![[新手入門] 中級科目二:費曼學習法,7 個故事讓你讀完就懂](https://www.techhanlin.tw/wp-content/uploads/2026/05/ipasl22-3.jpg)
[新手入門] 中級科目二:費曼學習法,7 個故事讓你讀完就懂
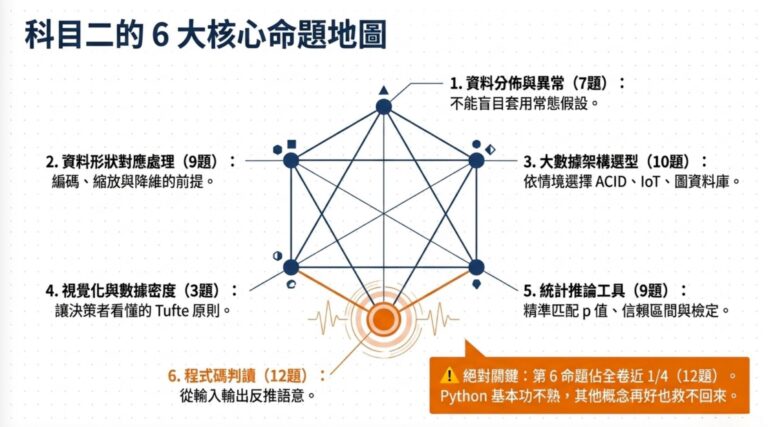
大數據處理分析與應用聽起來很嚇人,但科目二的 50 題拆開來看,核心只在問你 7 件事。
這是白話入門版,用故事帶你讀懂中級科目二(大數據處理分析與應用)。如果你想直接看考點與命題拆解,請看 iPAS AI 應用規劃師中級科目二:大數據處理分析與應用 6 大核心命題。
這篇文章用費曼學習法,把每件事從日常生活講起,讀完你就懂了。
以下內容根據 114 年第二次 AI 應用規劃師中級能力鑑定科目二(大數據處理分析與應用)的 50 題公告試題整理。
想要直接聽可以點 NotebookLM Podcast 連結跳到文章最後面。
故事一:數字會說話
想像你是學校老師,剛改完一百份考卷,你想知道:這次考試難不難?有沒有人考得特別離譜?分數分布長什麼樣?
這些問題的答案都藏在統計量裡,科目二有將近十題在考你對統計量的直覺。
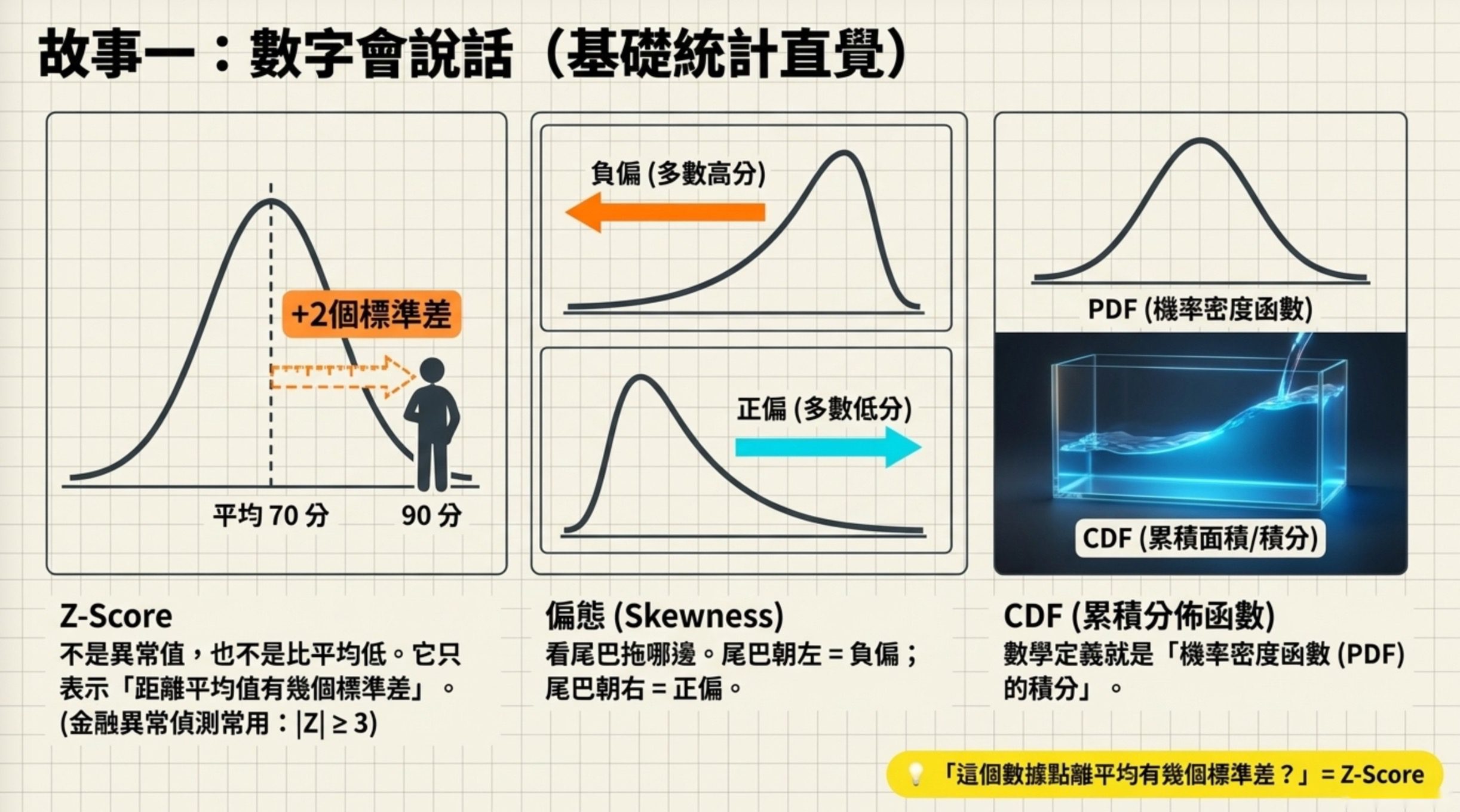
Z-Score:離平均有多遠
班上平均 70 分,標準差 10 分。小明考了 90 分,他的 Z-Score = (90 − 70)/ 10 = 2。意思是:小明的成績比平均值高了 2 個標準差。
Z-Score 不是原始數值、不是說他是異常值、也不是「比平均低」,它只告訴你這個點跟平均值差幾個標準差。
金融業用 Z-Score 抓異常交易。交易金額平均 2,000 元、標準差 400 元,某筆交易 3,200 元,Z = (3,200 − 2,000)/ 400 = 3。如果公司設定 |Z| ≥ 3 為異常,這筆就要標記。
偏態:分布歪向哪邊
考試如果很簡單,大部分人考高分,只有少數人考很低,分布圖會「左邊拖一條長尾巴」。這叫負偏(Skewness < 0),因為尾巴朝左(負的方向)。
反過來,如果考試很難,大部分人分數低、少數人考很高,尾巴朝右,就是正偏(Skewness > 0)。
考試給你一張分布圖,看尾巴往哪邊拖就好。尾巴朝左 = 負偏,尾巴朝右 = 正偏,左右對稱 = Skewness ≈ 0。
CDF:從「某一刻的高度」到「截至目前的面積」
機率密度函數(PDF)告訴你每個數值「有多可能出現」,像是一條山的剖面線。累積分佈函數(CDF)告訴你「截至這個數值,累積了多少機率」。
數學上,CDF 就是 PDF 的積分(面積累加)。考試問「CDF 的數學定義」,答案是「機率密度函數的積分」。不是 PDF 的平均值、也不是標準差。本題是連續型 PDF 情境,所以 CDF 是 PDF 的積分;若是離散型隨機變數,CDF 則用 PMF 累加表示。
Poisson 分佈:數「事件在固定時間內發生幾次」
客服中心平均每小時接 20 通電話,但每分鐘接到幾通不固定(0、1、2 通都有可能)。這些來電彼此獨立、平均發生率固定、在短時間內發生。完美符合 Poisson 分佈的條件。
考試問「描述每分鐘接到幾通來電的機率分佈」,答案是 Poisson。不是均勻分佈(每個值機率一樣)、不是指數分佈(那是描述「兩次事件之間的等待時間」)、不是常態分佈(來電次數是離散的非負整數)。
Poisson 的程式碼長這樣:poisson.pmf(5, lambda_poisson),其中 lambda_poisson = 5。pmf(5, 5) 算的是「平均每小時 5 個瑕疵品的前提下,剛好出現 5 個的機率」。cdf(10, 5) 算的是「出現 10 個以下(含 10 個)」的累積機率。
二項分佈 → 常態近似
廣告推播 5,000 次,每次被點擊的機率 p = 0.4。想知道「總點擊次數」的分佈長什麼樣,這是二項分佈。但 5,000 次太多了,直接算組合數會爆炸。
好消息是:當 np 跟 n(1−p) 都大於 5 時,二項分佈可以用常態分佈近似。5000 × 0.4 = 2000、5000 × 0.6 = 3000,都遠大於 5,所以可以近似。不是「樣本數大就一定可以」(還要看 p),也不是「只適用於 p = 0.5」。
Pearson 相關係數:兩個變數走同一個方向嗎
行銷部門畫散佈圖,發現廣告預算跟銷售金額呈明顯線性趨勢、沒有離群值。想量化這個關係的強度跟方向,用 Pearson 相關係數(值在 −1 到 +1 之間)。
不是 RMSE(那是預測誤差)、不是共變異數(沒有標準化,數值大小無法比較)、不是 MAE(也是誤差指標)。
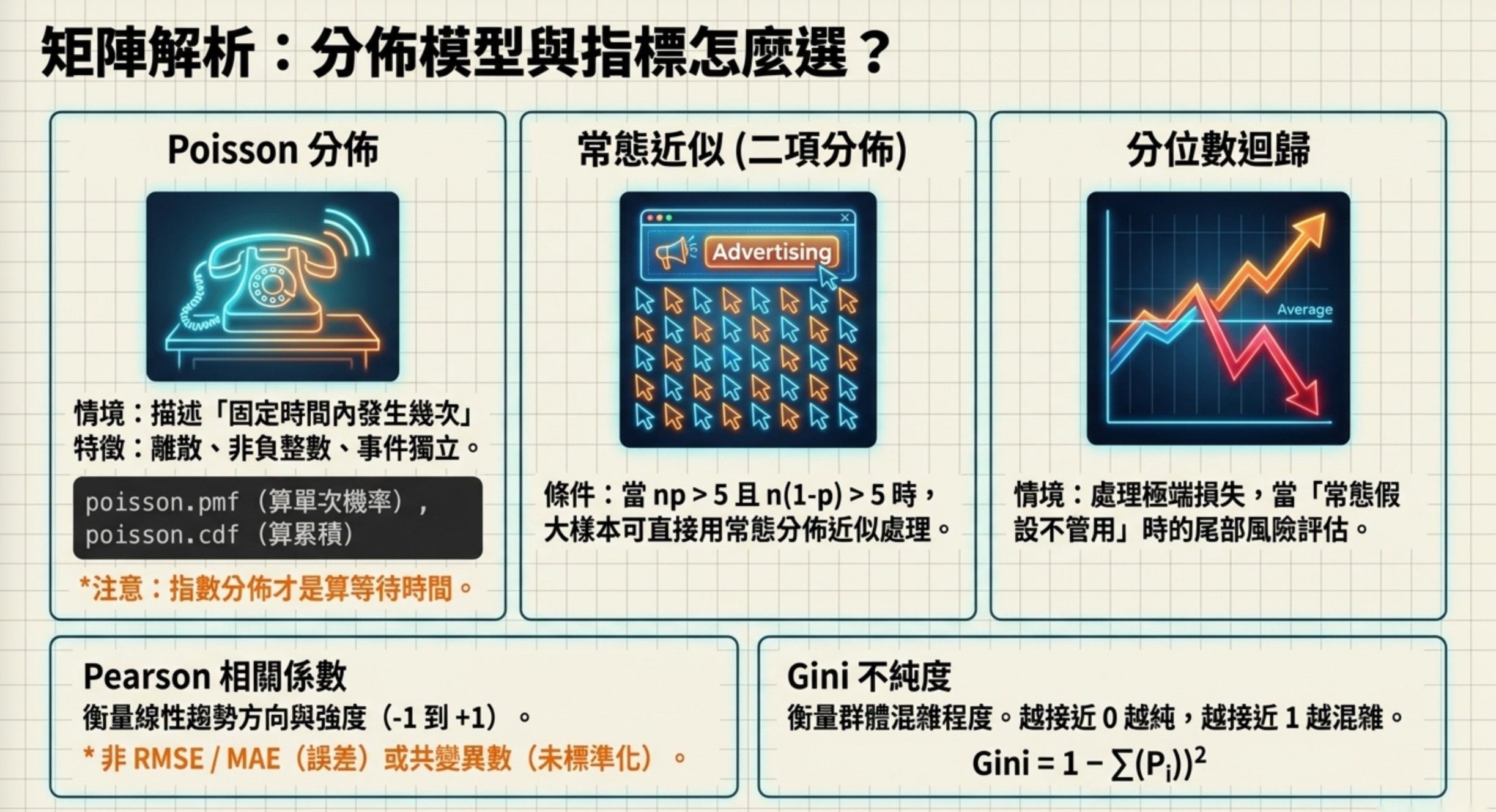
Gini 不純度:這群人有多混雜
官方題目是 10 筆標籤:A、A、A、A、A、B、B、B、B、B。A 有 5 筆,B 有 5 筆。Gini = 1 − (5/10)² − (5/10)² = 1 − 0.25 − 0.25 = 0.5。二分類情境下最大 Gini 也是 0.5,所以 Normalized Gini = 0.5 / 0.5 = 1。
Gini 越接近 0 代表越純(全部是同一類),越接近 1 代表越混雜(5/5 最混雜,所以 Normalized Gini = 1)。決策樹就是靠 Gini 來決定怎麼分裂的。
分位數迴歸:常態假設不管用的時候
金融風險資料的報酬率分佈明顯不對稱、經常出現極端損失事件(肥尾)。傳統線性迴歸假設常態分佈,在這裡不管用。分位數迴歸(Quantile Regression)專門聚焦在尾部分位,能更精準地評估極端風險。
費曼檢查點:你能不能用一句話解釋 Z-Score?(「這個數據點離平均有幾個標準差。」)如果可以,統計直覺這塊你就通了。
故事二:資料要先洗才能用
想像你要做一道菜,買回來的食材有些帶泥巴、有些混了壞掉的、有些大小不一。你不會直接丟進鍋裡,你會先洗、切、分類。資料也一樣:模型再厲害,餵進去的資料沒整理好,結果就是垃圾。

類別型資料怎麼轉數字
模型只吃數字,但你的資料有「會員等級:一般、白金、黑卡」這種文字欄位。怎麼辦?
Label Encoding:把類別直接編成數字,一般 = 0、白金 = 1、黑卡 = 2。簡單,但有陷阱:模型會以為 0 < 1 < 2 有大小順序關係。如果類別之間沒有真正的順序(例如「紅、藍、綠」),模型就會學到錯誤的假順序。這是 Label Encoding 最常見的風險。
One-Hot Encoding:每個類別展開成一個獨立的 0/1 欄位。「一般」= [1,0,0]、「白金」= [0,1,0]、「黑卡」= [0,0,1]。沒有順序問題,但類別很多時欄位會爆炸(高基數問題)。
用 Gradient Boosting Tree 時,如果會員等級只有三種,Label Encoding 可能會讓模型誤判類別之間有順序。這時應特別注意。
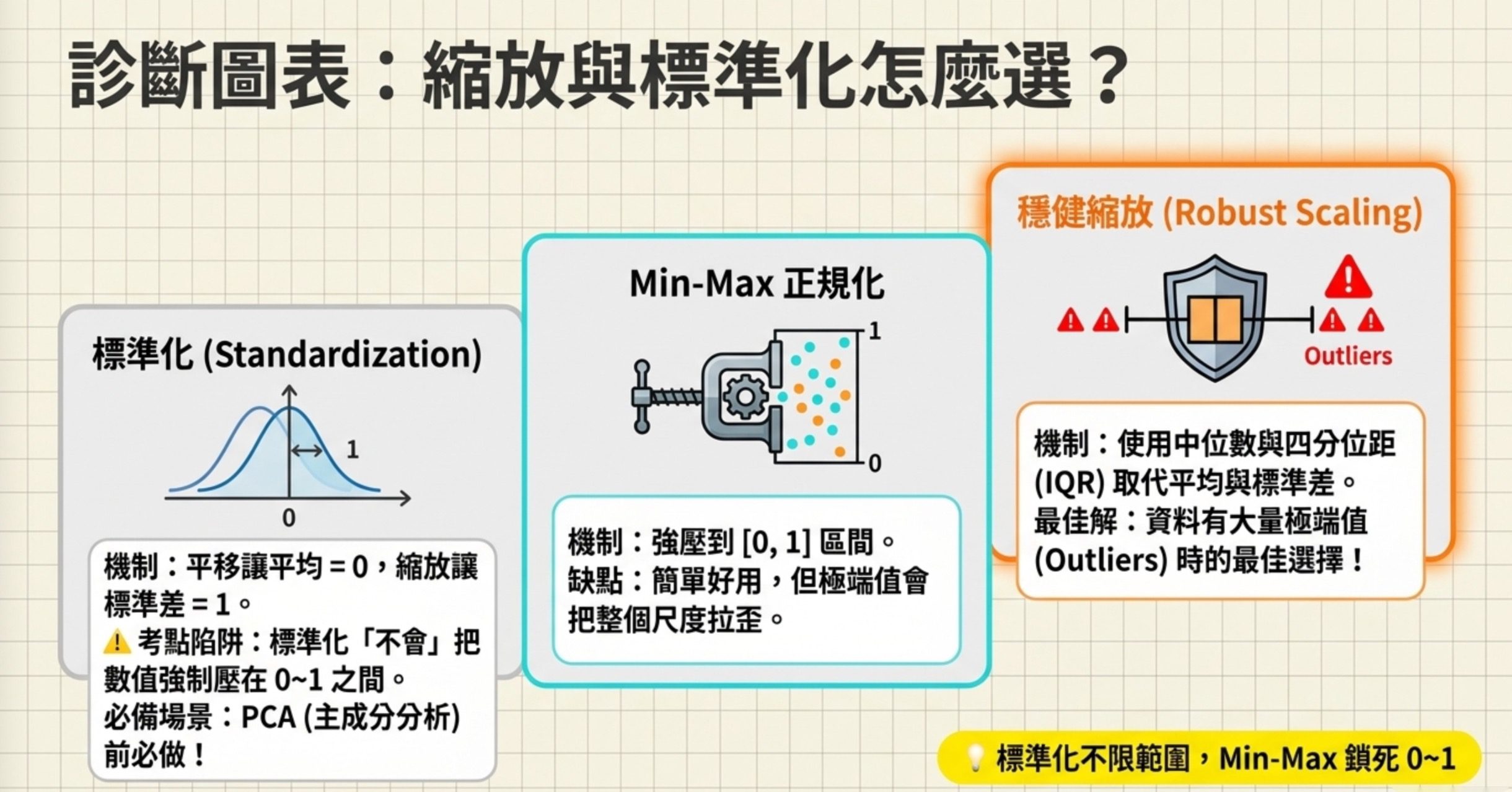
標準化 vs 正規化 vs 穩健縮放
數值型特徵的尺度差很大(薪水幾萬 vs 年齡幾十),需要縮放。三種方法各有適用場景:
標準化(Standardization):平移讓平均值 = 0,縮放讓標準差 = 1。注意:標準化不會把數值壓到 0 到 1 之間,那是 Min-Max 做的事。考試故意在標準化的描述裡混入「數值範圍壓縮至 0 到 1」,那就是錯的。
Min-Max 正規化:把數值線性壓到 [0, 1]。簡單好用,但極端值會把整個尺度拉歪。
穩健縮放(Robust Scaling):用中位數跟四分位距取代平均跟標準差。有極端值時最穩。考試問「有 Outliers 時最適合用哪種標準化」,答案就是 Robust Scaling。
PCA 前一定要先標準化。三個數值欄位的量級差距達 10⁵、10¹、10²,如果不先標準化就丟進 PCA,第一主成分會幾乎完全由量級最大的欄位主導,其他欄位的資訊等於白丟。
特徵衍生:自己造新欄位
現有的欄位是「銷售金額」跟「瀏覽次數」。你把兩個除一下算出「每次瀏覽的平均消費金額」,這個新欄位叫做特徵衍生(Feature Derivation)。不是特徵選擇(那是從現有特徵裡挑重要的)、不是特徵轉換(那是對單一特徵做數學變換)、不是分箱(那是把連續值切段)。
不平衡資料:少數類怎麼處理
罕見疾病資料集只有 1% 陽性。隨機過採樣(Random Oversampling)會直接複製少數類資料,最大風險是增加過擬合:模型只是背下了那些重複的少數類樣本。
SMOTE 更聰明:它在少數類的鄰近樣本之間做內插,造出全新的合成樣本。罕見疾病、標註成本高、短期無法取得更多資料的情境,用 SMOTE 比隨機過採樣更不容易過擬合。
評估不平衡資料的模型時,如果資料集裡 80% 是良性、20% 是惡性,直接用 5-fold 交叉驗證可能讓某些折裡惡性樣本比例更低。分層交叉驗證(Stratified K-Fold)確保每一折的類別比例一致。
迴歸的前處理:Y 不正常時怎麼辦
線性迴歸假設殘差是常態分佈。如果 Y(因變數)明顯右偏、而且變異數隨 X 增大,怎麼辦?對 Y 做 Box-Cox 轉換,能把右偏分佈拉成接近常態。不是標準化 X(那只改自變數尺度)、不是一次差分(那是時間序列用的)、也不是刪掉變異大的樣本。
pandas 處理缺失值
遊戲銷售資料集裡 Year 欄位的型態是 float64 而不是整數。為什麼?因為 CSV 裡 Year 欄位有缺失值(NaN),pandas 會自動把整欄從整數升級為浮點數(因為 NaN 在 pandas 裡是浮點值)。另一個可能是 CSV 裡的年份就含小數點(如 2006.0)。
要轉回整數型態且處理缺失值,正確做法是用 data['Year'].astype('Int64')(大寫 I 的 Int64 是 pandas 的 nullable integer type,能容納 NaN)。不是直接 .astype(int)(NaN 會報錯)、也不是先 fillna(0)(0 年沒意義)或 fillna(1)。
費曼檢查點:你能不能解釋「標準化」跟「Min-Max 正規化」的差異?(標準化讓平均 = 0、標準差 = 1,數值不一定在 0 到 1 之間;Min-Max 把數值壓到 [0,1]。)
故事三:假設檢定,用數據說服人
老闆說「新行銷策略讓月銷售額從 100 萬變成 103 萬」。你心裡想:這 3 萬是真的變好了,還是只是隨機波動?假設檢定就是回答這個問題的工具。
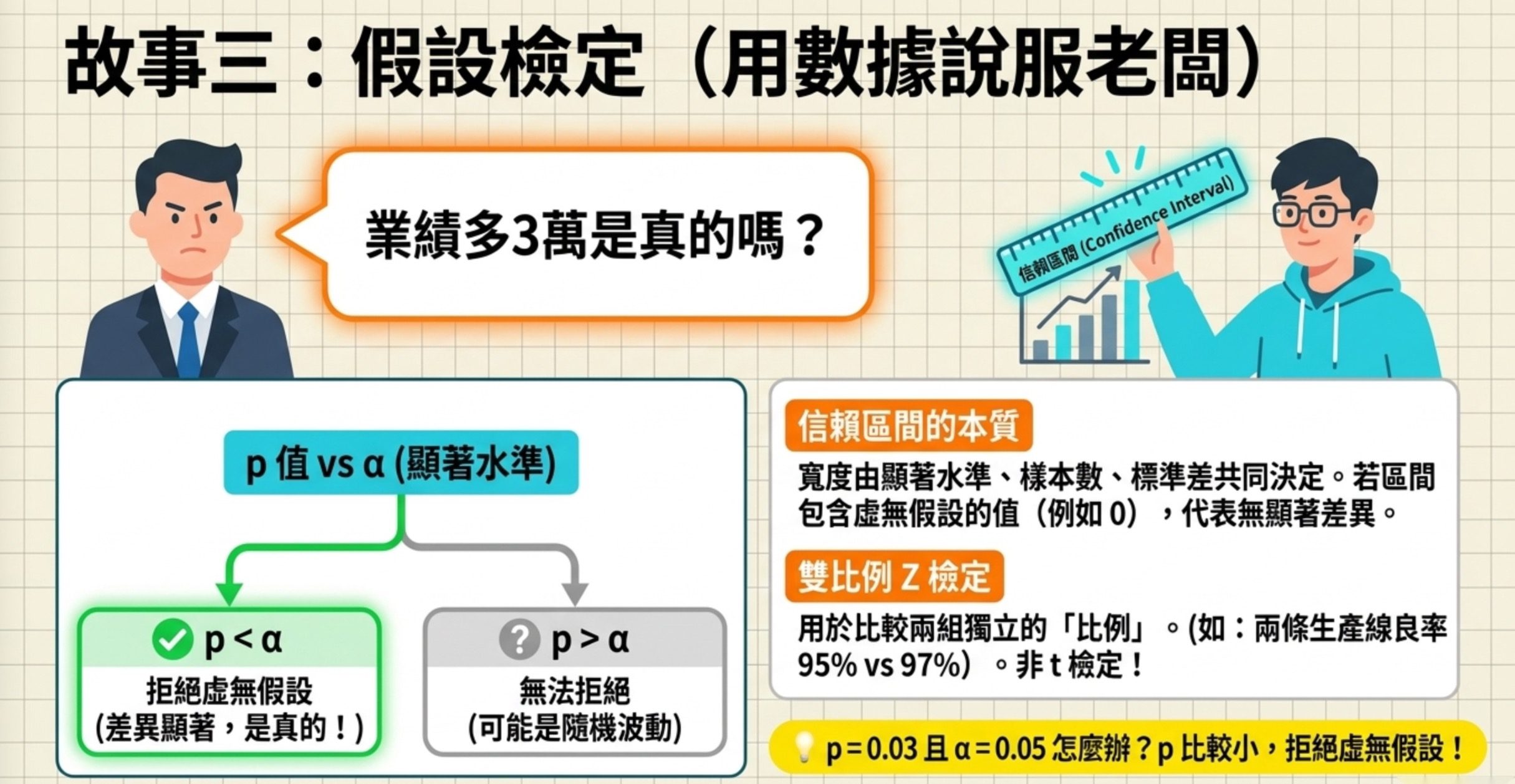
p 值跟信賴區間
單一樣本 t 檢定結果:p = 0.08,95% 信賴區間 [95 萬, 108 萬],顯著水準 α = 0.05。
p = 0.08 > 0.05,所以不能拒絕虛無假設(虛無假設是「銷售額沒變」)。但 100 萬落在信賴區間 [95, 108] 裡面,也支持「無法拒絕」這個結論。
考試常見的陷阱選項:「若顯著水準改為 0.10,仍不顯著」——錯,0.08 < 0.10 就變顯著了。「信賴區間寬度僅與顯著水準有關」——錯,還跟樣本數、標準差有關。
比較兩組比例:雙比例 Z 檢定
原生產線良率 95%、新生產線良率 97%,各抽 100 件。要檢驗差異是否有統計意義。兩個都是比例、兩組獨立樣本,用雙比例 Z 檢定(Two-proportion Z-test)。
不是雙樣本 t 檢定(那是比較兩組平均值,不是比例)、不是卡方檢定(那是多個類別的獨立性)、不是 ANOVA(那是比較三組以上的平均值)。
費曼檢查點:p 值 = 0.03 且 α = 0.05 時,你的結論是什麼?(p < α,拒絕虛無假設,差異有統計顯著性。)
故事四:圖表選對,訊息自己說話
數據分析做得再好,報告裡的圖表選錯了,老闆也看不懂,科目二有好幾題在考「什麼資料配什麼圖」。

資料密度原則:一張圖塞最多資訊
業務績效報告要在一頁裡呈現多區域、多產品線的銷售趨勢。Edward Tufte 的資料密度(Data Density)原則:用顏色區分產品線,在同一張圖裡整合多條趨勢線,保持比例一致且標註清晰。
不是拆成多張獨立圖(資訊分散)、不是移除輔助線跟標籤(看不懂)、也不是改用表格(失去趨勢視覺)。
Heatmap + 相關矩陣
四檔股票的每日報酬率想看彼此的相關性、關聯強度跟方向。用熱力圖(Heatmap)配合相關係數矩陣。
不是每檔各畫直方圖(看不到相關)、不是兩兩畫散佈圖加趨勢線(四檔要畫六張太多)、不是用雙軸折線圖(容易誤導比例)。
離群值太多:用對數刻度
消費金額的箱型圖 IQR 很小但上鬚超長,高金額區域有大量離群值。想依消費層級設計分群策略,最有用的視覺化是以對數刻度繪製箱型圖或長條圖,放大高金額消費族群的變化差異。
不是移除離群值(丟掉高消費客戶的資訊)、不是等距分箱(高低消費混在同一箱)、也不是改成折線圖看時間趨勢(題目不是問時間)。
pandas + matplotlib 圖表程式碼
統計每個遊戲平台的全球銷售總額並畫長條圖:data.groupby("Platform")["Global_Sales"].sum().plot(kind="bar")。
.count() 是算筆數不是加總、.mean() 是算平均不是總額、kind="line" 是折線不是長條。
費曼檢查點:朋友問你「想看四檔股票的相關性用什麼圖」,你能不能 3 秒內回答「Heatmap 配相關矩陣」?
故事五:大數據架構與資料庫
資料不只要分析,還要有地方存、有辦法快速查。科目二有一群題目在考你對資料庫和大數據架構的理解。
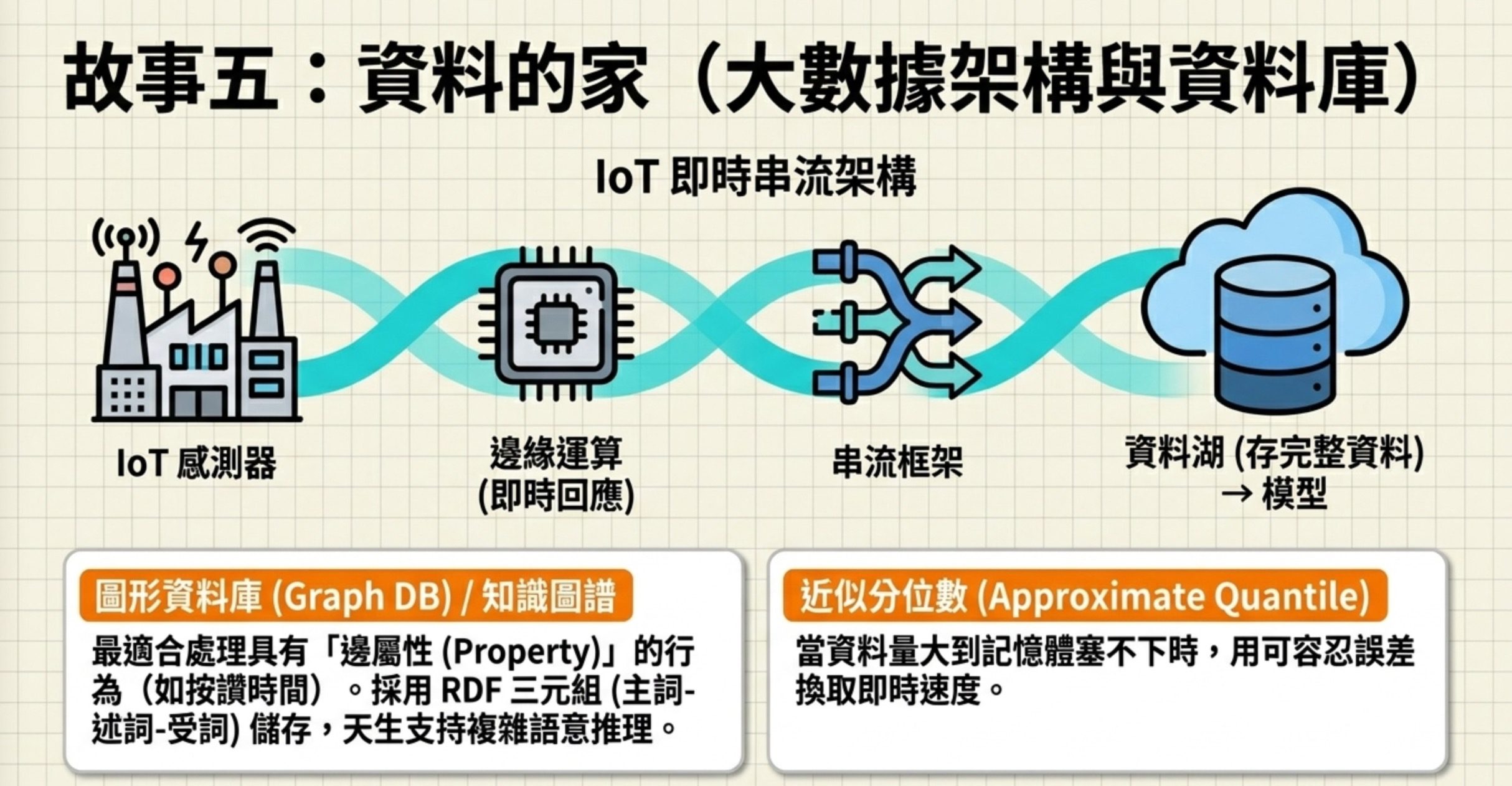
ACID:資料庫的四個保證
想像你在 ATM 轉帳:從 A 帳戶扣 1000 元,存入 B 帳戶。如果扣了 A 但存 B 失敗,你就平白少了 1000 元。
原子性(Atomicity):交易不可分割,要嘛全部成功,要嘛全部回復(Rollback)。這是 ACID 的第一個字母,考試直接問「原子性的正確定義」。
一致性(Consistency):交易完成後資料符合完整性規則。隔離性(Isolation):多筆交易同時進行時互不干擾。持久性(Durability):交易提交後永久保存。
分散式資料庫的情境:某節點交易失敗但系統仍保持資料一致、最終狀態正確。這就是原子性在分散式環境的體現——確保交易全部成功或全部回復。
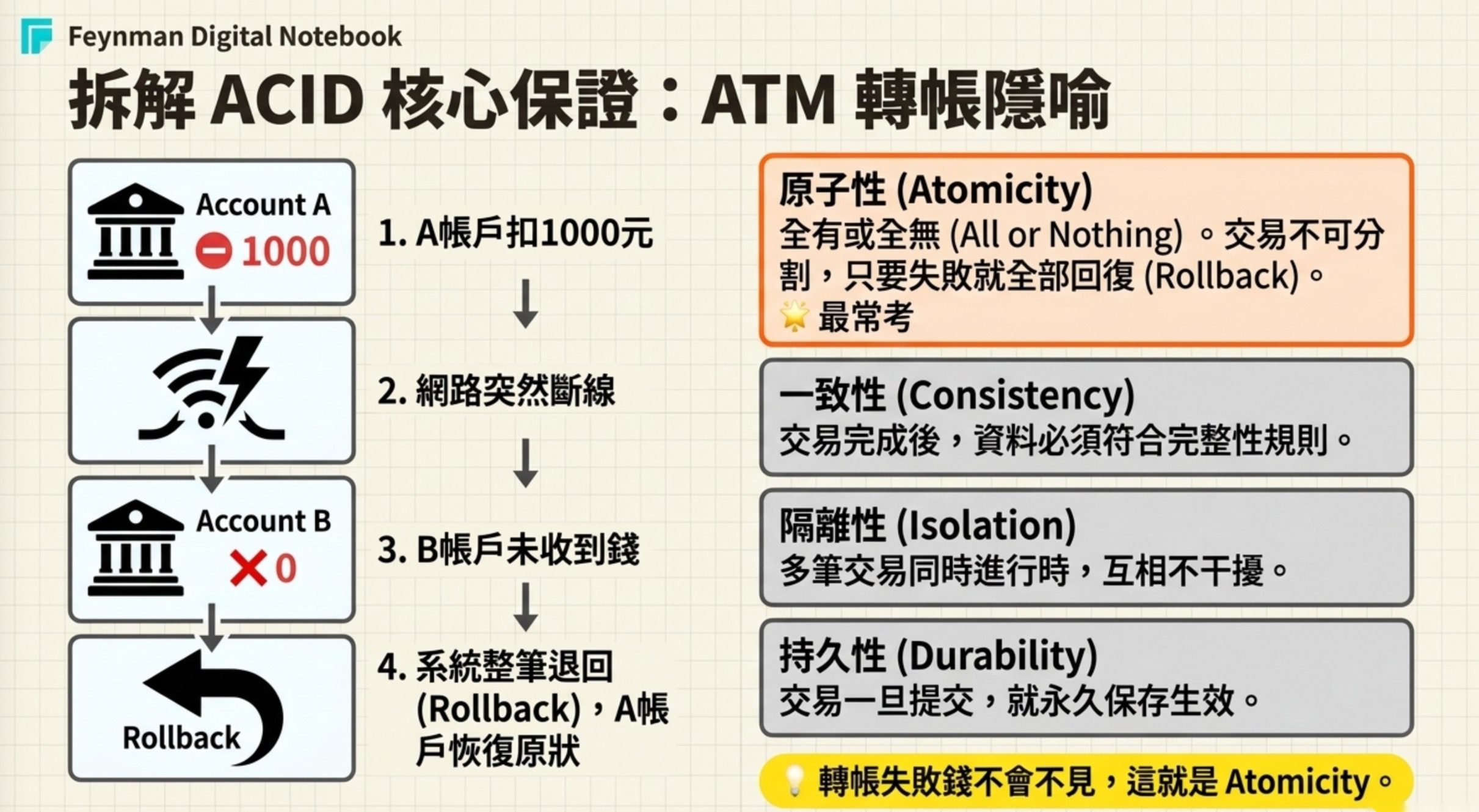
IoT 即時串流架構
工廠有上萬台 IoT 感測器,需要毫秒級回應異常、同時把完整資料存到雲端供 AI 模型訓練。兼顧即時性、資料完整性和可擴展性的架構是:
感測器 → 邊緣運算節點 → 流式資料處理框架(Stream Processing) → 雲端資料湖 → 模型推論
邊緣運算負責即時回應,串流框架處理資料流,資料湖存完整資料。不是走 API Gateway(延遲太高)、不是 MQTT 到即時儀表板(缺持久儲存)、也不是本地快取加 REST API(不可擴展)。
圖形資料庫(Graph Database)
社群平台裡使用者可以按讚貼文,每筆「按讚」行為帶有時間戳記跟裝置類型。想同時保留使用者跟貼文的互動關係,又能有效查詢「按讚」的行為屬性,最適合的設計是把「按讚」資訊作為邊的屬性(Property)儲存,連結使用者與被按讚的貼文節點。
知識圖譜(Knowledge Graph)要整合研究報告、專利、專家知識並支援語意查詢跟關聯推理。最適合的圖模型設計是用 RDF(Resource Description Framework)三元組(Subject-Predicate-Object),因為它天生支持語意推理跟擴展性。
近似分位數:資料量太大的時候
金融公司每天分析上億筆轉帳交易。精確計算分位數要全部排序,資料量大到記憶體放不下。近似分位數(Approximate Quantile)在可容忍的誤差範圍內快速估算分位值,支撐即時分析。
費曼檢查點:你能不能用「轉帳」的例子解釋什麼是 Atomicity?(要嘛 A 扣錢 + B 收錢全成功,要嘛全回復,不能只做一半。)
故事六:程式碼判讀
科目二大約有 10 題是給你 Python 程式碼(或虛擬碼),問你「這在做什麼」或「該怎麼寫」。不需要會寫完整程式,但要能讀懂 pandas、numpy、seaborn、scipy 的基本語法。
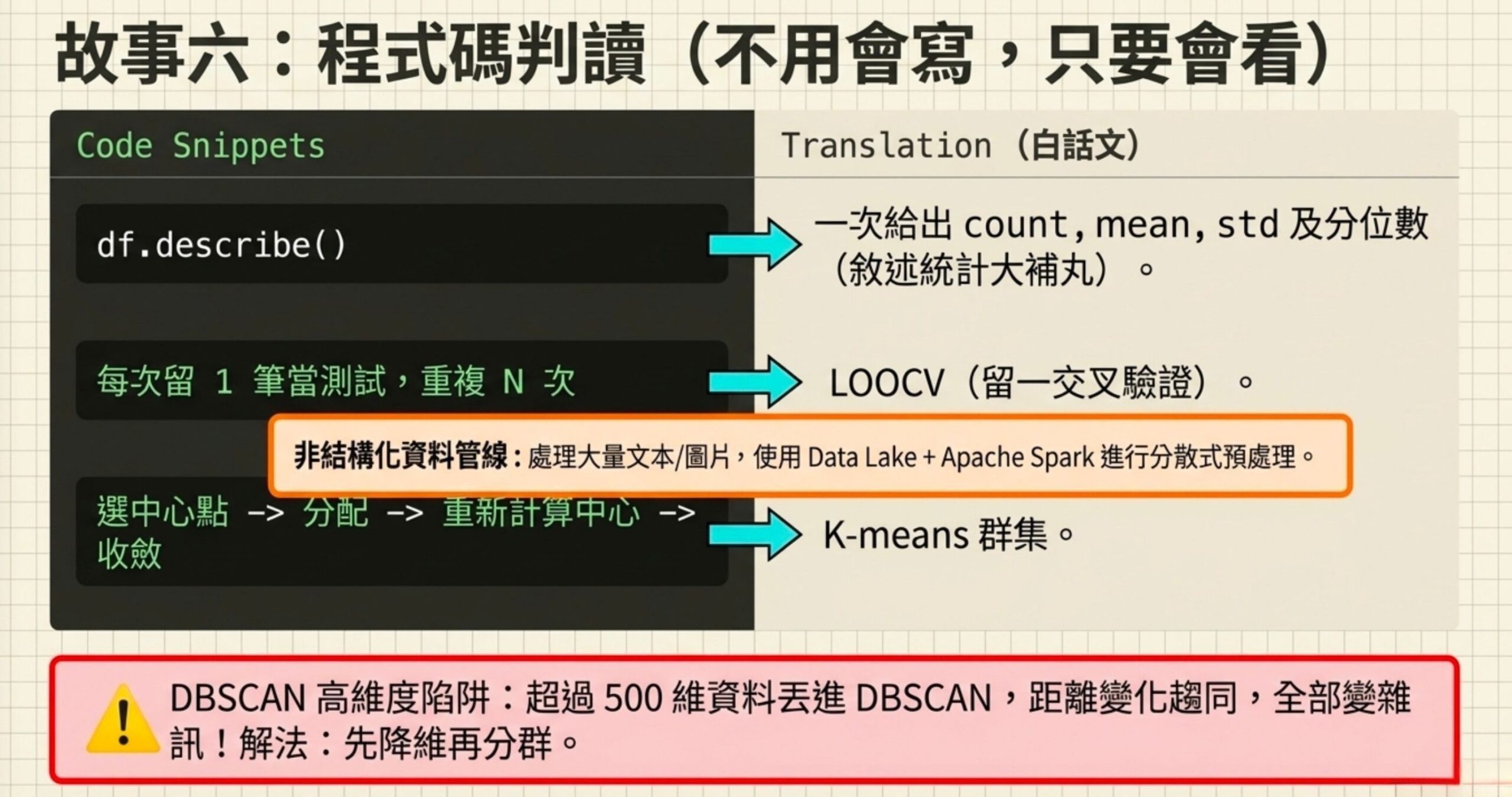
pandas 基本功
df['總銷售額'].describe() 一次給你 count、mean、std、min、25%、50%、75%、max,是最全面的敘述性統計。.sum() 只加總、.sort_values() 只排序、.stats() 不存在。
大量非結構化資料(客服紀錄、產品評論、圖片、表格)要建語言模型,最適合的資料處理策略是建立 Data Lake + Apache Spark 分散式資料預處理與特徵抽取 → 模型訓練 Pipeline。
虛擬碼辨識:LOOCV 跟 K-means
虛擬碼描述:N 筆資料,每次留 1 筆當測試、其他當訓練,重複 N 次取平均。這是留一交叉驗證(LOOCV)。不是 Hold-out(只切一次)、不是 K-fold(分 K 折不是 N 折)、不是 Bootstrap(有放回抽樣)。
虛擬碼描述:隨機選 X 個中心點,重複「分配每筆資料到最近的中心 → 重新計算中心」直到收斂。這是 K-means。不是 GMM(用機率模型)、不是階層式群集(不用中心點迭代)、不是 DBSCAN(不指定群數)。
DBSCAN 在高維度的陷阱
超過 500 維的資料丟進 DBSCAN,結果所有資料點都被判為雜訊。為什麼?高維度下距離變化趨同(所有點之間的距離都差不多),Epsilon 閾值選擇失效。解法不是換距離函數、不是調小 MinPts、也不是過度標準化,而是先降維再分群。
費曼檢查點:看到虛擬碼「每次留 1 筆當測試,重複 N 次」,你能不能 2 秒內說出「這是 LOOCV」?
故事七:隱私與規則
銀行要把信用風險模型部署到雲端,但不想讓雲端服務商看到客戶的原始資料,怎麼辦?

同態加密(Homomorphic Encryption):資料在加密狀態下就能做數學運算,算完解密,結果跟用原始資料算的一模一樣。就像把考卷鎖進透明但不可打開的箱子,閱卷老師隔著箱子也能批改。
不是匿名化(只去欄位不能運算)、不是 Hash(不可逆且不能運算)、也不是資料本地化(不讓資料離開公司但也失去雲端運算的好處)。
生成式 AI 客服系統可能在回答中洩漏訓練資料裡的真實姓名、電話、交易資訊。最符合個資法的做法是訓練前資料匿名化(Anonymization)或偽匿名化(Pseudonymization),並建立輸出內容稽核機制。不是用強化學習微調(不能保證不洩漏)、也不是同態加密所有文字輸入(文字模型的場景不適合)、更不是只靠「不顯示用戶姓名」(那只是表面功夫)。
關聯規則學習:一起買的東西
串流影音平台發現看科幻影集的人有 50% 也看超級英雄電影,Lift = 1.8。Lift > 1 代表這兩個類型之間有正向關聯(不只是巧合)。Confidence = 50% 代表「看了科幻影集的人裡,有一半也看超級英雄電影」,這有明顯的推薦價值。
Support(支持度)= 同時看兩種的佔總觀影紀錄 12%,低不代表沒價值(稀有組合反而有推薦意義)。Lift 大於 1 不代表內容無關、也不是隨機重疊。
費曼檢查點:你能不能用一句話解釋同態加密?(「資料加密了還能做運算,解密後結果正確。」)
總結:7 個故事覆蓋 50 題
| 故事 | 核心問題 | 覆蓋題數 |
|---|---|---|
| 數字會說話 | Z-Score、偏態、CDF、Poisson、Gini | 約 10 題 |
| 資料要先洗才能用 | 編碼、標準化、特徵工程、不平衡 | 約 12 題 |
| 假設檢定 | p 值、信賴區間、Z 檢定 | 約 3 題 |
| 圖表選對 | Heatmap、對數刻度、Data Density | 約 5 題 |
| 資料的家 | ACID、串流架構、Graph DB | 約 6 題 |
| 程式碼判讀 | pandas、LOOCV、K-means、DBSCAN | 約 10 題 |
| 隱私與規則 | 同態加密、匿名化、關聯規則 | 約 4 題 |
考前跑一遍每個故事結尾的費曼檢查點,能用自己的話說出來就代表真的懂了,祝考試順利!

NotebookLM Podcast
推薦閱讀
參考資料
iPAS 經濟部產業人才能力鑑定(2025). AI 應用規劃師中級能力鑑定考試簡章
iPAS 經濟部產業人才能力鑑定(2025). 114 年第二次 AI 應用規劃師中級能力鑑定公告試題|第二科:大數據處理分析與應用
FAQ
科目二最容易搞混的概念有哪些?
六組高混淆概念:標準化 vs Min-Max 正規化(標準化讓平均=0、標準差=1,數值不一定在 0-1 之間;Min-Max 才是壓到 [0,1])、Label Encoding vs One-Hot Encoding(Label 會引入假順序關係,One-Hot 不會但高基數時欄位爆炸)、Poisson vs 指數分佈(Poisson 數「固定時間內發生幾次」,指數分佈描述「兩次事件之間等多久」)、LOOCV vs K-fold(留一筆 vs 留一折)、Pearson 相關 vs 共變異數(Pearson 有標準化可比較強度,共變異數沒有)、ACID 四特性(原子性是全成功或全回復,不是批次執行或型別一致)。
程式碼判讀題不會寫 Python 怎麼辦?
不需要會寫完整程式,只需要能讀懂。考試考的是 pandas 的 describe(一次看所有統計量)、groupby + sum + plot(分組加總畫圖)、fillna + astype(處理缺失值轉型態),以及 scipy.stats 的 poisson.pmf/cdf(算 Poisson 機率)。虛擬碼題則要能辨識 LOOCV(每次留 1 筆測試重複 N 次)跟 K-means(隨機選中心、分配、更新、收斂)的邏輯。考前把這些模式記住就夠了。
假設檢定的題目該怎麼準備?
記住三件事就夠應付科目二的假設檢定題。第一,p 值小於顯著水準(α)就拒絕虛無假設,大於就不能拒絕。第二,信賴區間不包含虛無假設的值就拒絕。第三,改顯著水準可能改變結論(例如 p=0.08 在 α=0.05 時不顯著,但在 α=0.10 時就顯著)。比較兩組比例用雙比例 Z 檢定,比較兩組平均用 t 檢定,比較三組以上用 ANOVA。
考前最後一天怎麼用這篇文章複習?
跑一遍 7 個故事結尾的費曼檢查點,每個問題用自己的話回答。能回答的跳過,卡住的就回去重讀那一段。程式碼題看一下 pandas describe、groupby、Poisson pmf/cdf 的語法。假設檢定記住 p 值跟信賴區間的邏輯關係。全部大約 30 分鐘。
Z-Score 跟標準化有什麼關係?
Z-Score 的公式就是標準化的公式:(數據點 – 平均值) / 標準差。對單一數據點算出來的 Z-Score 告訴你它離平均有幾個標準差(例如 Z=2 代表高於平均 2 個標準差)。對整個欄位做標準化(Standardization)就是把所有值都算 Z-Score,讓欄位的平均變 0、標準差變 1。兩者用的是同一個數學操作,只是應用情境不同。
Poisson 分佈跟指數分佈差在哪裡?
Poisson 數的是「固定時間內事件發生幾次」(離散值:0、1、2、3 次),例如每小時接到幾通客服電話。指數分佈描述的是「兩次事件之間等多久」(連續值),例如上一通電話到下一通電話中間隔幾分鐘。兩者是同一個隨機過程的不同面向。考試看到「每分鐘接到幾通」選 Poisson,看到「等到下一通要多久」選指數分佈。
標準化跟 Min-Max 正規化到底差在哪裡?
標準化(Standardization)讓平均值 = 0、標準差 = 1,數值範圍不固定,可能出現負數或大於 1 的值。Min-Max 正規化把數值線性壓到 [0, 1]。考試最愛的陷阱是在標準化的描述裡混入「數值範圍壓縮至 0 到 1」,那是 Min-Max 的特性,不是標準化。有極端值時建議用穩健縮放(Robust Scaling),用中位數跟四分位距取代平均跟標準差。
ACID 四個特性怎麼快速記住?
用 ATM 轉帳記:原子性(Atomicity)= 扣錢跟存錢要嘛全成功要嘛全回復,不能只做一半。一致性(Consistency)= 轉帳完兩邊餘額加起來不變。隔離性(Isolation)= 你跟別人同時轉帳互不干擾。持久性(Durability)= 轉完就永久記錄,斷電也不會消失。考試最常問原子性的定義,記住「不可分割、全成功或全回復」就不會選錯。
科目二的視覺化題怎麼準備?
記住三組配對:看多變數相關性用 Heatmap 配相關矩陣、看有離群值的分布用對數刻度的箱型圖或長條圖、在一頁裡呈現多趨勢用同一圖多條線(Data Density 原則)。程式碼方面,groupby 加 sum 配 plot(kind=’bar’) 是最常考的 pandas 視覺化語法。不要被花式圖表名稱嚇到,考試考的是「什麼資料配什麼圖」的直覺。
這篇文章覆蓋了全部 50 題的概念嗎?
是的。7 個故事覆蓋了 114 年第二次公告試題全部 50 題的核心概念。每個故事不是逐題拆解,而是把相關概念歸納成連貫的理解線索。例如「數字會說話」一次串起 Z-Score、偏態、CDF、Poisson、二項分佈近似、Pearson 相關、Gini 不純度;「資料要先洗才能用」一次串起 Label Encoding、One-Hot、標準化、SMOTE、Box-Cox、pandas 缺失值處理。