,這些都還沒考。
Transformer 架構的細節比較:考古題考了 BERT 的 MLM 訓練策略,但 Encoder-only(BERT)、Decoder-only(GPT)、Encoder-Decoder(T5)三種架構各自適合什麼任務,還沒系統性地比較過。
聯邦學習(Federated Learning):隱私加密已經考了 8 題,同態加密跨科出現 3 次。但聯邦學習(模型到資料端訓練、資料不出門)還沒考,很適合搭配醫療或金融情境出題。
總結:iPAS AI 應用規劃師中級備考技巧
中級考試不是初級加深版,它是一個完全不同的考法,測的是判斷力而不是記憶力。
150 題背後只有 5 種出題策略和大約 20 幾個核心概念,如果你用「背 150 個答案」的方式準備,下次換個場景你就不會了,但如果你搞懂這 20 幾個概念,不管題目怎麼包裝你都能看穿。
接下來三篇會分別深入科目一(AI 技術應用與規劃)、科目二(大數據處理分析與應用)、科目三(機器學習技術與應用),用概念卡的方式把每科的核心概念拆開講清楚。
推薦閱讀
- iPAS AI 應用規劃師中級科目三:機器學習技術與應用 6 大核心命題
- iPAS AI 應用規劃師中級科目一:人工智慧技術應用與規劃 7 大核心命題
- iPAS AI 應用規劃師中級科目二:大數據處理分析與應用 6 大核心命題
參考資料
FAQ
AI 應用規劃師中級和初級的差別是什麼?
最大的差別不是難度,而是考法。初級像在確認你認不認得 AI 名詞,中級像在確認你能不能在真實專案情境裡做判斷。初級問情感分析是什麼,中級會給你一個電商場景,問模型上線後某些族群的判斷結果不一致,最可能的原因是什麼。準備方式也要跟著換:從背名詞變成理解概念之間的差異和適用條件。
中級證書有分方向嗎?三科都要考嗎?
中級獲證分兩個方向:科目一加科目二均達 70 分,取得 AI 應用規劃師(數據分析)證書;科目一加科目三均達 70 分,取得 AI 應用規劃師(機器學習)證書。科目一是共同科目,科目二與科目三對應不同證書方向。備考前先確認自己要走哪條路線,再決定重點科目。
沒考過初級,可以直接準備中級嗎?
可以報考,官方沒有要求先通過初級。但如果你對資料處理、統計、機器學習這些概念完全陌生,建議先用初級的範圍打底。中級仍會考基礎概念,例如交叉驗證的用途、L1 正則化的效果、CNN 卷積層的功能,但通常要求你能在情境比較、模型診斷或流程判斷中使用這些概念,不是單純背定義就夠。
中級三科分別在考什麼?
科目一考你能不能判斷一個 AI 專案該用什麼技術、怎麼部署、怎麼監控。科目二考你能不能正確處理資料:統計判斷、資料清理、Python 分析、視覺化、隱私合規。科目三考你能不能選對模型、評估模型、處理過擬合和不平衡資料。三科看似獨立,但過擬合、交叉驗證、Data Drift、PCA 等核心概念會跨科出現。
中級三科哪一科最難?
多數學生反映科目三最硬,因為同時包含數學基礎、模型選擇、評估指標、調參、深度學習和治理。但科目二的統計推論和 Python 程式碼判讀也不能輕忽。建議不要只押某一科,三科的核心概念高度重疊。
三科要一起讀還是分開讀?
建議先各科讀一遍建立整體地圖,然後跨科歸納。分析 150 題後發現,過擬合跨三科出了 9 題、不平衡資料出了 8 題、交叉驗證出了 7 題、隱私加密出了 8 題。分科讀完就放下會錯過這些重疊。
只刷考古題能考過中級嗎?
只刷題而不整理概念,風險很高。中級出題者會把同一個概念換成不同產業情境重新包裝,例如 Data Drift 就用電商、金融、線上服務三種場景各出了一題。有效的做法是每讀完一題就問三個問題,然後跨題歸納建立概念卡。
中級要準備多久?
如果有初級基礎或相關工作經驗,建議四到六週。沒有基礎的話建議拉到八週以上。重點不是時間長短,而是你有沒有把 150 題背後的 20 幾個核心概念真的搞懂,而不只是記住答案。
中級需要會寫程式嗎?
不需要像工程師一樣寫完整專案,但科目二和科目三都有程式碼判讀題。科目二考 pandas 和 seaborn 語法,科目三考 sklearn、NumPy、PyTorch 或 Keras 的基本操作。你不需要能從頭寫,但要看得懂程式碼在做什麼。
中級需要很強的數學嗎?
不需要推導公式,但要理解常見指標和方法背後的意義。科目二考 Z-score、p 值、信賴區間的情境應用,科目三考 Precision、Recall、F1 的關係和 PCA 特徵值的意義。重點是數字代表什麼和在什麼情境用哪個。
有什麼推薦的準備資源?
最重要的資源是 iPAS 官方公告試題,搭配本文的出題策略分析來讀效果最好。基礎概念不熟的話 Google Machine Learning Crash Course 可以快速補底,Python 資料分析不熟可參考 pandas 和 scikit-learn 官方文件。